李航统计学习方法——算法2k近邻法
2.4.1 构造kd树
给定一个二维空间数据集,T={(2,3),(5,4),(9,6)(4,7),(8,1),(7,2)} ,构造的kd树见下图
2.4.2 kd树最近邻搜索算法
三、实现算法
下面算法实现并没有从构建kd树再搜索kd树开始,首先数据分为两部分,train数据和predict的数据,将train的数据抽取k个作为predict的最临近k节点,计算这k个数据和predict的距离,继续计算train中其他数据和predict的欧式距离,若小于k中欧式距离,那么替换较大的原始最临近k个节点中的数据,直到所有数据循环一遍为止,此时最临近k个节点就是predict数据在train中最临近节点,然后找出这k个节点出现次数最多的标签作为predict的标签。
还有一篇博文介绍knn非常详细
# coding=utf-8
import numpy as np
import pandas as pd
import time
def Predict(testset, trainset, train_labels):
predict = []
count = 0 for test_vec in testset:
# 输出当前运行的测试用例坐标,用于测试
print count
count += 1 knn_list = [] # 当前k个最近邻居
max_index = -1 # 当前k个最近邻居中距离最远点的坐标
max_dist = 0 # 当前k个最近邻居中距离最远点的距离 # 先将前k个点放入k个最近邻居中,填充满knn_list
for i in range(k):
label = train_labels[i]
train_vec = trainset[i] dist = np.linalg.norm(train_vec - test_vec) # 计算两个点的欧氏距离 knn_list.append((dist, label)) # 剩下的点
for i in range(k, len(train_labels)):
label = train_labels[i]
train_vec = trainset[i] dist = np.linalg.norm(train_vec - test_vec) # 计算两个点的欧氏距离 # 寻找10个邻近点钟距离最远的点,///应该有一个函数代替循环吧
if max_index < 0:
for j in range(k):
if max_dist < knn_list[j][0]:
max_index = j
max_dist = knn_list[max_index][0] # 如果当前k个最近邻居中存在点距离比当前点距离远,则替换
if dist < max_dist:
knn_list[max_index] = (dist, label)
max_index = -1
max_dist = 0 # 统计选票
class_total = 10
class_count = [0 for i in range(class_total)]
for dist, label in knn_list:
class_count[label] += 1 # 找出最大选票
mmax = max(class_count) # 找出最大选票标签
for i in range(class_total):
if mmax == class_count[i]:
predict.append(i)
break return np.array(predict) k = 10
if __name__ == '__main__':
time_1 = time.time()
raw_data = pd.read_csv('D:\\Python27\\yy\\data\\Digit Recognizer\\train.csv')
raw_test = pd.read_csv('D:\\Python27\\yy\\data\\Digit Recognizer\\test.csv')
test_features = raw_test.values
data = raw_data.values
train_features = data[0::, 1::]
train_labels = data[::, 0]
time_2 = time.time()
print 'read data cost ', time_2 - time_1, ' second', '\n' print 'Start predicting'
test_predict = Predict(test_features, train_features, train_labels)
time_3 = time.time()
print 'predicting cost ', time_3 - time_2, ' second', '\n'
一、K近邻算法
k近邻法(k-nearest neighbor,k-NN)是一种基本分类与回归方法,输入实例的特征向量,输出实例的类别,其中类别可取多类
k近邻法只是利用训练数据集对特征向量空间进行划分,所以选取的训练数据一定要保证样本分布均匀。
算法思路:给定一个训练数据集,对于新输入实例,在训练数据集中找到与该实例最临近的k个实例
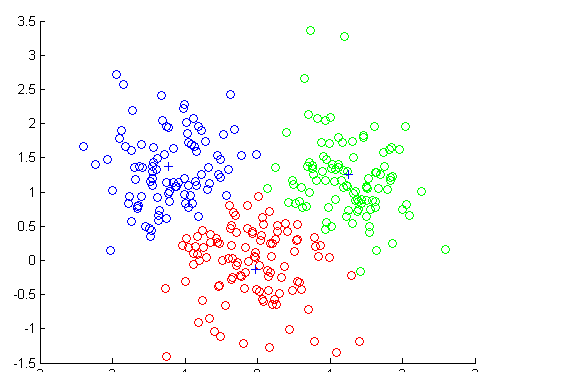

二、k近邻模型
2.1 距离度量
特征空间中两个实例点的距离就是两个实例点相似程度的反应
距离定义: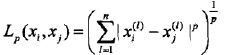
(1)当p=1,称为曼哈顿距离
(2)当p=2,称为欧式距离
(3)当p取无穷大时,它是各个坐标距离的最大值 max|xi-xj|
注意:p值的选择会影响分类结果,例如二维空间的三个点 x1=(1,1),x2=(5,1), x3=(4,4)
由于x1和x2只有第二维上不同,不管p值如何变化,Lp始终等于4,而L1(x1,x3)=3+3=6,L2(x1,x3)=(9+9)1/2=4.24,L3(x1,x3)=(27+37)1/3=3.78,L4=3.57……
当p=1或2时,X2和X1是近邻点
2.2 k值的选择
在应用中,k值一般取一个较小的数值,通常采用交叉验证法来选取最优k值
k较小时,模型复杂,容易过拟合
k较大时,模型简单
2.3 分类决策规则
使用多数表决规则,即少数服从多数

李航统计学习方法——算法2k近邻法的更多相关文章
- 李航统计学习方法(第二版)(五):k 近邻算法简介
1 简介 k近邻法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类.k近邻法假设给定一个训练数据集,其中的实例类别已定.分类时,对新的实例,根据其k个最近邻的训练实例的类别,通 ...
- 李航统计学习方法(第二版)(六):k 近邻算法实现(kd树(kd tree)方法)
1. kd树简介 构造kd树的方法如下:构造根结点,使根结点对应于k维空间中包含所有实例点的超矩形区域;通过下面的递归方法,不断地对k维空间进行切分,生成子结点.在超矩形区域(结点)上选择一个坐标轴和 ...
- 李航统计学习方法(第二版)(十):决策树CART算法
1 简介 1.1 介绍 1.2 生成步骤 CART树算法由以下两步组成:(1)决策树生成:基于训练数据集生成决策树,生成的决策树要尽量大;(2)决策树剪枝:用验证数据集对己生成的树进行剪枝并选择最优子 ...
- 李航-统计学习方法-笔记-3:KNN
KNN算法 基本模型:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例.这k个实例的多数属于某个类,就把输入实例分为这个类. KNN没有显式的学习过程. KNN使用的模型 ...
- 《统计学习方法》笔记三 k近邻法
本系列笔记内容参考来源为李航<统计学习方法> k近邻是一种基本分类与回归方法,书中只讨论分类情况.输入为实例的特征向量,输出为实例的类别.k值的选择.距离度量及分类决策规则是k近邻法的三个 ...
- Adaboost算法的一个简单实现——基于《统计学习方法(李航)》第八章
最近阅读了李航的<统计学习方法(第二版)>,对AdaBoost算法进行了学习. 在第八章的8.1.3小节中,举了一个具体的算法计算实例.美中不足的是书上只给出了数值解,这里用代码将它实现一 ...
- 统计学习方法学习(四)--KNN及kd树的java实现
K近邻法 1基本概念 K近邻法,是一种基本分类和回归规则.根据已有的训练数据集(含有标签),对于新的实例,根据其最近的k个近邻的类别,通过多数表决的方式进行预测. 2模型相关 2.1 距离的度量方式 ...
- 统计学习方法笔记 -- KNN
K近邻法(K-nearest neighbor,k-NN),这里只讨论基于knn的分类问题,1968年由Cover和Hart提出,属于判别模型 K近邻法不具有显式的学习过程,算法比较简单,每次分类都是 ...
- 《统计学习方法(李航)》讲义 第03章 k近邻法
k 近邻法(k-nearest neighbor,k-NN) 是一种基本分类与回归方法.本书只讨论分类问题中的k近邻法.k近邻法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类 ...
随机推荐
- IntelliJ IDEA 2017版 spring-boot 2.0.3 邮件发送搭建,概念梳理 (一)
邮件发送功能总结 第一部分 背景 一.使用场景 (1)注册验证 注册各大网站,通常需要输入邮件地址,在注册成功后,会发送一封邮箱验证的邮件,点击确认,证明这个邮箱是用户自己的 ...
- IntelliJ IDEA 2017版 spring-boot2.0.访问jsp页面;IDE Springboot JSp 页面访问
1.编译器设置. 生成项目后,点击file 点开Modules 选中main,右键 选择新建文件夹 选中外部 右边添加 选中项目如图: 选好后选OK退出 webapp带点了,就是成功了,在这里建立的J ...
- python处理中文
python 清洗中文文件 需要用到的两个链接: 1,unicode编码转换器 http://www.bangnishouji.com/tools/chtounicode.html 2,Python匹 ...
- ng-repeat动态改变样式
当我们使用AngularJs的ng-repeat时候动态绑定数据时,遇到遍历出来的标签样式都一样,这时候希望根据数组的下标分别对应不同的样式 解决:使用$index获取数组下标根据下标改变样式 < ...
- Linux学习(2)- 正则表达式基础
Linux学习(2)- 正则表达式基础 一.基础正则表达式介绍与练习 学习内容 正则表达式特殊符号 [:alnum:]代表英文大小写字母及数字 [:alpha:]代表英文大小写字母 [:blank:] ...
- HP 集群软件 - 不能接收节点的设备查询信息:软件引起的连接失败
问题 # cmcheckconf -v -C /etc/cmcluster/cmclconfig.ascii Begin cluster verification... Checking clust ...
- MIT Molecular Biology 笔记7 调控RNA
视频 https://www.bilibili.com/video/av7973580/ 教材 Molecular biology of the gene 7th edition J.D. Wat ...
- spring mvc使用ModelAndView时发生No request handling method with name '方法 名' in class [类名]的错误
我日,下午关于标题错误查了好久,网上啥说法都有, 后来发现是ModelAndView的路径引错了 正确路径应该为: import org.springframework.web.servlet.Mod ...
- web-day15
第15章WEB15-AJAX和JQuery案例篇 今日任务 使用AJAX完成用户名的异步校验 使用JQuery完成用户名异步校验 使用JQuery完成商品信息模糊显示 使用JQuery完成省市联动效果 ...
- [Phalcon-framework]2016-04-13_安装使用 Phalcon 框架
1. 获取你的 PHP Version,操作系统是 x86 还是 64bit的,以及 Compiler 是什么 VC, 你可以直接同时 phpinfo() 函数获取到,如下截图: 2. 下载对应的 ...