mysql分页查询优化(索引延迟关联)
对于web后台报表导出是一种常见的功能点,实际对应服务后端即数据库的排序分页查询。如下示例为公司商户积分报表导出其中一个sql ,当大批量的导出请求进入时候,mysql的cpu急剧上升瞬间有拖垮库的风险。
SELECT
*
FROM
coupons.cp_score_log
WHERE
`m_shopid` = 40861
AND `add_time` BETWEEN 1483200000
AND 1544543999
ORDER BY
add_time DESC
LIMIT 118000 ,1000 ;
报表导出功能存在几个问题:
1、时间跨度太大,数据量剧增。(可以结合业务需求,限制一定时间范围,比如只能导出3个月以内数据)
2、DB方面没有限制并发。(需要dba一起参与)
3、sql未考虑LIMIT分页过大,查询性能问题。(索引延迟关联,本文重点 或者 限制分页上限)
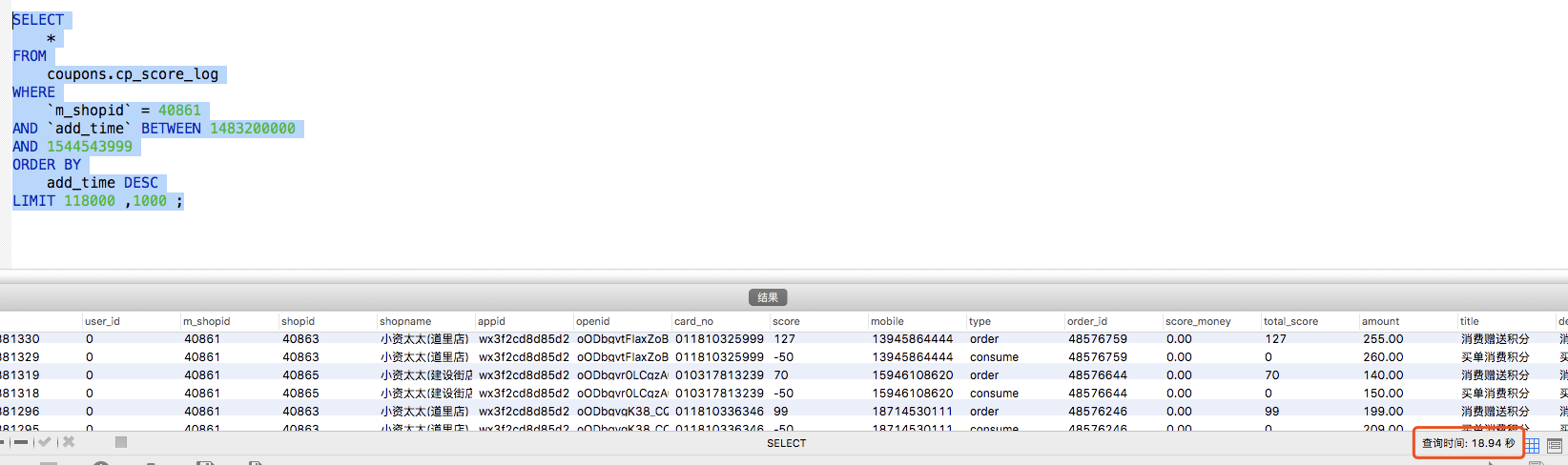
运行结果:18.94s (结果受到机器峰值影响,可能低一些,可能更高)
sql执行计划 :
表结构:
CREATE TABLE `cp_score_log` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
......
`m_shopid` int(10) DEFAULT '' COMMENT '总店id',
......
`add_time` int(10) DEFAULT '',
`......PRIMARY KEY (`id`),
KEY `idx_cardno` (`card_no`),
KEY `idx_shopid` (`shopid`) USING BTREE,
KEY `idx_orderid` (`order_id`),
KEY `idx_shopid_add_time_score` (`shopid`,`add_time`,`score`),
KEY `idx_mshopid` (`m_shopid`,`add_time`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=24130302 DEFAULT CHARSET=utf8 COMMENT='积分记录表'
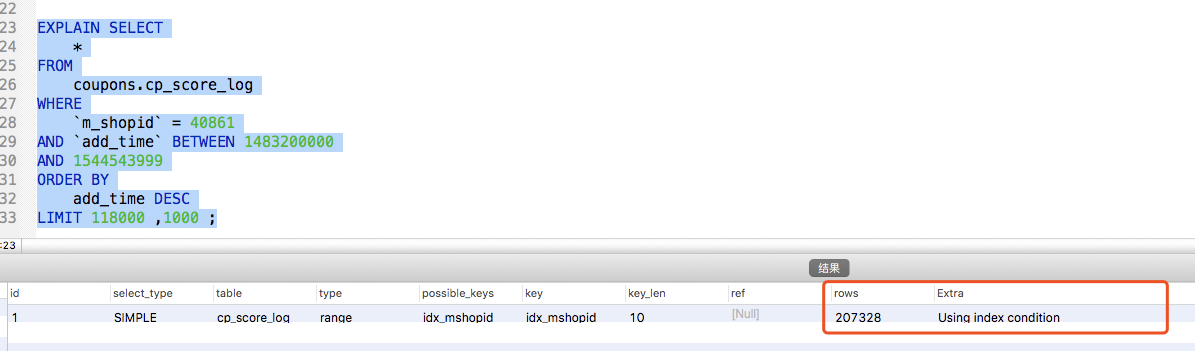
表的数据基本在2400万左右未进行拆分,通过查看sql和执行计划发现已经命中索引【idx_mshopid】,但是查询效率仍然很低。抛开其他问题只针对sql来说,核心的问题出在LIMIT。
MySQL中 【LIMIT offset, m】并不是跳过offset然后取m行数据,而是直接取【offset+m】行数据,丢弃前offset行返回m行。因此查询的效率就特别的低,特别当offset特别大的时候。
针对上面提出第3点问题,可以考虑使用后索引延迟关联,即 通过建立中间表覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的数据。 同时限制最大的分页数量,比如百度最大分页即为79页 。
SELECT
*
FROM
cp_score_log
INNER JOIN (
SELECT
id,
add_time
FROM
coupons.cp_score_log
WHERE
`m_shopid` = 40861
AND `add_time` BETWEEN 1483200000
AND 1544543999
ORDER BY
add_time DESC
LIMIT LIMIT 118000 ,1000
) b ON cp_score_log.id = b.id
ORDER BY
b.add_time DESC;
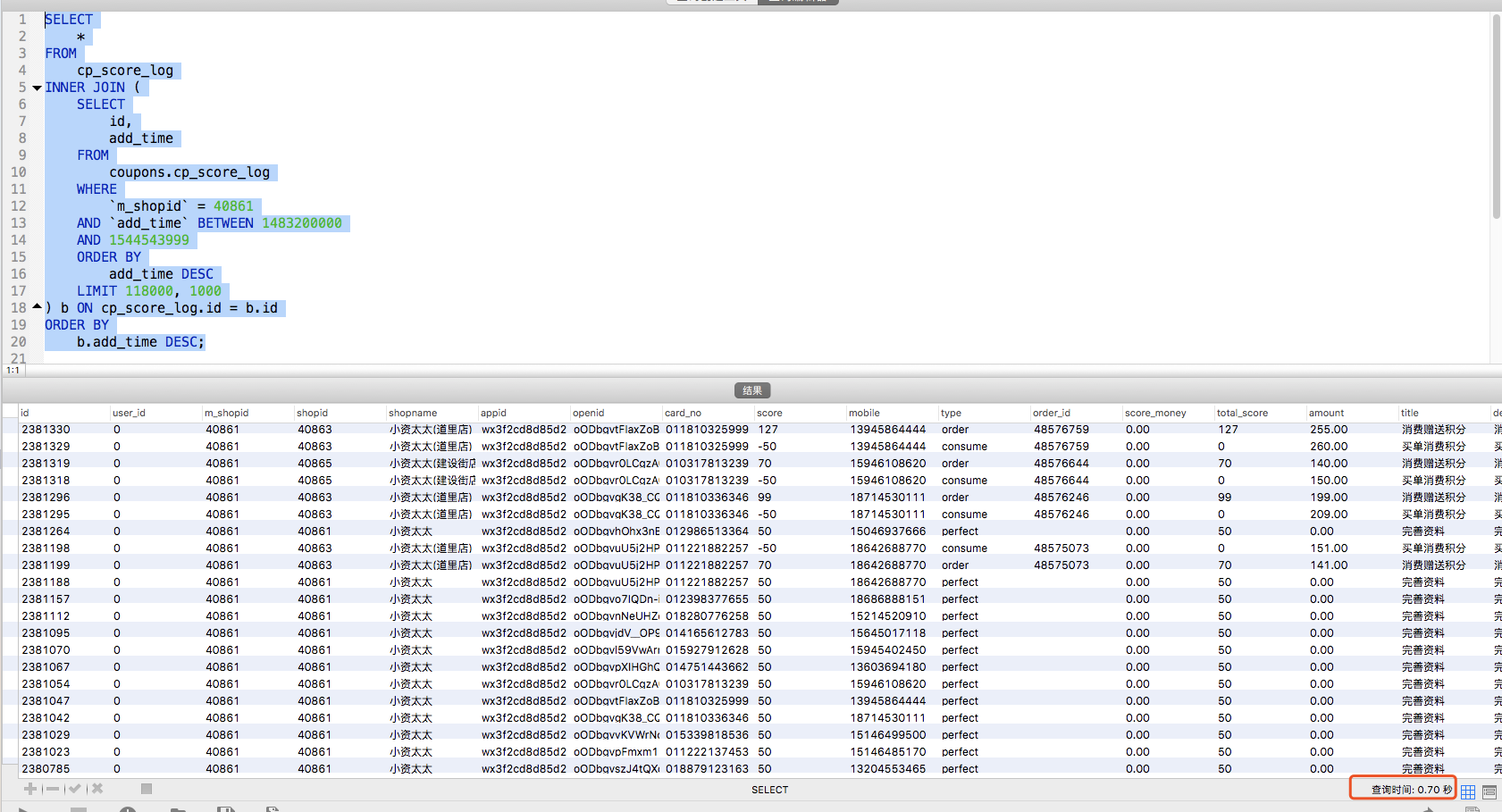
运行结果:0.7s (天差地别)
sql执行计划:
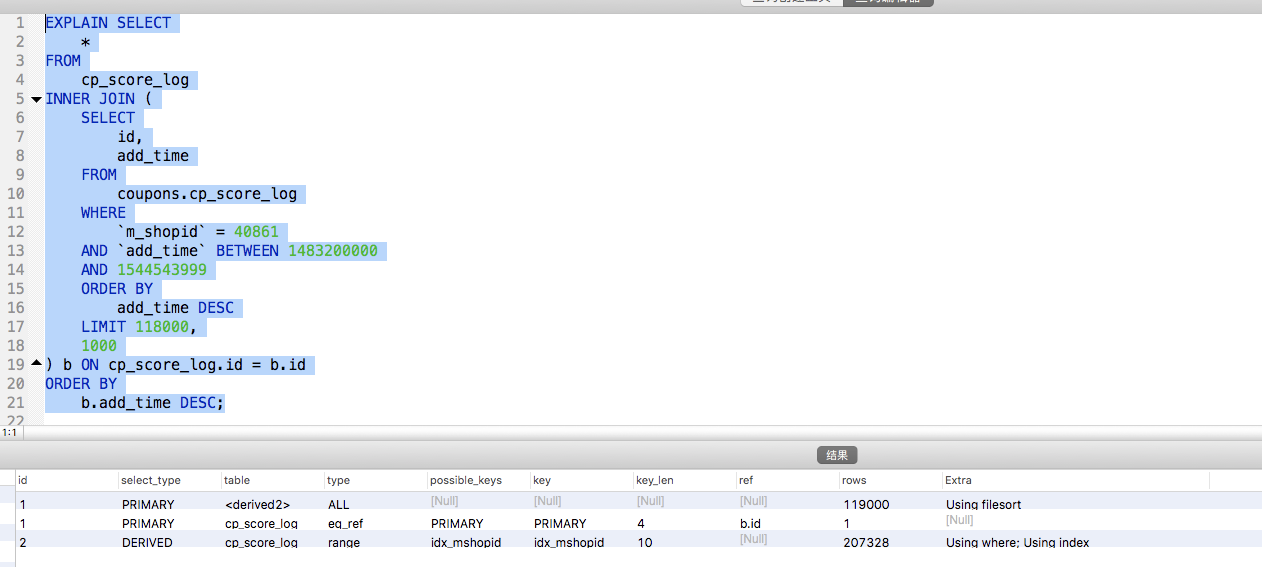
由此可见,使用sql延迟关联sql效率确实提升明显。但是并非能解决所以问题,当表数据过大已经数据库并发提高时,还是会出现查询慢甚至拖垮db当风险。所以因综合考虑,将请求量削峰。
mysql分页查询优化(索引延迟关联)的更多相关文章
- MySQL 分页查询优化——延迟关联优化
目录 1. InnoDB表的索引的几个概念 2. 覆盖索引和回表 3. 分页查询 4. 延迟关联优化 写在前面 下面的介绍均是在选用MySQL数据库和Innodb引擎的基础开展.我们先 ...
- MySQL性能优化之延迟关联
[背景] 某业务数据库load 报警异常,cpu usr 达到30-40 ,居高不下.使用工具查看数据库正在执行的sql ,排在前面的大部分是: SELECT id, cu_id, name, in ...
- MySQL 分页查询优化
有时在处理偏移量非常大的分页时候查询时,例如LIMIT 1000,10这样的查询,这时MySQL需要查询1010条记录然后只返回最后10条,前面1000条记录都被抛弃,这样的代价非常高.要优化这种查询 ...
- 复盘MySQL分页查询优化方案
一.前言 MySQL分页查询作为Java面试的一道高频面试题,这里有必要实践一下,毕竟实践出真知. 很多同学在做测试时苦于没有海量数据,官方其实是有一套测试库的. 二.模拟数据 这里模拟数据分2种情况 ...
- MySQL大数据分页的优化思路和索引延迟关联
之前上次在部门的分享会上,听了关于MySQL大数据的分页,即怎样使用limit offset,N来进行大数据的分页,现在做一个记录: 首先我们知道,limit offset,N的时候,MySQL的查询 ...
- 4种MySQL分页查询优化的方法,你知道几个?
前言 当需要从数据库查询的表有上万条记录的时候,一次性查询所有结果会变得很慢,特别是随着数据量的增加特别明显,这时需要使用分页查询.对于数据库分页查询,也有很多种方法和优化的点.下面简单说一下我知道的 ...
- mysql分页查询优化
由于MySql的分页机制:并不是跳过 offset 行,而是取 offset + N 行,然后返回放弃前 offset 行,返回N 行, 所以当 offset 特别大的时候,效率就非常的低下,要么控制 ...
- mysql通过“延迟关联”进行limit分页查询优化的一个实例
最近在生产上遇见一个分页查询特别慢的问题,数据量大概有200万的样子,翻到最后一页性能很低,差不多得有4秒的样子才能出来整个页面,需要进行查询优化. 第一步,找到执行慢的sql,如下: SELECT ...
- mysql优化----大数据下的分页,延迟关联,索引与排序的关系,重复索引与冗余索引,索引碎片与维护
理想的索引,高效的索引建立考虑: :查询频繁度(哪几个字段经常查询就加上索引) :区分度要高 :索引长度要小 : 索引尽量能覆盖常用查询字段(如果把所有的列都加上索引,那么索引就会变得很大) : 索引 ...
随机推荐
- 那些年实用但被我忘掉javascript属性.onresize
//获取屏幕宽度并动态赋值 var winWidth = 0; var winHeight = 0; function findDimensions() //函数:获取尺寸 { //获取窗口宽度 if ...
- [转载]JavaScript 的轻框架开发
http://www.open-open.com/news/view/1d64fed 为什么我们不用 Angular, Ember 或者 Backbone! Muut 是一个特殊的论坛平台,它也有着巨 ...
- [转载]详解主流浏览器多进程架构:Chrome、IE
http://www.cnbeta.com/articles/109595.htm 随着Web浏览器重要性的日益突出,恶意软件.木马.间谍软件等网络攻击也呈现逐渐的上升.而面对 如此众多的潜在威胁,为 ...
- 关于 xcode5 的no matching provisioning profiles found
CHENYILONG Blog 关于 xcode5 的no matching provisioning prof- about the question in xcode5 "no matc ...
- Fiddler抓取HTTPS最全(强)攻略
本文来自于柠檬班49期学员superman童鞋的学习笔记.希望对同样是测试萌新的你有帮助,如果觉得好,可以点个赞噢~ 对于想抓取HTTPS的测试初学者来说,常用的工具就是fiddler.可是在初学时, ...
- DataTable转Json(兼容easyUI特殊json分页)
用法:上述方法是DataTable的扩展方法:静态类静态方法,变量前用this (一)ps:普通datatable转标准json DataTable dt = 获取db中的datatable数据. s ...
- Ansible 插件 之 【CMDB】【转】
Github地址: https://github.com/fboender/ansible-cmdb 从facts收集信息,生成主机概述 安装 wget https://github.com/fboe ...
- 小白学习安全测试(三)——扫描工具-Nikto使用
扫描工具-Nikto #基于WEB的扫描工具,基本都支持两种扫描模式.代理截断模式,主动扫描模式 手动扫描:作为用户操作发现页面存在的问题,但可能会存在遗漏 自动扫描:基于字典,提高速度,但存在误报和 ...
- 发布构件到Maven中央仓库
一.注册jira账号 访问如下网址: https://issues.sonatype.org/secure/Signup.jspa 记住邮箱,用户名,密码以备以后使用,一定牢记. 二.创建一个issu ...
- git命令之git stash 暂存临时代码
git stash — 暂存临时代码 stash命令可以很好的解决这样的问题.当你不想提交当前完成了一半的代码,但是却不得不修改一个紧急Bug,那么使用’Git stash’就可以将你当前未提交到 ...