Flink学习笔记:Connectors之kafka
本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程:
Flink大数据项目实战:http://t.cn/EJtKhaz
1. Kafka-connector概述及FlinkKafkaConsumer(kafka source)
1.1回顾kafka
1.最初由Linkedin 开发的分布式消息中间件现已成为Apache顶级项目

2.面向大数据
3.基本概念:
1.Broker
2.Topic
3.Partition
4.Producer
5.Consumer
6.Consumer Group
7.Offset( 生产offset , 消费offset , offset lag)
1.2引入依赖
Flink读取kafka数据需要通过maven引入依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.8_2.11</artifactId>
<version>1.6.2</version>
</dependency>

1.3Flink KafkaConsumer
Flink KafkaConsumer目前已经出现了4个大的版本:FlinkKafkaConsumer08、FlinkKafkaConsumer09、FlinkKafkaConsumer10和FlinkKafkaConsumer11.
FlinkKafkaConsumer08和FlinkKafkaConsumer09都继承FlinkKafkaConsumerBase,FlinkKafkaConsumerBase内部实现了CheckpointFunction接口和继承RichParallelSourceFunction类。
FlinkKafkaConsumer11继承FlinkKafkaConsumer10,FlinkKafkaConsumer10继承FlinkKafkaConsumer09。FlinkKafkaConsumer081和FlinkKafkaConsumer082继承FlinkKafkaConsumer08。

1.4 FlinkKafkaConsumer010
FlinkKafkaConsumer010(String topic, DeserializationSchema<T> valueDeserializer, Properties props)
FlinkKafkaConsumer010(String topic, KeyedDeserializationSchema<T> deserializer, Properties props)
FlinkKafkaConsumer010(List<String> topics, DeserializationSchema<T> deserializer, Properties props)
FlinkKafkaConsumer010(List<String> topics, KeyedDeserializationSchema<T> deserializer, Properties props)
FlinkKafkaConsumer010(Pattern subscriptionPattern, KeyedDeserializationSchema<T> deserializer, Properties props)
三个构造参数:
1.要消费的topic(topic name / topic names/正表达式)
2.DeserializationSchema / KeyedDeserializationSchema(反序列化Kafka中的数据)
3.Kafka consumer的属性,其中三个属性必须提供:
a)bootstrap.servers (逗号分隔的Kafka broker列表)
b)zookeeper.connect (逗号分隔的Zookeeper server列表) (仅Kafka 0.8需要)
c)group.id(consumer group id)
1.5反序列化Schema类型
作用:对kafka里获取的二进制数据进行反序列化
FlinkKafkaConsumer需要知道如何将Kafka中的二进制数据转换成Java/Scala对象,DeserializationSchema定义了该转换模式,通过T deserialize(byte[] message)
FlinkKafkaConsumer从kafka获取的每条消息都会通过DeserializationSchema的T deserialize(byte[] message)反序列化处理
反序列化Schema类型(接口):
1.DeserializationSchema(只反序列化value)
2.KeyedDeserializationSchema
1.6 DeserializationSchema接口

1.7 KeyedDeserializationSchema接口

1.8常见反序列化Schema
SimpleStringSchema
JSONDeserializationSchema / JSONKeyValueDeserializationSchema
TypeInformationSerializationSchema/ TypeInformationKeyValueSerializationSchema(适合读写均是flink的场景)
AvroDeserializationSchema
1.9 FlinkKafkaConsumer010最简样版代码

1.10 FlinkKafkaConsumer消费模式设置(影响从哪里开始消费)
设置FlinkKafkaConsumer消费模式示例代码如下所示:

不同消费模式的解释如下所示:
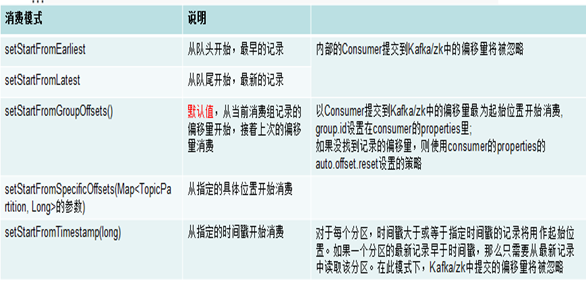
注意1:kafka 0.8版本, consumer提交偏移量到zookeeper,后续版本提交到kafka(一个特殊的topic: __consumer_offsets)
注意2:当作业从故障中恢复或者从savepoint还原时,上述设置的消费策略将不能决定开始消费的位置,真正的起始位置由保存点或检查点中存储的偏移量。
1.11理解FlinkKafkaSource的容错性(影响消费起始位置)

如果Flink启用了检查点,Flink Kafka Consumer将会周期性的checkpoint其Kafka偏移量到快照。
通过实现CheckpointedFunction。
ListState<Tuple2<KafkaTopicPartition, Long>> 。
保证仅一次消费。
如果作业失败,Flink将流程序恢复到最新检查点的状态,并从检查点中存储的偏移量开始重新消费Kafka中的记录。(此时前面所讲的消费策略就不能决定消费起始位置了,因为出故障了)。
1.12 Flink Kafka Consumer Offset提交行为
Flink Kafka Consumer Offset提交行为分为以下两种:

1.13不同情况下消费起始位置的分析

1.14动态Partition discovery
Flink Kafka Consumer支持动态发现Kafka分区,且能保证exactly-once。
默认禁止动态发现分区,把flink.partition-discovery.interval-millis设置大于0即可启用:
properties.setProperty(“flink.partition-discovery.interval-millis”, “30000”)
1.15动态Topic discovery
Flink Kafka Consumer支持动态发现Kafka Topic,仅限通过正则表达式指定topic的方式。
默认禁止动态发现分区,把flink.partition-discovery.interval-millis设置大于0即可启用。

2. FlinkKafkaProducer(kafka sink)
2.1 Flink KafkaProducer
FlinkKafkaProducerBase实现CheckpointFunction接口实现容错,同时也继承了RichSinkFunction类。FinkKafkaProducer08继承FlinkKafkaProducerBase。FinkKafkaProducer09继承FlinkKafkaProducerBase,FinkKafkaProducer10继承FinkKafkaProducer09.
FinkKafkaProducer011已经支持事务,它继承TowPhaseCommitSinkFunction。TowPhaseCommitSinkFunction继承RichSinkFunction。

2.2FlinkKafkaProducer
FlinkKafkaProducer包含了如下不同的构造方法:
FlinkKafkaProducer010(String brokerList, String topicId, SerializationSchema<T> serializationSchema)
FlinkKafkaProducer010(String topicId, SerializationSchema<T> serializationSchema, Properties producerConfig)
FlinkKafkaProducer010(String brokerList, String topicId, KeyedSerializationSchema<T> serializationSchema)
FlinkKafkaProducer010(String topicId, KeyedSerializationSchema<T> serializationSchema, Properties producerConfig)
FlinkKafkaProducer010(String topicId,SerializationSchema<T> serializationSchema,Properties producerConfig,@Nullable FlinkKafkaPartitioner<T> customPartitioner)
FlinkKafkaProducer010(String topicId,KeyedSerializationSchema<T> serializationSchema,Properties producerConfig,@Nullable FlinkKafkaPartitioner<T> customPartitioner)
Value序列化接口SerializationSchema,如果实现这个接口就需要实现如下方法:
byte[] serialize(T element);
如果key也需要实现序列化,则需要实现序列化接口KeyedSerializationSchema,然后重新如下方法:
byte[] serializeKey(T element);
byte[] serializeValue(T element);
String getTargetTopic(T element)
2.3常见序列化Schema
常见的序列化Schema:
1.TypeInformationSerializationSchema/ TypeInformationKeyValueSerializationSchema(适合读写均是flink的场景)
2.SimpleStringSchema
2.4 producerConfig
FlinkKafkaProducer内部KafkaProducer的配置,具体配置可以参考官网地址:
https://kafka.apache.org/documentation.html
2.5 FlinkKafkaPartitioner
默认使用FlinkFixedPartitioner,即每个subtask的数据写到同一个Kafka partition中。
自定义分区器:继承FlinkKafkaPartitioner(partitioner的状态在job失败时会丢失,不会checkpoint)。
2.6 FlinkKafkaProducer容错


Flink学习笔记:Connectors之kafka的更多相关文章
- Apache Flink学习笔记
Apache Flink学习笔记 简介 大数据的计算引擎分为4代 第一代:Hadoop承载的MapReduce.它将计算分为两个阶段,分别为Map和Reduce.对于上层应用来说,就要想办法去拆分算法 ...
- Flink学习笔记:Connectors概述
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- flink学习笔记-数据源(DataSource)
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记:Flink开发环境搭建
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记:DataSream API
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Operators串烧
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Time的故事
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记-各种Time
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
随机推荐
- How To Install Git on CentOS 7
Introduction Version control has become an indispensable tool in modern software development. Versio ...
- linux下的定时或计时操作(gettimeofday等的用法,秒,微妙,纳秒(转载)
一.用select()函数实现非阻塞时的等待时间,用到结构体struct timeval {},这里就不多说了. 二.用gettimeofday()可获得微妙级(0.000001秒)的系统时间,调用两 ...
- JS中日期处理
- js格式化时间和时间操作
js格式化时间 function formatDateTime(inputTime) { var date = new Date(inputTime); var y = date.getFullYea ...
- Spring总结一:Srping快速入门
Sping是什么: Spring是一个开放源代码的设计层面框架,他解决的是业务逻辑层和其他各层的松耦合问题,因此它将面向接口的编程思想贯穿整个系统应用.Spring是于2003 年兴起的一个轻量级的J ...
- ionic中的后退方法
1)$ionicHistory.goBack(); 2)$ionicNavBarDelegate.back(); 个人感觉: 1)$ionicHistory.goBack()会按照html历史来后退 ...
- Nginx配置之基于域名的虚拟主机
1.配置好DNS解析 大家好,今天我给大家讲解下在Linux系统下DNS服务器的基本架设,正向解析,反向解析,负载均衡,还有从域以及一个服务器两个域或者多个域的情况. 实验环境介绍:1.RHEL5.1 ...
- c++ 装饰模式(decorate)
装饰模式:动态地给一个对象添加一些额外的职责.就增加功能来说,装饰模式相比生成子类 更为灵活.有时我们希望给某个对象而不是整个类添加一些功能.比如有一个手机,允许你为手机添加特性,比如增加挂件.屏幕贴 ...
- SQL CLR学习
SQL CLR (SQL Common Language Runtime) 是自 SQL Server 2005 才出现的新功能,它将.NET Framework中的CLR服务注入到 SQL Serv ...
- c语言实践 打印数字三角形
效果如下图: 思路就是外层循环控制要打印的行数,里层循环控制每行打印的数字个数. int val = 65; for (int i = 0; i < 6; i++) { for (int j = ...