在Keras中可视化LSTM
作者|Praneet Bomma
编译|VK
来源|https://towardsdatascience.com/visualising-lstm-activations-in-keras-b50206da96ff

你是否想知道LSTM层学到了什么?有没有想过是否有可能看到每个单元如何对最终输出做出贡献。我很好奇,试图将其可视化。在满足我好奇的神经元的同时,我偶然发现了Andrej Karpathy的博客,名为“循环神经网络的不合理有效性”。如果你想获得更深入的解释,建议你浏览他的博客。
在本文中,我们不仅将在Keras中构建文本生成模型,还将可视化生成文本时某些单元格正在查看的内容。就像CNN一样,它学习图像的一般特征,例如水平和垂直边缘,线条,斑块等。类似,在“文本生成”中,LSTM则学习特征(例如空格,大写字母,标点符号等)。 LSTM层学习每个单元中的特征。
我们将使用Lewis Carroll的《爱丽丝梦游仙境》一书作为训练数据。该模型体系结构将是一个简单的模型体系结构,在其末尾具有两个LSTM和Dropout层以及一个Dense层。
你可以在此处下载训练数据和训练好的模型权重
https://github.com/Praneet9/Visualising-LSTM-Activations

这就是我们激活单个单元格的样子。
让我们深入研究代码。
步骤1:导入所需的库
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout, CuDNNLSTM
from keras.callbacks import ModelCheckpoint
from keras.utils import np_utils
import re
# 可视化库
from IPython.display import HTML as html_print
from IPython.display import display
import keras.backend as K注意:我使用CuDNN-LSTM代替LSTM,因为它的训练速度提高了15倍。CuDNN-LSTM由CuDNN支持,只能在GPU上运行。
步骤2:读取训练资料并进行预处理
使用正则表达式,我们将使用单个空格删除多个空格。该char_to_int和int_to_char只是数字字符和字符数的映射。
# 读取数据
filename = "wonderland.txt"
raw_text = open(filename, 'r', encoding='utf-8').read()
raw_text = re.sub(r'[ ]+', ' ', raw_text)
# 创建字符到整数的映射
chars = sorted(list(set(raw_text)))
char_to_int = dict((c, i) for i, c in enumerate(chars))
int_to_char = dict((i, c) for i, c in enumerate(chars))
n_chars = len(raw_text)
n_vocab = len(chars)步骤3:准备训练资料
准备我们的数据很重要,每个输入都是一个字符序列,而输出是后面的字符。
seq_length = 100
dataX = []
dataY = []
for i in range(0, n_chars - seq_length, 1):
seq_in = raw_text[i:i + seq_length]
seq_out = raw_text[i + seq_length]
dataX.append([char_to_int[char] for char in seq_in])
dataY.append(char_to_int[seq_out])
n_patterns = len(dataX)
print("Total Patterns: ", n_patterns)
X = np.reshape(dataX, (n_patterns, seq_length, 1))
# 标准化
X = X / float(n_vocab)
# one-hot编码
y = np_utils.to_categorical(dataY)
filepath="weights-improvement-{epoch:02d}-{loss:.4f}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1, save_best_only=True, mode='min')
callbacks_list = [checkpoint]步骤4:构建模型架构
# 定义 LSTM 模型
model = Sequential()
model.add(CuDNNLSTM(512, input_shape=(X.shape[1], X.shape[2]), return_sequences=True))
model.add(Dropout(0.5))
model.add(CuDNNLSTM(512))
model.add(Dropout(0.5))
model.add(Dense(y.shape[1], activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()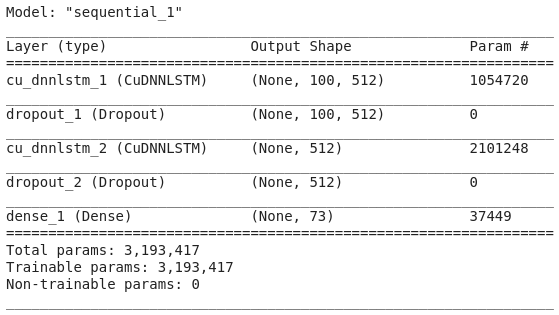
步骤5:训练模型
model.fit(X, y, epochs=300, batch_size=2048, callbacks=callbacks_list)使用Google Colab训练模型时,我无法一口气训练模型300个epoch。我必须通过缩减权重数量并再次加载它们来进行3天的训练,每天100个epoch
如果你拥有强大的GPU,则可以一次性训练300个epoch的模型。如果你不这样做,我建议你使用Colab,因为它是免费的。
你可以使用下面的代码加载模型,并从最后一点开始训练。
from keras.models import load_model
filename = "weights-improvement-303-0.2749_wonderland.hdf5"
model = load_model(filename)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 用相同的数据训练模型
model.fit(X, y, epochs=300, batch_size=2048, callbacks=callbacks_list)现在到文章最重要的部分-可视化LSTM激活。我们将需要一些功能来实际使这些可视化变得可理解。
步骤6:后端功能以获取中间层输出
正如我们在上面的步骤4中看到的那样,第一层和第三层是LSTM层。我们的目标是可视化第二LSTM层(即整个体系结构中的第三层)的输出。
Keras Backend帮助我们创建一个函数,该函数接受输入并为我们提供来自中间层的输出。我们可以使用它来创建我们自己的管道功能。这里attn_func将返回大小为512的隐藏状态向量。这将是具有512个单位的LSTM层的激活。我们可以可视化这些单元激活中的每一个,以了解它们试图解释的内容。为此,我们必须将其转换为可以表示其重要性的范围的数值。
#第三层是输出形状为LSTM层(Batch_Size, 512)
lstm = model.layers[2]
#从中间层获取输出以可视化激活
attn_func = K.function(inputs = [model.get_input_at(0), K.learning_phase()],
outputs = [lstm.output]
)步骤7:辅助功能
这些助手功能将帮助我们使用每个激活值来可视化字符序列。我们正在通过sigmoid功能传递激活,因为我们需要一个可以表示其对整个输出重要性的规模值。get_clr功能有助于获得给定值的适当颜色。
#获取html元素
def cstr(s, color='black'):
if s == ' ':
return "<text style=color:#000;padding-left:10px;background-color:{}> </text>".format(color, s)
else:
return "<text style=color:#000;background-color:{}>{} </text>".format(color, s)
# 输出html
def print_color(t):
display(html_print(''.join([cstr(ti, color=ci) for ti,ci in t])))
#选择合适的颜色
def get_clr(value):
colors = ['#85c2e1', '#89c4e2', '#95cae5', '#99cce6', '#a1d0e8'
'#b2d9ec', '#baddee', '#c2e1f0', '#eff7fb', '#f9e8e8',
'#f9e8e8', '#f9d4d4', '#f9bdbd', '#f8a8a8', '#f68f8f',
'#f47676', '#f45f5f', '#f34343', '#f33b3b', '#f42e2e']
value = int((value * 100) / 5)
return colors[value]
# sigmoid函数
def sigmoid(x):
z = 1/(1 + np.exp(-x))
return z下图显示了如何用各自的颜色表示每个值。

步骤8:获取预测
get_predictions函数随机选择一个输入种子序列,并获得该种子序列的预测序列。visualize函数将预测序列,序列中每个字符的S形值以及要可视化的单元格编号作为输入。根据输出的值,将以适当的背景色打印字符。
将Sigmoid应用于图层输出后,值在0到1的范围内。数字越接近1,它的重要性就越高。如果该数字接近于0,则意味着不会以任何主要方式对最终预测做出贡献。这些单元格的重要性由颜色表示,其中蓝色表示较低的重要性,红色表示较高的重要性。
def visualize(output_values, result_list, cell_no):
print("\nCell Number:", cell_no, "\n")
text_colours = []
for i in range(len(output_values)):
text = (result_list[i], get_clr(output_values[i][cell_no]))
text_colours.append(text)
print_color(text_colours)
# 从随机序列中获得预测
def get_predictions(data):
start = np.random.randint(0, len(data)-1)
pattern = data[start]
result_list, output_values = [], []
print("Seed:")
print("\"" + ''.join([int_to_char[value] for value in pattern]) + "\"")
print("\nGenerated:")
for i in range(1000):
#为预测下一个字符而重塑输入数组
x = np.reshape(pattern, (1, len(pattern), 1))
x = x / float(n_vocab)
# 预测
prediction = model.predict(x, verbose=0)
# LSTM激活函数
output = attn_func([x])[0][0]
output = sigmoid(output)
output_values.append(output)
# 预测字符
index = np.argmax(prediction)
result = int_to_char[index]
# 为下一个字符准备输入
seq_in = [int_to_char[value] for value in pattern]
pattern.append(index)
pattern = pattern[1:len(pattern)]
# 保存生成的字符
result_list.append(result)
return output_values, result_list步骤9:可视化激活
超过90%的单元未显示任何可理解的模式。我手动可视化了所有512个单元,并注意到其中的三个(189、435、463)显示了一些可以理解的模式。
output_values, result_list = get_predictions(dataX)
for cell_no in [189, 435, 463]:
visualize(output_values, result_list, cell_no)单元格189将激活引号内的文本,如下所示。这表示单元格在预测时要查找的内容。如下所示,这个单元格对引号之间的文本贡献很大。

引用句中的几个单词后激活了单元格435。

对于每个单词中的第一个字符,将激活单元格463。

通过更多的训练或更多的数据可以进一步改善结果。这恰恰证明了深度学习毕竟不是一个完整的黑匣子。
你可以在我的Github个人资料中得到整个代码。
https://github.com/Praneet9/Visualising-LSTM-Activations
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:
http://pytorch.panchuang.net/
OpenCV中文官方文档:
http://woshicver.com/
在Keras中可视化LSTM的更多相关文章
- Keras中使用LSTM层时设置的units参数是什么
https://www.zhihu.com/question/64470274 http://colah.github.io/posts/2015-08-Understanding-LSTMs/ ht ...
- Python中利用LSTM模型进行时间序列预测分析
时间序列模型 时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺 ...
- 通过keras例子理解LSTM 循环神经网络(RNN)
博文的翻译和实践: Understanding Stateful LSTM Recurrent Neural Networks in Python with Keras 正文 一个强大而流行的循环神经 ...
- Python机器学习笔记:深入学习Keras中Sequential模型及方法
Sequential 序贯模型 序贯模型是函数式模型的简略版,为最简单的线性.从头到尾的结构顺序,不分叉,是多个网络层的线性堆叠. Keras实现了很多层,包括core核心层,Convolution卷 ...
- keras 文本分类 LSTM
首先,对需要导入的库进行导入,读入数据后,用jieba来进行中文分词 # encoding: utf-8 #载入接下来分析用的库 import pandas as pd import numpy as ...
- keras实例学习-双向LSTM进行imdb情感分类
源码:https://github.com/keras-team/keras/blob/master/examples/imdb_bidirectional_lstm.py 及keras中文文档 1. ...
- keras: 在构建LSTM模型时,使用变长序列的方法
众所周知,LSTM的一大优势就是其能够处理变长序列.而在使用keras搭建模型时,如果直接使用LSTM层作为网络输入的第一层,需要指定输入的大小.如果需要使用变长序列,那么,只需要在LSTM层前加一个 ...
- keras中seq2seq实现
这里只是简单的一个例子 输入序列 目标序列 [13, 28, 18, 7, 9, 5] [18, 28, 13] [29, 44, 38, 15, 26, 22] [38, 44, 29] [27, ...
- keras中VGG19预训练模型的使用
keras提供了VGG19在ImageNet上的预训练权重模型文件,其他可用的模型还有VGG16.Xception.ResNet50.InceptionV3 4个. VGG19在keras中的定义: ...
随机推荐
- 在博客中显示图片_Mac版
主要是防止自己忘掉 为了解决一开始自己想在写入的博客中添加本地图片,直接链接的话在自己的电脑倒是可以显示图片,但是在别人的电脑上就没办法加载图片了,问各路大神也没人愿意解答,百度也没有想要的答案,只好 ...
- ADO.NET中DataTable类的使用
DataTable类将关系数据表示为表格形式.在创建DataTable之前,必须包含System.Data名称空间.ADO.NET提供了一个DataTable类来独立创建和使用数据表.它也可以和Dat ...
- 将mysql数据库集成到idea中
将mysql数据库集成到idea中
- meterpreter会话渗透利用常用的32个命令归纳小结
仅作渗透测试技术实验之用,请勿针对任何未授权网络和设备. 1.background命令 返回,把meterpreter后台挂起 2.session命令 session 命令可以查看已经成功获取的会话 ...
- 深度解析互联网大厂面试难题自定义@EnableXX系列
深度解析互联网大厂面试难题自定义@EnableXX系列 其实是一个@Import的设计技巧 创建注解@EnableXX(任何名称注解都行,只是这个名字好一些) XXConfiguration类不能 ...
- App崩溃监控
常见马虎导致崩溃 1 数组越界: 2 多线程问题,在子线程刷新UI: 3 主线程无响应,主线程超过系统规定的时间没有响应,就会被watchdog杀掉: 4 野指针: 崩溃信息的收集却并没有那么简单.因 ...
- 《前端之路》--- 重温 Egg.js
目录 <前端之路>--- 重温 Egg.js 一.基础功能 > 日志系统包含了 四大层面的 日志对象, 分别是 App Logger.App CoreLogger.Context L ...
- 关于地址栏url的一些小结
1.获取整个地址栏地址 //获取整个地址栏地址 var href = window.location.href; console.log(href); 以上代码就是获取整个url地址 2.获取url协 ...
- 前端---css3优化
一.视差滚动(经过优化后的代码) .front::before { content: ''; position: fixed; // 代替background-attachment width: 10 ...
- 超强图文|并发编程【等待/通知机制】就是这个feel~
你有一个思想,我有一个思想,我们交换后,一个人就有两个思想 If you can NOT explain it simply, you do NOT understand it well enough ...