sparkSessiontest
记事本内容:
打印结构:
方法1:
object SparkSessionTest { case class Person(name:String,age:Int) def main(args: Array[String]): Unit = { val sparkSession=SparkSession.builder().appName("SparkSessionTest")
.master("local[*]")
.getOrCreate()
val sparkContext=sparkSession.sparkContext
val rdd=sparkContext.textFile("D:\\temp\\person.txt")
val rowRdd=rdd.map(_.split(" ")).map(row=>Person(row(0),row(1).toInt)) import sparkSession.implicits._
rowRdd.toDF sparkSession.stop()
} }
方法2:
val sparkContext=sparkSession.sparkContext
val rdd=sparkContext.textFile("D:\\temp\\person.txt")
val schemaFiled="name,age"
val schemaString=schemaFiled.split(",")
val schema =StructType(
List(
StructField(schemaString(0),StringType,nullable = true),
StructField(schemaString(1),IntegerType,nullable = true)
)
)
val rowRdd= rdd.map(_.split("")).map(p=>Row(p(0),p(1).toInt))
val df=sparkSession.createDataFrame(rowRdd,schema)
df.show()
结果展示:
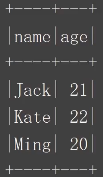
parquet的优势
支持列存储+嵌套数据格式+适配多个计算框架
节省表扫描时间和反序列的时间
压缩技术稳定出色,节省存储空间
Spark操作 Parquet文件比操作CSV等普通文件的速度更快
加载数据:sparkSession.read.parquet(“/nginx/20200110.parquet”)
写入数据:df.write.mode(SaveMode.Overwrite).parquet(“/path/to”)
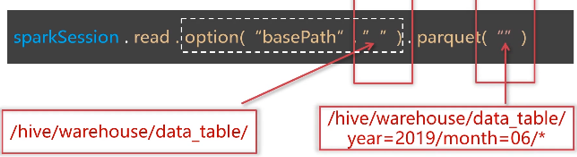
分区文件
加载批量数据:
Df.show()//只显示前20条数据
Df.show(3)//只显示前3条数据
df.show( false)//每列可以显示多于20个字符
dt show(3, false)
Df.select (“字段1”,”字段2”).show()
Df.select(col(“”) as(“别名1”),col(“字段2”)+1).show()
df.first()//获取第一行数据,返回RoW
df.head( 3)//获取前3行数据,返回 Array Row]
df.take (3)//获取前3行数据,返回 Array[Row]
df.takeaslist(3//获取前3行数据,返回List[Row]
df.limit(3).show()//返回新的 Data Frame,不是 Action操作
Df.where(“age>21”).show()
Df.filter(“age>21”).show()
Df.where(col(“age”)>21).show()
Ds.where($”age”>21).show()
Df.where(“age=21”).show
Df.where(col(“age”)===21).show
Df.where(col(“age”)=!=21).show
Val ageFilter_1 =col(“age”)>21
Val agefilter_2=col(“age”)<25
Val ageFilter_3=agefilter_1.or(ageFilter_2)
Df.where(col(“name”)===”jack”).where(ageFilter_3)
Val ageFilter_1 =col(“age”)>21
Val ageFilter_2=col(“age”)<25
Val ageFilter_3 =ageFilter_1.ll(ageFilter_2)
Df.where(col(“name”)===”jack”)
.where(ageFitler_3)
.show
//按照身份统计人数
Df.groupBy(col(“province”))
.count
.show
按照城市,手机运营商分组统计人数并按人数排序
//方法1
Df.groupby(col(“city”),col(“”op_phone“”))
.count
.withColumnRenamed(“count”,”num”)
.orderBy(col(“num”).desc)
.show
//方法2
Ds.groupBy($”city”,$”op_phone”)
.count
.withColumnRenamed(“count”,”num”)
.sort($”num”.desc)
.show
按年统计注册用户最高的积分,以及平均积分
Df.groupBy(year(col(“add_time”)))
.agg(max(col(“total_mark”).as(“max_mark”)),
Avg(col(“total_mark”).as(“avg_mark”))
)
.show






sparkSessiontest的更多相关文章
- RDD&Dataset&DataFrame
Dataset创建 object DatasetCreation { def main(args: Array[String]): Unit = { val spark = SparkSession ...
随机推荐
- docker系列详解<二>之常用命令
此篇我们以从docker运行一个tomcat为例,进行一下操作: 拉取镜像 查看镜像 创建容器 查看运行状态 进入退出容器 停止容器 重启容器 删除容器 删除镜像 1.拉取tomcat镜像: 1).查 ...
- gRPC (1):入门及服务端创建和调用原理
1. RPC 入门 1.1 RPC 框架原理 RPC 框架的目标就是让远程服务调用更加简单.透明,RPC 框架负责屏蔽底层的传输方式(TCP 或者 UDP).序列化方式(XML/Json/ 二进制)和 ...
- Linux基本操作 ------ 文件处理命令
显示目录文件 ls //显示当前目录下文件 ls /home //显示home文件夹下文件 ls -a //显示当前目录下所有文件,包括隐藏文件 ls -l //显示当前目录下文件的详细信息 ls - ...
- 使用IDEA操作Hbase API 报错:org.apache.hadoop.hbase.client.RetriesExhaustedException的解决方法:
使用IDEA操作Hbase API 报错:org.apache.hadoop.hbase.client.RetriesExhaustedException的解决方法: 1.错误详情: Excepti ...
- 用svg+css 或者js制作打钩的动画
之前老板让做一个登陆后 可以显示一个打钩的效果 百度死活搜不到 今天在B站看到的一个视频居然有 根据需求改进了一下废话不多说先看效果! html代码 <!DOCTYPE html> < ...
- [UWP]使用AlphaMaskEffect提升故障艺术动画的性能(顺便介绍怎么使用性能探测器分析UWP程序)
前几天发布了抄抄<CSS 故障艺术>的动画这篇文章,在这篇文章里介绍了如何使用Win2D绘制文字然后配合BlendEffect制作故障艺术的动画.本来打算就这样收手不玩这个动画了,但后来又 ...
- UVa 11059 最大乘积 java 暴力破解
题目链接: https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_proble ...
- sql-lib闯关21-30
第二十一关 base64编码,单引号,报错型,cookie型注入. 本关和less-20相似,只是cookie的uname值经过base64编码了,下图为我们输入万能密码显示 uname = YWRt ...
- 一文上手Tensorflow2.0(四)
系列文章目录: Tensorflow2.0 介绍 Tensorflow 常见基本概念 从1.x 到2.0 的变化 Tensorflow2.0 的架构 Tensorflow2.0 的安装(CPU和GPU ...
- Hinton老爷子CapsNet再升级,结合无监督,接近当前最佳效果
2017 年,Geoffrey Hinton 在论文<Dynamic Routing Between Capsules>中提出 CapsNet 引起了极大的关注,同时也提供了一个全新的研究 ...