官网英文版学习——RabbitMQ学习笔记(十)RabbitMQ集群
在第二节我们进行了RabbitMQ的安装,现在我们就RabbitMQ进行集群的搭建进行学习,参考官网地址是:http://www.rabbitmq.com/clustering.html
首先我们来看一下官网对集群的定义:A RabbitMQ broker is a logical grouping of one or several Erlang nodes, each running the RabbitMQ application and sharing users, virtual hosts, queues, exchanges, bindings, and runtime parameters. Sometimes we refer to the collection of nodes as a cluster.
简单翻译一下是说:RabbitMQ的broker是一个或多个Erlang节点的逻辑分组,每个节点运行RabbitMQ应用程序并共享用户、虚拟主机、队列、交换、绑定和运行时参数。有时,我们将节点集合称为集群。
集群将多个机器连接在一起,形成一个单一的逻辑代理。通信是通过Erlang消息传递进行的,因此集群中的所有节点都必须具有相同的Erlang cookie。集群中的机器之间的网络连接必须是可靠的,集群中的所有机器都必须运行相同版本的RabbitMQ和Erlang。
虚拟主机、交换器、用户和权限在集群中的所有节点上被自动镜像。队列可以位于单个节点上,也可以跨多个节点镜像。连接到集群中任何节点的客户端可以看到集群中的所有队列,即使它们不在该节点上。
通常,您将使用集群实现高可用性和提高吞吐量,并将机器放在一个位置。
集群方式:
RabbitMQ集群可以通过多种方式形成:
- 通过在配置文件中以声明的方式列出集群节点
- 声明性地使用以域名系统发现
- 以声明的方式使用AWS (EC2)实例发现(通过插件)
- 使用Kubernetes发现(通过插件)声明
- 声明性地使用基于咨询的发现(通过插件)
- 以声明的方式使用基于etcd的发现(通过插件)
集群的组成可以动态地改变。所有RabbitMQ代理都以在单个节点上运行开始。这些节点可以被连接到集群中,然后再返回到各个代理中。
集群模式(两种):
1)普通模式(默认模式):
RabbitMQ集群中节点包括内存节点、磁盘节点。内存节点就是将所有数据放在内存,磁盘节点将数据放在磁盘上。如果在投递消息时,打开了消息的持久化,那么即使是内存节点,数据还是安全的放在磁盘。那么内存节点的性能只能体现在资源管理上,比如增加或删除队列(queue),虚拟主机(vrtual hosts),交换机(exchange)等,发送和接受message速度同磁盘节点一样。一个集群至少要有一个磁盘节点。一个rabbitmq集群中可以共享user,vhost,exchange等,所有的数据和状态都是必须在所有节点上复制的,对于queue根据集群模式不同,应该有不同的表现。在集群模式下只要有任何一个节点能够工作,RabbitMQ集群对外就能提供服务。
默认的集群模式,queue创建之后,如果没有其它policy,则queue就会按照普通模式集群。对于Queue来说,消息实体只存在于其中一个节点,A、B两个节点仅有相同的元数据,即队列结构,但队列的元数据仅保存有一份,即创建该队列的rabbitmq节点(A节点),当A节点宕机,你可以去其B节点查看,./rabbitmqctl list_queues发现该队列已经丢失,但声明的exchange还存在。
当消息进入A节点的Queue中后,consumer从B节点拉取时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过B发送给consumer,所以consumer应平均连接每一个节点,从中取消息。该模式存在一个问题就是当A节点故障后,B节点无法取到A节点中还未消费的消息实体。如果做了队列持久化或消息持久化,那么得等A节点恢复,然后才可被消费,并且在A节点恢复之前其它节点不能再创建A节点已经创建过的持久队列;如果没有持久化的话,消息就会失丢。这种模式更适合非持久化队列,只有该队列是非持久的,客户端才能重新连接到集群里的其他节点,并重新创建队列。假如该队列是持久化的,那么唯一办法是将故障节点恢复起来。
为什么RabbitMQ不将队列复制到集群里每个节点呢?这与它的集群的设计本意相冲突,集群的设计目的就是增加更多节点时,能线性的增加性能(CPU、内存)和容量(内存、磁盘)。当然RabbitMQ新版本集群也支持队列复制(有个选项可以配置)。比如在有五个节点的集群里,可以指定某个队列的内容在2个节点上进行存储,从而在性能与高可用性之间取得一个平衡(应该就是指镜像模式)。
2)镜像模式:
该模式解决了上述问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在consumer取数据时临时拉取。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用,一个队列想做成镜像队列,需要先设置policy,然后客户端创建队列的时候,rabbitmq集群根据“队列名称”自动设置是普通集群模式或镜像队列。
下面开始两种模式的集群,我们的集群环境仍然是之前一直采用的几个虚拟机中进行
在linux下centos6.7上进行,
一、在三台虚拟机上分别安装rabbitMQ
安装可以参考本人前面的教程
这里我们对上面链接中安装内容做个简化,整理如下:
1.添加存储库条目
wget https://packages.erlang-solutions.com/erlang-solutions-1.0-1.noarch.rpm
rpm -Uvh erlang-solutions-1.0-1.noarch.rpm

2.安装erlang,安装完成如下(安装有些慢需要些时间大约6~10min):
sudo yum install erlang
3.安装centos的epel的扩展源
yum -y install epel-release

4.之后执行yum -y install socat重新 安装socat

5.安装rabbitmq
rpm --import https://dl.bintray.com/rabbitmq/Keys/rabbitmq-release-signing-key.asc
# this example assumes the CentOS 7 version of the package
yum install rabbitmq-server-3.7.6-1.el7.noarch.rpm
官网安装的是3.7.6-1.e17如上图,结合本centos是32位字节,下载3.7.6-1.e16,并上传到usr/local/目录下,安装运行
yum install rabbitmq-server-3.7.6-1.e16.noarch.rpm成功。

6、启动RabbitMQ测试
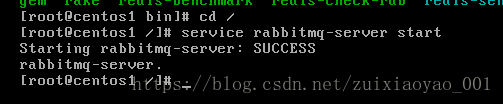
显示启动成功,OK!
附上网上查找的有关rabbitMQ命令
service rabbitmq-server start 启动
service rabbitmq-server stop 停止
service rabbitmq-server restart 重启
二、
在上述的三台机器上安装rabbitmq完成之后,你可以看到你的机器中有如下1个文件。路径在$HOME中或者在/var/lib/rabbitmq中,文件名称为.erlang.cookie,他是一个隐藏文件。

那么这文件存储的内容是什么,是做什么用的呢?
该文件是集群节点进行通信的验证密钥,所有节点必须一致。RabbitMQ的集群是依赖erlang集群,而erlang集群是通过这个cookie进行通信认证的,拷完后重启下RabbitMQ。因此我们做集群的第一步就是干cookie。怎么干?
1、必须使集群中也就是上面三台机器中的这两台机器的.erlang.cookie文件中cookie值一致,且权限为owner只读。
三台机子三个文件内容分别是


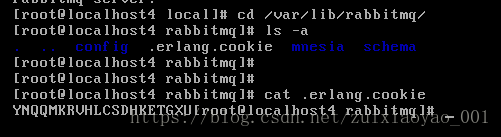
修改三台机子文件中的内容完全一样即可,不管采用那台机子上的均可,这里本博主采用第一个文件TUWHXTFBJHBQTONCAXCA
修改文件权限 chmod 600 /var/lib/.erlang.cookie
进入安装的sbin下查看目录,不知道sbin安装目录可以输入命令whereis rabbitmq-server查找

cd /usr/sbin/后查看状态
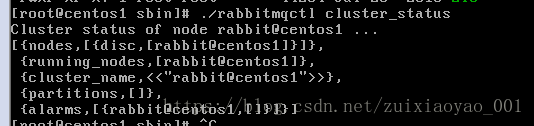
此时直接去查看其他两个节点状态发现报错,第二天早上开机后竟然好了,肯能是重启的缘故,先上图其他两台的状态

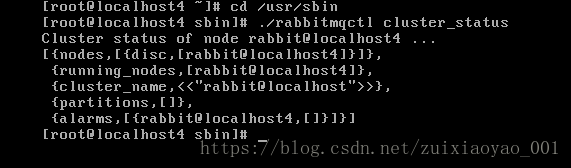
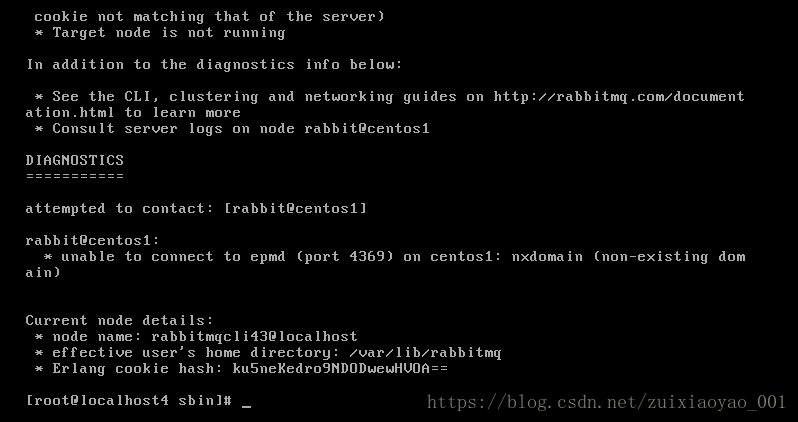
从上面可以看到,本博主前两台主机名是一样的,这是由于本博主之前搭建虚拟机时采用的复制虚拟机,导致虚拟机主机名一致,为了进行rabbitMQ集群,我们需要对三台主机设置主机名并进行绑定,本博主决定分别设置其主机名为rabbitA,rabbitB和rabbitC,并且一定要确保集群中每台节点机器上的hosts文件应包含集群内所有节点的信息以保证互相解析。在未进行配置的情况下,当我们在加入节点到另一个节点时报错如下:
接下来我们进行每台主机的hosts配置:



注意也要同时修改

然后重启生效如下,主机名变为rabbitA,:
设置完成,我们相互ping一下,看是否可以相互连接
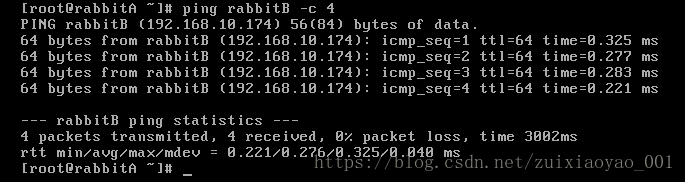
我们再次加入节点时,仍然报错如下:

到此,根据网上各种情况排查发现都不行,什么情况呢,主机名,cookie值,防火墙都排出了,就剩安装顺序了,莫非真的必须先更改主机名,再安装rabbitmq才行吗。各位大神,知道的留个言
官网英文版学习——RabbitMQ学习笔记(十)RabbitMQ集群的更多相关文章
- 官网英文版学习——RabbitMQ学习笔记(一)认识RabbitMQ
鉴于目前中文的RabbitMQ教程很缺,本博主虽然买了一本rabbitMQ的书,遗憾的是该书的代码用的不是java语言,看起来也有些不爽,且网友们不同人学习所写不同,本博主看的有些地方不太理想,为此本 ...
- 利用JQ实现的,高仿 彩虹岛官网导航栏(学习HTML过程中的小记录)
利用JQ实现的,高仿 彩虹岛官网导航栏(学习HTML过程中的小记录) 作者:王可利(Star·星星) 总结: 今天学习的jQ类库的使用,代码重复的比较多需要完善.严格区分大小写,在 $(" ...
- Unity shader 官网文档全方位学习(一)
转载:https://my.oschina.net/u/138823/blog/181131 摘要: 这篇文章主要介绍Surface Shaders基础及Examples详尽解析 What?? Sha ...
- Redis学习笔记八:集群模式
作者:Grey 原文地址:Redis学习笔记八:集群模式 前面提到的Redis学习笔记七:主从复制和哨兵只能解决Redis的单点压力大和单点故障问题,接下来要讲的Redis Cluster模式,主要是 ...
- ZooKeeper学习笔记一:集群搭建
作者:Grey 原文地址:ZooKeeper学习笔记一:集群搭建 说明 单机版的zk安装和运行参考:https://zookeeper.apache.org/doc/r3.6.3/zookeeperS ...
- 深入学习Redis(5):集群
前言 在前面的文章中,已经介绍了Redis的几种高可用技术:持久化.主从复制和哨兵,但这些方案仍有不足,其中最主要的问题是存储能力受单机限制,以及无法实现写操作的负载均衡. Redis集群解决了上述问 ...
- (十)RabbitMQ消息队列-高可用集群部署实战
原文:(十)RabbitMQ消息队列-高可用集群部署实战 前几章讲到RabbitMQ单主机模式的搭建和使用,我们在实际生产环境中出于对性能还有可用性的考虑会采用集群的模式来部署RabbitMQ. Ra ...
- 《Apache kafka实战》读书笔记-管理Kafka集群安全之ACL篇
<Apache kafka实战>读书笔记-管理Kafka集群安全之ACL篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家能看到这篇博客的小伙伴,估计你对kaf ...
- RabbitMQ(四):使用Docker构建RabbitMQ高可用负载均衡集群
本文使用Docker搭建RabbitMQ集群,然后使用HAProxy做负载均衡,最后使用KeepAlived实现集群高可用,从而搭建起来一个完成了RabbitMQ高可用负载均衡集群.受限于自身条件,本 ...
随机推荐
- Linux centosVMware Apache 配置防盗链、访问控制Directory、访问控制FilesMatch
一.配置防盗链 通过限制referer来实现防盗链的功能 配置文件增加如下内容 vim /usr/local/apache2.4/conf/extra/httpd-vhosts.conf //改为如下 ...
- json 常用的方法
JSON 是用于存储和传输数据的格式. JSON 通常用于服务端向网页传递数据 . ------- 菜鸟网 1. JSON.parse() :用于将一个 JSON 字符串转换为 JavaScrip ...
- 38 java 使用标签跳出多层嵌套循环
public class Interview { public static void main(String[] args) { //使用带标签的break跳出多层嵌套循环 Boolean flag ...
- intelliJ IDEA 全屏键盘手
从MyEclipse到IntelliJ IDEA --让你脱键盘,全键盘操作 从MyEclipse转战到IntelliJ IDEA的经历 我一个朋友写了一篇"从Eclipse到Android ...
- 设计模式课程 设计模式精讲 16-2,3 代理模式Coding-静态代理-1
1 代码演练 1.1 代码演练1(静态代理之分库操作) 1 代码演练 1.1 代码演练1(静态代理之分库操作) 需求: 订单管理,模拟前置后置方法,模拟分库管理 重点: 重点看订单静态代理,动态数据源 ...
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 表单:表单帮助文本
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- 病毒[POI2000](AC自动机+搜索)
题目链接:病毒[POI2000] 我们假设已经有一个无限长的串满足要求,那如果我们拿它去匹配会发生什么? 它会一直在Trie树和fail树上转圈,一定经过根节点且不会经过病毒字符串结束的节点. 所以如 ...
- 关于Java构造类与对象的思考
简单记录一下Java构造类与对象时的流程以及this和super对于特殊例子的分析. 首先,接着昨天的问题,我做出了几个变形: Pic1.原版: Pic2.去掉了T.foo方法中的this关键字: P ...
- tcpdump 抓取MySQL SQL语句脚本
#!/bin/bash#this script used montor mysql network traffic.echo sqltcpdump -i bond0 -s 0 -l -w - dst ...
- mutiset的简单介绍转载
原文链接:https://blog.csdn.net/sodacoco/article/details/84798621 c++语言中,multiset是<set>库中一个非 ...