sparkSessiontest
记事本内容:
打印结构:
方法1:
object SparkSessionTest { case class Person(name:String,age:Int) def main(args: Array[String]): Unit = { val sparkSession=SparkSession.builder().appName("SparkSessionTest")
.master("local[*]")
.getOrCreate()
val sparkContext=sparkSession.sparkContext
val rdd=sparkContext.textFile("D:\\temp\\person.txt")
val rowRdd=rdd.map(_.split(" ")).map(row=>Person(row(0),row(1).toInt)) import sparkSession.implicits._
rowRdd.toDF sparkSession.stop()
} }
方法2:
val sparkContext=sparkSession.sparkContext
val rdd=sparkContext.textFile("D:\\temp\\person.txt")
val schemaFiled="name,age"
val schemaString=schemaFiled.split(",")
val schema =StructType(
List(
StructField(schemaString(0),StringType,nullable = true),
StructField(schemaString(1),IntegerType,nullable = true)
)
)
val rowRdd= rdd.map(_.split("")).map(p=>Row(p(0),p(1).toInt))
val df=sparkSession.createDataFrame(rowRdd,schema)
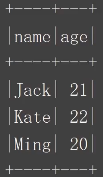
df.show()
结果展示:
parquet的优势
支持列存储+嵌套数据格式+适配多个计算框架
节省表扫描时间和反序列的时间
压缩技术稳定出色,节省存储空间
Spark操作 Parquet文件比操作CSV等普通文件的速度更快
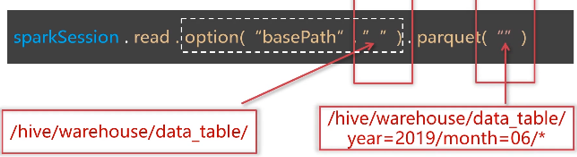
加载数据:sparkSession.read.parquet(“/nginx/20200110.parquet”)
写入数据:df.write.mode(SaveMode.Overwrite).parquet(“/path/to”)
分区文件
加载批量数据:
Df.show()//只显示前20条数据
Df.show(3)//只显示前3条数据
df.show( false)//每列可以显示多于20个字符
dt show(3, false)
Df.select (“字段1”,”字段2”).show()
Df.select(col(“”) as(“别名1”),col(“字段2”)+1).show()
df.first()//获取第一行数据,返回RoW
df.head( 3)//获取前3行数据,返回 Array Row]
df.take (3)//获取前3行数据,返回 Array[Row]
df.takeaslist(3//获取前3行数据,返回List[Row]
df.limit(3).show()//返回新的 Data Frame,不是 Action操作
Df.where(“age>21”).show()
Df.filter(“age>21”).show()
Df.where(col(“age”)>21).show()
Ds.where($”age”>21).show()
Df.where(“age=21”).show
Df.where(col(“age”)===21).show
Df.where(col(“age”)=!=21).show
Val ageFilter_1 =col(“age”)>21
Val agefilter_2=col(“age”)<25
Val ageFilter_3=agefilter_1.or(ageFilter_2)
Df.where(col(“name”)===”jack”).where(ageFilter_3)
Val ageFilter_1 =col(“age”)>21
Val ageFilter_2=col(“age”)<25
Val ageFilter_3 =ageFilter_1.ll(ageFilter_2)
Df.where(col(“name”)===”jack”)
.where(ageFitler_3)
.show
//按照身份统计人数
Df.groupBy(col(“province”))
.count
.show
按照城市,手机运营商分组统计人数并按人数排序
//方法1
Df.groupby(col(“city”),col(“”op_phone“”))
.count
.withColumnRenamed(“count”,”num”)
.orderBy(col(“num”).desc)
.show
//方法2
Ds.groupBy($”city”,$”op_phone”)
.count
.withColumnRenamed(“count”,”num”)
.sort($”num”.desc)
.show
按年统计注册用户最高的积分,以及平均积分
Df.groupBy(year(col(“add_time”)))
.agg(max(col(“total_mark”).as(“max_mark”)),
Avg(col(“total_mark”).as(“avg_mark”))
)
.show






sparkSessiontest的更多相关文章
- RDD&Dataset&DataFrame
Dataset创建 object DatasetCreation { def main(args: Array[String]): Unit = { val spark = SparkSession ...
随机推荐
- pytorch的自动求导机制 - 计算图的建立
一.计算图简介 在pytorch的官网上,可以看到一个简单的计算图示意图, 如下. import torchfrom torch.autograd import Variable x = Variab ...
- vuepress-theme-reco + Github Actions 构建静态博客,部署到第三方服务器
最新博客链接 Github链接 查看此文档前应先了解,vuepress基本操作 参考官方文档进行配置: vuepress-theme-reco VuePress SamKirkland / FTP-D ...
- JAVA-迭代器\增强型for循环。(新手)
//导入的包.import java.lang.reflect.Array;import java.util.*;//创建的一个类.public class zylx1 { //公共静态的主方法. p ...
- kerberos系列之zookeeper的认证配置
本篇博客介绍配置zookeeper的kerberos配置 一.zookeeper安装 1.解压安装包和重命名和创建数据目录 tar -zxvf /data/apache-zookeeper-3.5.5 ...
- 是时候了解Java Socket底层实现了
在Java中,提供了一系列Socket API,可以轻松建立两个主机之间的连接.读取数据,那底层到底怎么实现,很少人去关心.这其实最终还是通过调用操作系统提供得Socket接口完成(TCP/IP是由操 ...
- 阿里淘宝的S1级别bug,到底是谁的锅?
3月25日,阿里的淘宝APP在IOS系统上出现BUG: 在打开淘宝APP以后,用户就会收到系统弹窗通知:“您使用的程序是测试/内测版本,将于当地时间2020-03-28到期,到期后将无法使用,请尽快下 ...
- shell编程之变量赋值
1.变量赋值: name=lbg 等号前后不能有空格 name="Lebron James" 变量值中有空格要用双引号 echo ${name} 用${}更保险 shopt -s ...
- CBV和APIView源码分析
CBV源码分析 查看源码的方式,先查看自身,没有去找父类,父类没有就去找父父类... 自己定义的类 class Author(View): def get(self,request): back_di ...
- [ASP.NET Core 3.1]浏览器嗅探解决部分浏览器丢失Cookie问题
今天的干货长驱直入,直奔主题 看了前文的同学们应该都知道,搜狗.360等浏览器在单点登录中反复重定向,最终失败报错. 原因在于,非Chrome80+浏览器不识别Cookie上的SameSite=non ...
- JDK的sql设计不合理导致的驱动类初始化死锁问题
问题描述 当我们一个系统既需要mysql驱动,也需要oracle驱动的时候,在并发加载初始化这些驱动类的过程中产生死锁的可能性非常大,下面是一个模拟的例子,对于Thread2的实现其实是jdk里jav ...