Hadoop2.6.5集群搭建
一、 Hadoop的分布式模型
Hadoop通常有三种运行模式:本地(独立)模式、伪分布式(Pseudo-distributed)模式和完全分布式(Fully distributed)模式。
安装完成后,Hadoop的默认配置即为本地模式,此时Hadoop使用本地文件系统而非分布式文件系统,而且其也不会启动任何Hadoop守护进程,Map和Reduce任务都作为同一进程的不同部分来执行。
因此,本地模式下的Hadoop仅运行于本机。此模式仅用于开发或调试MapReduce应用程序但却避免了复杂的后续操作。伪分布式模式下,Hadoop将所有进程运行于同一台主机上,但此时Hadoop将使用分布式文件系统,而且各jobs也是由JobTracker服务管理的独立进程。
同时,由于伪分布式的Hadoop集群只有一个节点,因此HDFS的块复制将限制为单个副本,其secondary-master和slave也都将运行于本地主机。此种模式除了并非真正意义的分布式之外,其程序执行逻辑完全类似于完全分布式,因此,常用于开发人员测试程序执行。要真正发挥Hadoop的威力,就得使用完全分布式模式。
由于ZooKeeper实现高可用等依赖于奇数法定数目(an odd-numbered quorum),因此,完全分布式环境需要至少三个节点
二、环境准备
1.部署环境

2.域名解析和关闭防火墙 (所有机器上)
/etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
:: localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.250 master
192.168.1.249 slave1
192.168.1.248 slave2 关闭 selinux
sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/sysconfig/selinux
setenforce 关闭 iptables
service iptables stop
chkconfig iptables off
3.同步时间,配置yum和epel源
4.配置所有机器ssh互信
三、安装jdk和配置环境变量(三台同样配置)
[root@master ~]# rpm -ivh jdk-8u25-linux-x64.rpm #安装jdk
Preparing... ########################################### [%]
:jdk1..0_25 ########################################### [%]
Unpacking JAR files...
rt.jar...
jsse.jar...
charsets.jar...
tools.jar...
localedata.jar...
jfxrt.jar...
[root@master ~]# cat /etc/profile.d/java.sh #设置java环境变量
export JAVA_HOME=/usr/java/latest
export CLASSPATH=$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
[root@master ~]# . /etc/profile.d/java.sh
[root@master ~]# java -version #查看java变量是否配置成功
java version "1.8.0_25"
Java(TM) SE Runtime Environment (build 1.8.0_25-b17)
Java HotSpot(TM) -Bit Server VM (build 25.25-b02, mixed mode)
[root@master ~]# echo $JAVA_HOME
/usr/java/latest
[root@master ~]# echo $CLASSPATH
/usr/java/latest/lib/tools.jar
[root@master ~]# echo $PATH
/usr/java/latest/bin:/usr/lib64/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
四、安装并配置hadoop
1.安装Hadoop并配置环境变量(master上)
[root@master ~]# tar xf hadoop-2.6..tar.gz -C /usr/local
[root@master ~]# cd /usr/local
[root@master local]# ln -sv hadoop-2.6. hadoop
"hadoop" -> "hadoop-2.6.5"
[root@master local]# ll
[root@master local]# cat /etc/profile.d/hadoop.sh
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@master local]# . /etc/profile.d/hadoop.sh
2.修改以下配置文件(所有文件均位于/usr/local/hadoop/etc/hadoop路径下)
hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/usr/java/latest #将JAVA_HOME改为固定路径
core-site.xml
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/Hadoop/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- 设置namenode的http通讯地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:</value>
</property>
<!-- 设置secondarynamenode的http通讯地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:</value>
</property>
<!-- 设置namenode存放的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/Hadoop/name</value>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value></value>
</property>
<!-- 设置datanode存放的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/Hadoop/data</value>
</property>
</configuration>
mapred-site.xml
[root@master hadoop]# mv mapred-site.xml.template mapred-site.xml
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- 设置 resourcemanager 在哪个节点-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property> <!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
masters
slave1 #这里指定的是secondary namenode 的主机
slaves
slave1
slave2
创建相关目录
[root@master local]#mkdir -pv /Hadoop/{data,name,tmp}
3.复制Hadoop安装目录及环境配置文件到其他主机
master上:
[root@master local]# scp -r hadoop-2.6. slave1:/usr/local/
[root@master local]# scp -r hadoop-2.6. slave:/usr/local/ [root@master local]# scp -r /etc/profile.d/hadoop.sh salve1:/etc/profile.d/
[root@master local]# scp -r /etc/profile.d/hadoop.sh salve2:/etc/profile.d/ slave上(另一台相同操作)
[root@slave1 ~]# cd /usr/local
[root@slave1 local]# ln -sv hadoop-2.6. hadoop
"hadoop" -> "hadoop-2.6.5"
[root@slave1 local]# . /etc/profile.d/hadoop.sh
五、启动Hadoop
1.格式化名称节点(master)
[root@master local]# hdfs namenode -format
// :: INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = master/192.168.1.250
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.6.5
.............................................
.............................................
.............................................
18/03/28 16:34:23 INFO common.Storage: Storage directory /Hadoop/name has been successfully formatted. #这行信息表明对应的存储已经格式化成功。
18/03/28 16:34:23 INFO namenode.FSImageFormatProtobuf: Saving image file /Hadoop/name/current/fsimage.ckpt_0000000000000000000 using no compression
18/03/28 16:34:24 INFO namenode.FSImageFormatProtobuf: Image file /Hadoop/name/current/fsimage.ckpt_0000000000000000000 of size 321 bytes saved in 0 seconds.
18/03/28 16:34:24 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
18/03/28 16:34:24 INFO util.ExitUtil: Exiting with status 0
18/03/28 16:34:24 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/192.168.1.250
************************************************************/
2.启动dfs及yarn
[root@master local]# cd hadoop/sbin/
[root@master sbin]# start-dfs.sh
[root@master sbin]# start-yarn.sh
注:其余主机操作相同
查看结果
master上
[root@master sbin]# jps|grep -v Jps
ResourceManager
NameNode slave1上
[root@slave1 ~]# jps|grep -v Jps
DataNode
NodeManager
SecondaryNameNode slave2上
[root@slave2 ~]# jps|grep -v Jps
NodeManager
DataNode
六、测试
1.查看集群状态
[root@master sbin]# hdfs dfsadmin -report
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Configured Capacity: (28.59 GB)
Present Capacity: (20.72 GB)
DFS Remaining: (20.72 GB)
DFS Used: ( KB)
DFS Used%: 0.00%
Under replicated blocks:
Blocks with corrupt replicas:
Missing blocks: -------------------------------------------------
Live datanodes (): Name: 192.168.1.249: (slave1)
Hostname: slave1
Decommission Status : Normal
Configured Capacity: (14.29 GB)
DFS Used: ( KB)
Non DFS Used: (3.96 GB)
DFS Remaining: (10.34 GB)
DFS Used%: 0.00%
DFS Remaining%: 72.32%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Wed Mar :: CST Name: 192.168.1.248: (slave2)
Hostname: slave2
Decommission Status : Normal
Configured Capacity: (14.29 GB)
DFS Used: ( KB)
Non DFS Used: (3.91 GB)
DFS Remaining: (10.39 GB)
DFS Used%: 0.00%
DFS Remaining%: 72.66%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Wed Mar :: CST
2.测试YARN
可以访问YARN的管理界面,验证YARN,如下图所示:
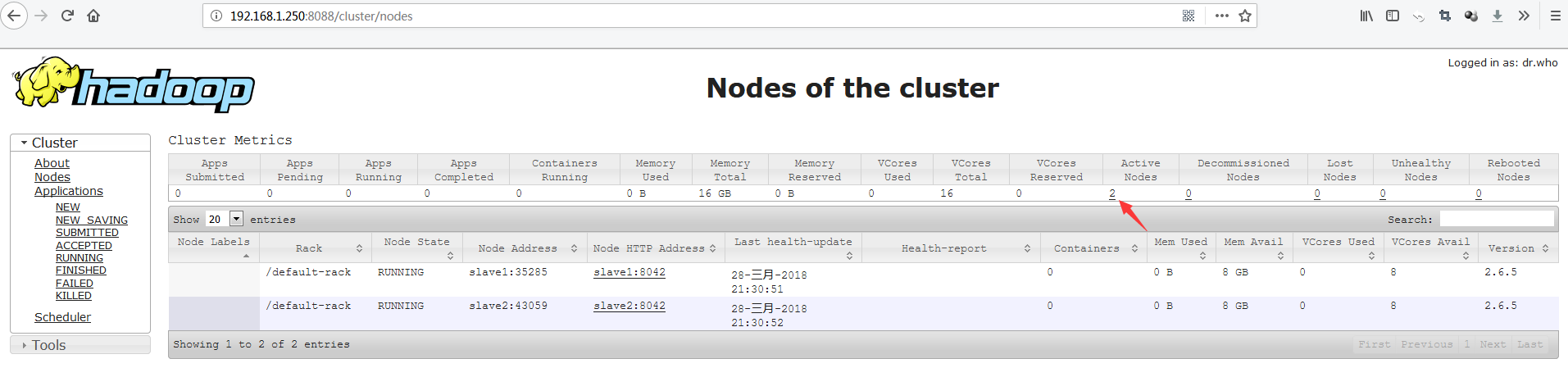
3. 测试查看HDFS
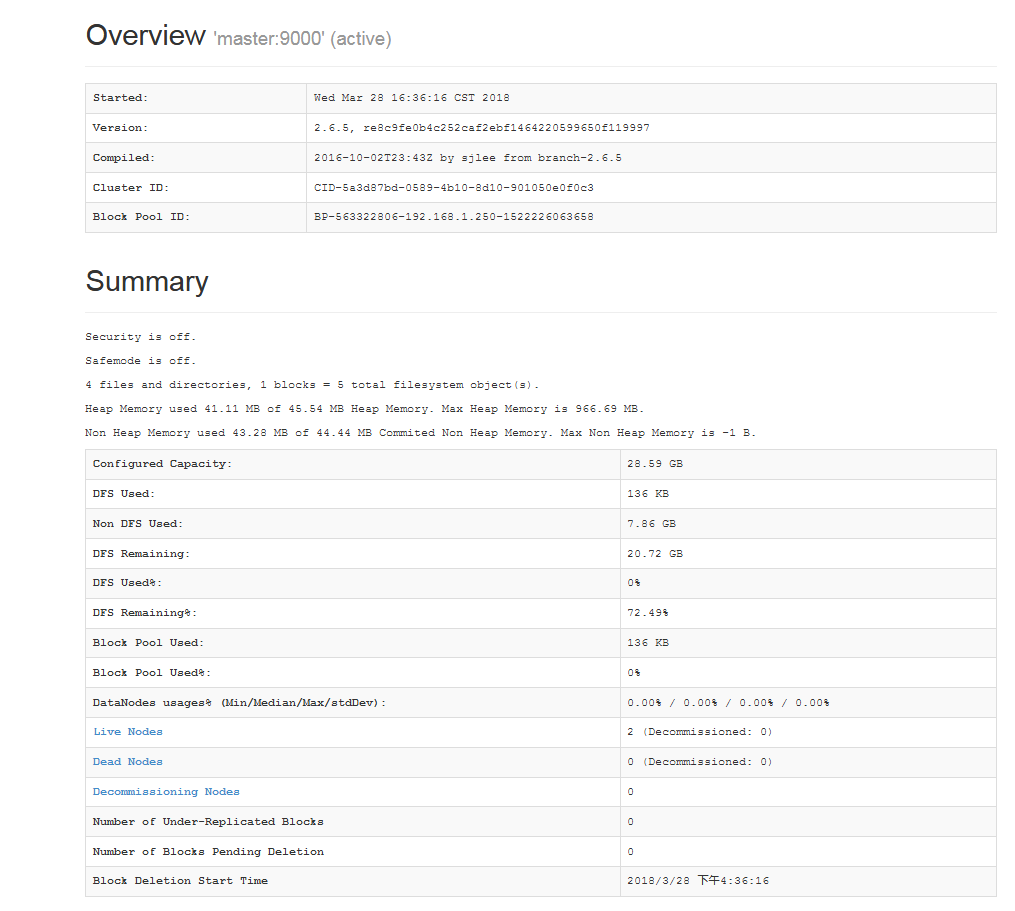
4.测试向hadoop集群系统提交一个mapreduce任务
[root@master sbin]# hdfs dfs -mkdir -p /Hadoop/test
[root@master ~]# hdfs dfs -put install.log /Hadoop/test
[root@master ~]# hdfs dfs -ls /Hadoop/test
Found items
-rw-r--r-- root supergroup -- : /Hadoop/test/install.log
可以看到一切正常,至此我们的三台hadoop集群搭建完毕。
其他问题:

原因及解决办法见此链接:https://blog.csdn.net/l1028386804/article/details/51538611
Hadoop2.6.5集群搭建的更多相关文章
- 懒人记录 Hadoop2.7.1 集群搭建过程
懒人记录 Hadoop2.7.1 集群搭建过程 2016-07-02 13:15:45 总结 除了配置hosts ,和免密码互连之外,先在一台机器上装好所有东西 配置好之后,拷贝虚拟机,配置hosts ...
- hadoop2.7.2集群搭建
hadoop2.7.2集群搭建 1.修改hadoop中的配置文件 进入/usr/local/src/hadoop-2.7.2/etc/hadoop目录,修改hadoop-env.sh,core-sit ...
- hadoop2.8 ha 集群搭建
简介: 最近在看hadoop的一些知识,下面搭建一个ha (高可用)的hadoop完整分布式集群: hadoop的单机,伪分布式,分布式安装 hadoop2.8 集群 1 (伪分布式搭建 hadoop ...
- centos下hadoop2.6.0集群搭建详细过程
一 .centos集群环境配置 1.创建一个namenode节点,5个datanode节点 主机名 IP namenodezsw 192.168.129.158 datanode1zsw 192.16 ...
- Hadoop2.0 HA集群搭建步骤
上一次搭建的Hadoop是一个伪分布式的,这次我们做一个用于个人的Hadoop集群(希望对大家搭建集群有所帮助): 集群节点分配: Park01 Zookeeper NameNode (active) ...
- hadoop2.6.0集群搭建
p.MsoNormal { margin: 0pt; margin-bottom: .0001pt; text-align: justify; font-family: Calibri; font-s ...
- vmware10上三台虚拟机的Hadoop2.5.1集群搭建
由于官方版本的Hadoop是32位,若在64位Linux上安装,则必须先重新在64位环境下编译Hadoop源代码.本环境采用编译后的hadoop2.5.1 . 安装参考博客: 1 http://www ...
- hadoop2.4.1集群搭建
准备Linux环境 修改主机名: $ vim /etc/sysconfig/network NETWORKING=yes HOSTNAME=hadoop001 修改IP: # vim /etc/sys ...
- hadoop2.2.0集群搭建与部署
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3818908.html 一.安装环境 1.系统环境 CentOS 6.4 2.集群机器节点ip 节点一i ...
随机推荐
- 【转】车和家CEO李想回顾创业20年:站在更高层才能看到低层问题
明天就要上班了,写一下我创业20年经历的五个楼层,每一层的认知回过头来看都是天壤之别,以及无比的幸运.只有到了更高一层,你才可以更好的看到低楼层的问题.希望对你的工作有所帮助. 一层楼,生为一个普通的 ...
- ML: 聚类算法-概论
聚类分析是一种重要的人类行为,早在孩提时代,一个人就通过不断改进下意识中的聚类模式来学会如何区分猫狗.动物植物.目前在许多领域都得到了广泛的研究和成功的应用,如用于模式识别.数据分析.图像处理.市场研 ...
- 【python】try...except...后中断程序继续运行
- Linux系统构成和基本操作
Linux的优势 Linux的目录结构 Linux目录与文件管理 列出目录内容 创建新目录(文件夹) 创建文件 复制文件或目录 删除文件或目录 移动目录或文件 查看文件属性 文件属性含义 读权限-4 ...
- 关于Zookeeper选举机制
zookeeper集群 配置多个实例共同构成一个集群对外提供服务以达到水平扩展的目的,每个服务器上的数据是相同的,每一个服务器均可以对外提供读和写的服务,这点和redis是相同的,即对客户端来讲每个服 ...
- ALGO-22_蓝桥杯_算法训练_装箱问题(DP)
问题描述 有一个箱子容量为V(正整数,<=V<=),同时有n个物品(<n<=),每个物品有一个体积(正整数). 要求n个物品中,任取若干个装入箱内,使箱子的剩余空间为最小. 输 ...
- 【springBoot】之快速构建一个web项目
基于maven,首先看pom文件 <parent> <groupId>org.springframework.boot</groupId> <artifact ...
- C++进阶--拥有资源句柄的类(浅拷贝,深拷贝,虚构造函数)
// Person通过指针拥有string class Person { public: Person(string name) { pName_ = new string(name); } ~Per ...
- Hard commits, soft commits and transaction logs
“Hard commits are about durability, soft commits are about visibility“ Transaction Logs 首先介绍下solrcl ...
- Java 线程转储 [转]
http://www.oschina.net/translate/java-thread-dump java线程转储 java的线程转储可以被定义为JVM中在某一个给定的时刻运行的所有线程的快照.一个 ...