Tesseract 3 语言数据的训练方法
OCR,光学字符识别
光学字符识别(OCR,Optical Character Recognition)是指对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。OCR技术非常专业,一般多是印刷、打印行业的从业人员使用,可以快速的将纸质资料转换为电子资料。关于中文OCR,目前国内水平较高的有清华文通、汉王、尚书,其产品各有千秋,价格不菲。国外OCR发展较早,像一些大公司,如IBM、微软、HP等,即使没有推出单独的OCR产品,但是他们的研发团队早已掌握核心技术,将OCR功能植入了自身的软件系统。对于我们程序员来说,一般用不到那么高级的,主要在开发中能够集成基本的OCR功能就可以了。这两天我查找了很多免费OCR软件、类库,特地整理一下,今天首先来谈谈Tesseract,下一次将讨论下Onenote 2010中的OCR API实现。可以在这里查看OCR技术的发展简史。
1、Tesseract概述
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封。
数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生--2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。
Tesseract目前已作为开源项目发布在Google Project,其项目主页在这里查看,其最新版本3.0已经支持中文OCR,并提供了一个命令行工具。本次我们来测试一下Tesseract 3.0,由于命令行对最终用户不太友好,我用WPF简单封装了一下,就可以方便的进行中文OCR了。
1.准备:
- 安装Tesseract , 我这里用的是 tesseract 3.02.02
- 下载图片,保存到本地,
- 下载工具jTessBoxEditor. http://sourceforge.net/projects/vietocr/files/jTessBoxEditor/,这个工具是用来训练样本用的,由于该工具 是用JAVA开发的,需要安装JAVA虚拟机才能运行。
2.合并样本图像
运行jTessBoxEditor工具,在点击菜单栏中Tools--->Merge TIFF。在弹出的对话框中选择样本图像(按Shift选择多张),合并成total.tif文件。
3.Make Box Files。
在total.tif所在的目录下打开一个命令行,产生相应的Box文件(*.box)
输入:
tesseract mjoren.normal.exp0.tif mjoren.normal.exp0 batch.nochop makebox
来生成一个box文件,该文件记录了tesseract识别出来的每一个字和其位置坐标。
屏幕输出如下
E:\data\Users\Administrator\Desktop\ocrBuider2>tesseract mjoren.normal.exp0.tif
mjoren.normal.exp0 batch.nochop makebox
Tesseract Open Source OCR Engine v3. with Leptonica
Page of
Page of
Empty page!!
Empty page!!
Page of
Empty page!!
Empty page!!
这时目录多出了一个 mjoren.normal.exp0.box和mjoren.normal.exp0.txt 文件
4.使用jTessBoxEditor打开total.tif文件,
需要记住的是第2步生成的mjoren.normal.exp0.box要和这个mjoren.normal.exp0.tif文件同在一个目录下。逐个校正文字,后保存。
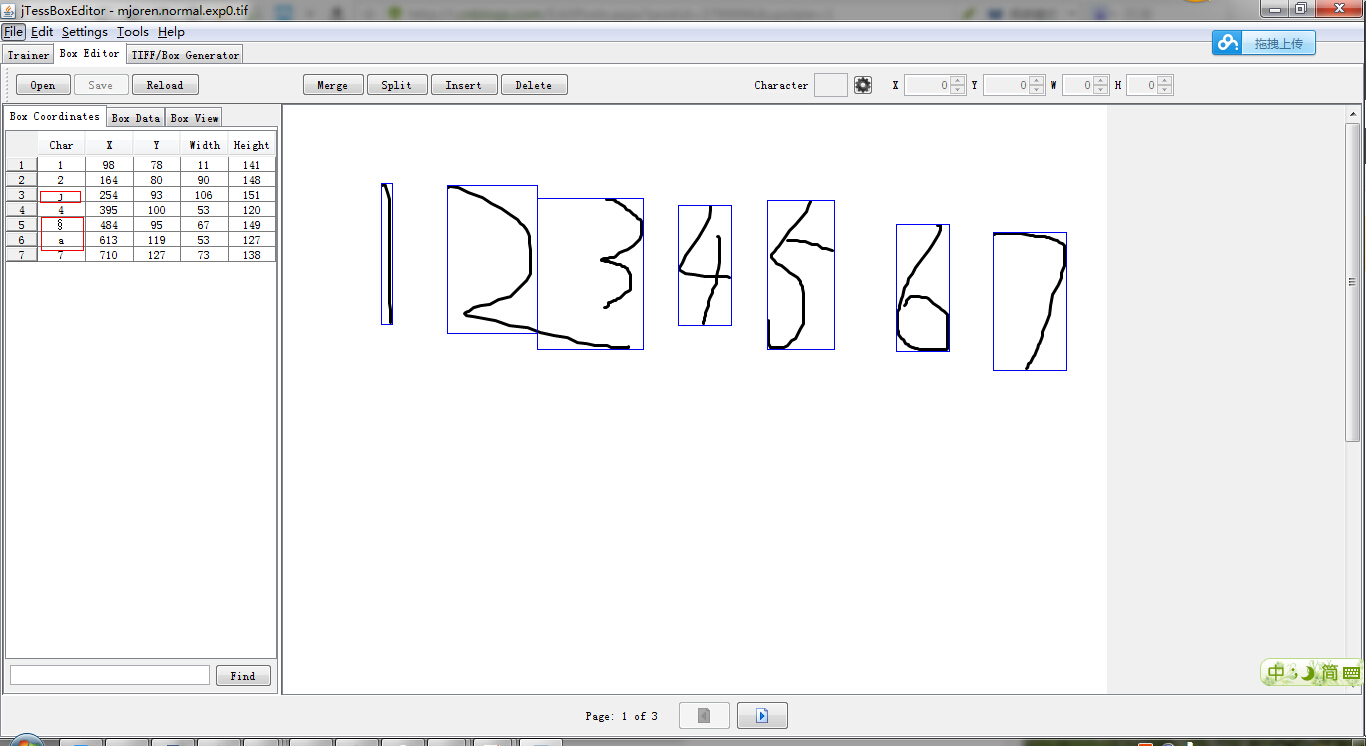
4.Run Tesseract for Training。输入命令:
产生字符特征文件(*.tr)
tesseract mjoren.normal.exp0.tif mjoren.normal.exp0 nobatch box.train
屏幕输出如下:
E:\data\Users\Administrator\Desktop\ocrBuider2>tesseract mjoren.normal.exp0.tif
mjoren.normal.exp0 nobatch box.train
Tesseract Open Source OCR Engine v3. with Leptonica
Page of
APPLY_BOXES:
Boxes read from boxfile:
Found good blobs.
TRAINING ... Font name = normal
Generated training data for words
Page of
Empty page!!
Empty page!!
Page of
Empty page!!
Empty page!!
这时目录会多出2个文件: mjoren.normal.exp0.tr
5.Compute the Character Set。输入命令:
产生计算字符集(unicharset)
unicharset_extractor mjoren.normal.exp0.box
执行结果:
E:\data\Users\Administrator\Desktop\ocrBuider2>unicharset_extractor mjoren.norm
al.exp0.box
Extracting unicharset from mjoren.normal.exp0.box
Wrote unicharset file ./unicharset.
6.定义字体特征文件并聚集字符特征
新建文件“font_properties”。那么需要在目录下新建一个名字为“font_properties”的文件,并且输入文本 :
注意:这里 normal 必须与训练名中的名称保持一致,填入下面内容 ,这里全取值为0,表示字体不是粗体、斜体等等。
normal 0 0 0 0 0
聚集字符特征(inttemp、pffmtable、normproto)
执行命令:
mftraining -F font_properties -U unicharset mjoren.normal.exp0.tr
执行结果
E:\data\Users\Administrator\Desktop\ocrBuider2>mftraining -F font_properties -U unicharset mjoren.normal.exp0.tr
Warning: No shape table file present: shapetable
Reading mjoren.normal.exp0.tr ...
Flat shape table summary: Number of shapes = max unichars = number with mult
iple unichars =
Warning: no protos/configs for j in CreateIntTemplates()
Warning: no protos/configs for 搂 in CreateIntTemplates()
Warning: no protos/configs for a in CreateIntTemplates()
Done!
font_properties不含有BOM头,文件内容格式如下:
<fontname> <italic> <bold> <fixed> <serif> <fraktur>
其中fontname为字体名称,必须与[lang].[fontname].exp[num].box中的名称保持一致。<italic> 、<bold> 、<fixed> 、<serif>、 <fraktur>的取值为1或0,表示字体是否具有这些属性。
7.Clustering。产生字符形状正常化特征文件normproto
输入命令:
cntraining mjoren.normal.exp0.tr
执行结果:
E:\data\Users\Administrator\Desktop\ocrBuider2>cntraining mjoren.normal.exp0.tr Reading mjoren.normal.exp0.tr ...
Clustering ... Writing normproto ...
8.此时,在目录下应该生成若干个文件了,把unicharset, inttemp, normproto, pffmtable这四个文件加上前缀“normal.”。然后 合并训练文件
输入命令:
combine_tessdata normal.
执行结果如下:
E:\data\Users\Administrator\Desktop\ocrBuider2>combine_tessdata normal.
Combining tessdata files
TessdataManager combined tesseract data files.
Offset for type is -
Offset for type is
Offset for type is -
Offset for type is
Offset for type is
Offset for type is
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is -
必须确定的是第2、4、5、6行的数据不是-1,那么一个新的字典就算生成了。
此时目录下“normal.traineddata”的文件拷贝到tesseract程序目录下的“tessdata”目录。
以后就可以使用该该字典来识别了,例如:
tesseract mjoren.normal.exp0.tif result -l normal
通过训练出来的新语言,识别率提高了不少。
E:\data\Users\Administrator\Desktop\ocrBuider2>tesseract mjoren.normal.exp0.tif
result -l normal
Tesseract Open Source OCR Engine v3. with Leptonica
Page of
Page of
Empty page!!
Empty page!!
Page of
Empty page!!
Empty page!!
纠正出来的结果
特别说明:
在训练的过程中,初次接触的人容易犯一些小错误,这些错误虽然小,但很可能让你陷入困惑和痛苦中。那位师妹就是因为小问题困惑不已才找我帮忙的。下面简单的罗列一下几点需要注意的地方:
- 前面提到的normal可以被你想要的任何字符串代替,主要是为了给你训练的库取个名字。
- 第二步产生的Box文件,需要手动修改,一定要以Unicode模式保存。修改的时候要注意方法和含义,详细的说明Google原文中有说明。
- 第五步程序自动产生的文件是只有扩展名的,需要你自己手动将名字改成前缀一致。后面产生的可选文件也依照此法操作。
- 所有的这些文件都准备好了之后,需要放到同一目录下,执行combine_tessdata进行合并的时候,注意要切换到文件所在的目录执行,否则将会报错,提示找不到文件。
- 合并成功之后,要记得将训练好的文件(normal.traineddata)放到程序的tessdata子目录下,否则测试就会提示找不到语言库文件。
好了,到这里,基本上所有的问题都能解决了。
Tesseract 3 语言数据的训练方法的更多相关文章
- R语言数据接口
R语言数据接口 R语言处理的数据一般从外部导入,因此需要数据接口来读取各种格式化的数据 CSV # 获得data是一个数据帧 data = read.csv("input.csv" ...
- R语言数据的导入与导出
1.R数据的保存与加载 可通过save()函数保存为.Rdata文件,通过load()函数将数据加载到R中. > a <- 1:10 > save(a,file='d://data/ ...
- tesseract中文语言文件包 下载
tesseract中文语言文件包 下载 tesseract中文语言文件包 下载 tesseract中文语言文件包 下载 下载地址是:https://github.com/tesseract-ocr/l ...
- R语言 数据重塑
R语言数据重塑 R语言中的数据重塑是关于改变数据被组织成行和列的方式. 大多数时间R语言中的数据处理是通过将输入数据作为数据帧来完成的. 很容易从数据帧的行和列中提取数据,但是在某些情况下,我们需要的 ...
- R语言数据预处理
R语言数据预处理 一.日期时间.字符串的处理 日期 Date: 日期类,年与日 POSIXct: 日期时间类,精确到秒,用数字表示 POSIXlt: 日期时间类,精确到秒,用列表表示 Sys.date ...
- 最棒的7种R语言数据可视化
最棒的7种R语言数据可视化 随着数据量不断增加,抛开可视化技术讲故事是不可能的.数据可视化是一门将数字转化为有用知识的艺术. R语言编程提供一套建立可视化和展现数据的内置函数和库,让你学习这门艺术.在 ...
- C++操作Kafka使用Protobuf进行跨语言数据交互
C++操作Kafka使用Protobuf进行跨语言数据交互 Kafka 是一种分布式的,基于发布 / 订阅的消息系统.主要设计目标如下: 以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 T ...
- C语言数据输入与输出
1 概论 C语言提供了跨平台的数据输入输出函数scanf()和printf()函数,它们可以按照指定的格式来解析常见的数据类型,例如整数,浮点数,字符和字符串等等.数据输入的来源可以是文件,控制台以及 ...
- 第六篇:R语言数据可视化之数据分布图(直方图、密度曲线、箱线图、等高线、2D密度图)
数据分布图简介 中医上讲看病四诊法为:望闻问切.而数据分析师分析数据的过程也有点相似,我们需要望:看看数据长什么样:闻:仔细分析数据是否合理:问:针对前两步工作搜集到的问题与业务方交流:切:结合业务方 ...
随机推荐
- 深入理解计算机系统第二版习题解答CSAPP 2.15
只使用位级运算和逻辑运算,编写一个C表达式,它等价于x==y.换句话说,当x和y相等时它将返回1,否则就返回0. !(x ^ y)
- xsl输出html代码 非闭合
``` </div> <div class="row-fluid"> ···
- 主机开启后,显示器显示NO SIGNAL,无信号
第一个原因:有可能是主机和显示器的连线接触不良(特别是接口处没有插好或者松动),还有可能这根连接的数据线出现问题,所以才会出现没有信号输入到屏幕,无显示,黑屏,处理方法:重新拨插一下这根连接的数据线, ...
- 使用jvisualvm和飞行记录器分析Java程序cpu占用率过高
一.jvisualvm使用 JDK1.6中Oracle提供了一个新的JVM监控工具:jvisualvm.下面重点介绍如何在本地通过远程的方式打开Linux服务器上的jvisualvm. 1.Xmana ...
- hackerrank Day 10: Binary Numbers
Task Given a base-10 integer, n, convert it to binary (base-2). Then find and print the base-10 inte ...
- 在centos中php 在连接mysql的时候,出现Can't connect to MySQL server on 'XXX' (13)
原文连接:http://hi.baidu.com/zwfec/item/64ef5ed9bf1cb3feca0c397c 红色的是命令 SQLSTATE[HY000] [2003] Can't con ...
- Android——列表视图(ListView)
列表视图是android中最常用的一种视图组件,它以垂直列表的形式列出需要显示的列表项.在android中有两种方法向屏幕中添加列表视图:一种是直接使用ListView组件创建:另外一种是让Activ ...
- Sql 基于列的Case表达式
Case表达式可以用在 Select,update ,delete ,set,in,where ,order by,having子句之后, 只是case表达式不能控制sql程序的流程,只能作为基于列的 ...
- 全面认识网络诊断命令功能与参数——netsh diagnostic命令
netsh diagnostic是网络诊断命令,主要检测网络连接和服务器连接的状态. 注意:netsh不能在Window2000以下系统中使用.案例1:使用netsh diagnostic命令检 ...
- JAVA操作LDAP总结
一.LDAP概念 LDAP的全称为Lightweight Directory Access Protocol(轻量级目录访问协议), 基于X.500标准, 支持 TCP/IP. LDAP目录为数据库, ...