PRaCtice[1]
ID-3学习 代码实现
该项目采用了业界领先的 TDD(TreeNewBee-Driven Development,吹牛逼导向开发模式) 方式。-Rrrrraulista
1. 样例数据集
样例数据集来自周老师《机器学习》上的“西瓜数据集2.0”
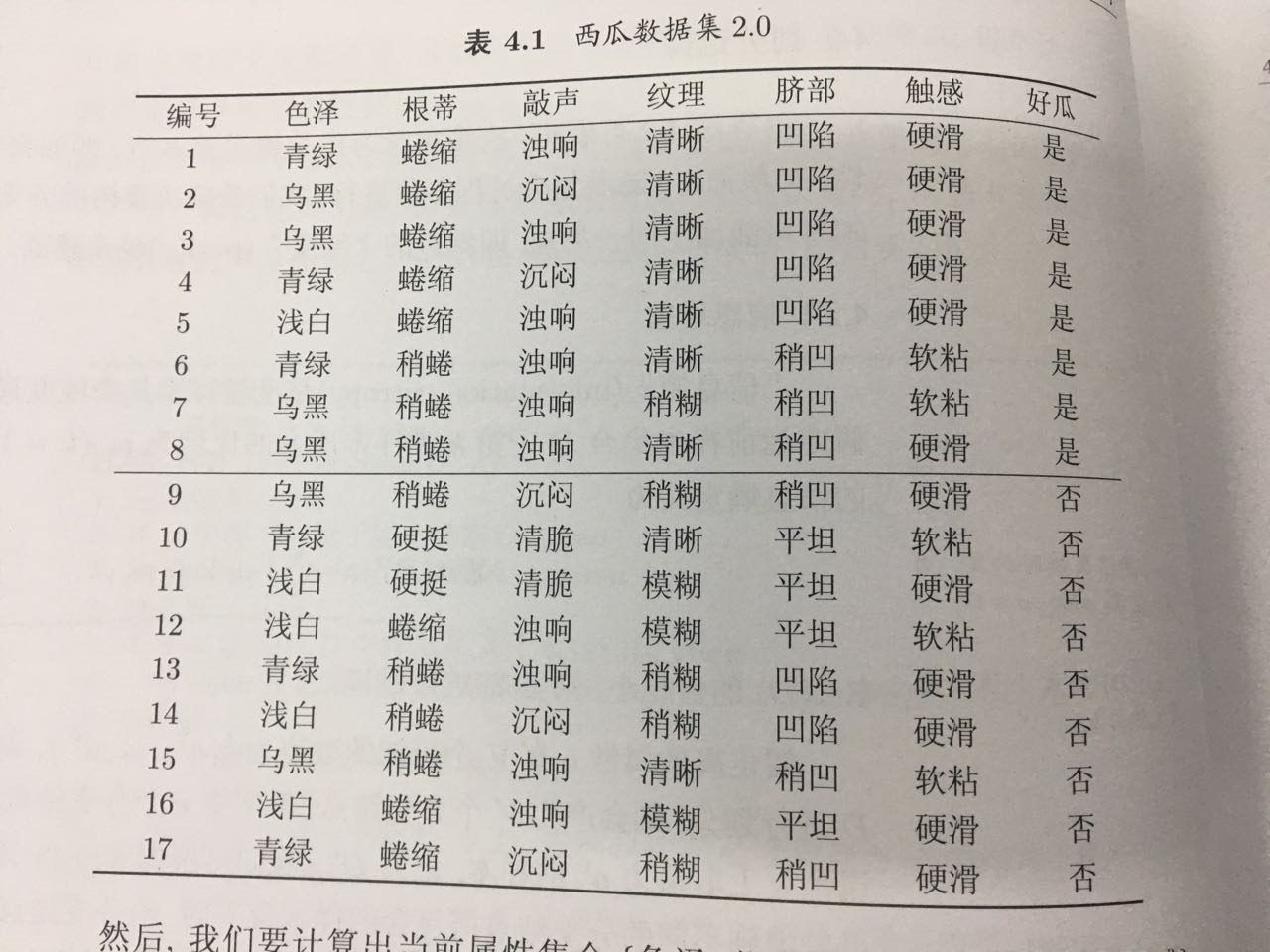
数据结构定义如下:
结构体类型定义//update
typedef struct SampleNode{
int SeqNum; //样例编号
bool Type; //样例类别(true 好瓜;false 非好瓜)
int Color; //色泽 (1 青绿; 2 乌黑; 3 浅白)
int Root; //根部 (1 蜷缩; 2 稍微蜷缩; 3 硬挺)
int Sounds; //敲击声音 (1 沉闷; 2 浊响; 3 清脆)
int Style; //纹理 (1 清晰; 2 稍微模糊; 3 模糊)
int Struct; //脐部特性 (1 凹陷; 2 稍凹; 3 平坦)
int Touch; //触感 (1 硬滑; 2 软粘;)
};
SampleNode sample[17]={
{ 1 , true , 1 , 1 , 2 , 1 , 1 , 1 },
{ 2 , true , 2 , 1 , 1 , 1 , 1 , 1 },
{ 3 , true , 2 , 1 , 2 , 1 , 1 , 1 },
{ 4 , true , 1 , 1 , 1 , 1 , 1 , 1 },
{ 5 , true , 3 , 1 , 2 , 1 , 1 , 1 },
{ 6 , true , 1 , 2 , 2 , 1 , 2 , 2 },
{ 7 , true , 2 , 2 , 2 , 2 , 2 , 2 },
{ 8 , true , 2 , 2 , 2 , 1 , 2 , 1 },
{ 9 , false , 2 , 2 , 1 , 2 , 2 , 1},
{ 10 , false , 1 , 3 , 3 , 1 , 3 , 2},
{ 11 , false , 3 , 3 , 3 , 3 , 3 , 1},
{ 12 , false , 3 , 1 , 2 , 3 , 3 , 2},
{ 13 , false , 1 , 2 , 2 , 2 , 1 , 1},
{ 14 , false , 3 , 2 , 1 , 2 , 1 , 1},
{ 15 , false , 2 , 2 , 2 , 1 , 2 , 2},
{ 16 , false , 3 , 1 , 2 , 3 , 3 , 1},
{ 17 , false , 1 , 1 , 1 , 2 , 2 , 1},
};
二维数组实现方法
int data[17][7]{//整数类型西瓜数据集二维数组(类别,色泽,根部,声音,纹路,脐部,触感)
{1 , 1 , 1 , 2 , 1 , 1 , 1},
{1 , 2 , 1 , 1 , 1 , 1 , 1},
{1 , 2 , 1 , 2 , 1 , 1 , 1},
{1 , 1 , 1 , 1 , 1 , 1 , 1},
{1 , 3 , 1 , 2 , 1 , 1 , 1},
{1 , 1 , 2 , 2 , 1 , 2 , 2},
{1 , 2 , 2 , 2 , 2 , 2 , 2},
{1 , 2 , 2 , 2 , 1 , 2 , 1},
{0 , 2 , 2 , 1 , 2 , 2 , 1},
{0 , 1 , 3 , 3 , 1 , 3 , 2},
{0 , 3 , 3 , 3 , 3 , 3 , 1},
{0 , 3 , 1 , 2 , 3 , 3 , 2},
{0 , 1 , 2 , 2 , 2 , 1 , 1},
{0 , 3 , 2 , 1 , 2 , 1 , 1},
{0 , 2 , 2 , 2 , 1 , 2 , 2},
{0 , 3 , 1 , 2 , 3 , 3 , 1},
{0 , 1 , 1 , 1 , 2 , 2 , 1},
};
2.信息熵的计算
在二维数组构成的数据集上,先写出对于样本类别的信息熵地计算的基础上,逐步修改,使其具备复用性。
double Entropy(int data[17][7]); //Declaration of the function
double Entropy(int data[17][7]){ //to calculate the entropy of dataset
int trueNum=0;
for(int i=0;i<17;i++){ //count the number of TRUE numbers, which means 好瓜
if(data[i][0]==1){
trueNum++;
}else{
continue;
}
}
int falseNum=17-trueNum; // Total - true.num = false.num
double p1=trueNum/17.0;
double p2=falseNum/17.0;
if(p1!=0){ //define that 0*log_2(0) = 0
p1=-1*(p1*(log(p1)/log(2)));
}
if(p2!=0){
p2=-1*(p2*(log(p2)/log(2)));
}
double Ent=p1+p2;
return Ent;
}
//main():double ent=Entropy(data);

可以看到,该段代码成功计算了总体数据集的信息熵约为 0.998(与书上数值相同),但是该段代码默认了数据集长度为17,无法应用于子集合计算,同时传递的参数固定(二维数组),如果不解决该问题,则声明函数无意义,于是下面着手修改,使该函数更加具备复用性。
- 首先为了方便计算数组长度,人为加入数组下界,最后一行所有元素赋值为“-1”
{-1 ,-1 ,-1 ,-1 ,-1 ,-1 ,-1},
- 这样做能简化程序。
而在此基础上使用如下代码
int SetLength=0;
for(int i=0;num[i][0]!=-1;i++){
SetLength++;
}
可以实现在函数内计算二维数组的行数,提高了数组的复用性能。
//通过这个函数可以计算出数据集种某个属性具有多少种可能取值
int TypeNum(int set[][7],int att){
int SetLength=0; //计算出二维数组行数
for(int i=0;set[i][0]!=-1;i++){
SetLength++;
}
printf("\ntesta=%d",SetLength); //测试用
for(int i=0;i<SetLength;i++){
for(int j=i+1;j<SetLength;j++){
if(set[i][att]==set[j][att]){
SetLength--;
break;
}
}
}
printf("\ntestb=%d",SetLength); //测试用testb
return SetLength;
}

//修改后的信息熵计算函数如下所示
double Entropy(int num[][7]){//计算数据关于的类别的信息熵
int trueNum=0;
int SetLength=0; //计算出了二维数组的行数
for(int i=0;num[i][0]!=-1;i++){
SetLength++;
}
for(int i=0;i<SetLength;i++){
if(num[i][0]==1){
trueNum++;
}else{
continue;
}
}
int falseNum=SetLength-trueNum;
double p1=(double)trueNum/SetLength;
double p2=(double)falseNum/SetLength;
if(p1!=0){
p1=-(p1*(log(p1)/log(2)));
}
if(p2!=0){
p2=-(p2*(log(p2)/log(2)));
}
double Ent=p1+p2;
return Ent;
}
PRaCtice[1]的更多相关文章
- Pramp mock interview (4th practice): Matrix Spiral Print
March 16, 2016 Problem statement:Given a 2D array (matrix) named M, print all items of M in a spiral ...
- Atitit 数据存储视图的最佳实际best practice attilax总结
Atitit 数据存储视图的最佳实际best practice attilax总结 1.1. 视图优点:可读性的提升1 1.2. 结论 本着可读性优先于性能的原则,面向人类编程优先于面向机器编程,应 ...
- The Practice of .NET Cross-Platforms
0x01 Preface This post is mainly to share the technologies on my practice about the .NET Cross-Platf ...
- Exercise 24: More Practice
puts "Let's practice everything." puts 'You\'d need to know \'bout escapes with \\ that do ...
- ConCurrent in Practice小记 (3)
ConCurrent in Practice小记 (3) 高级同步技巧 Semaphore Semaphore信号量,据说是Dijkstra大神发明的.内部维护一个许可集(Permits Set),用 ...
- ConCurrent in Practice小记 (2)
Java-ConCurrent2.html :first-child{margin-top:0!important}img.plugin{box-shadow:0 1px 3px rgba(0,0,0 ...
- ConCurrent in Practice小记 (1)
ConCurrent in Practice小记 (1) 杂记,随书自己写的笔记: 综述问题 1.线程允许在同一个进程中的资源,包括共享内存,内存句柄,文件句柄.但是每个进程有自己的程序计数器,栈和局 ...
- 1.2 基础知识——关于猪皮(GP,Generic Practice)
摘要: 这是<CMMI快乐之旅>系列文章之一.说起猪皮(GP,Generic Practice),真的让人又爱又恨,中文翻译叫通用实践.CMMI标准中每个级别包含几个PA,每个PA又包含几 ...
- 2015年第2本(英文第1本):《The Practice of Programming》
2015年计划透析10本英文原著,最开始选定的第一本英文书是<Who Moved my Cheese>,可是这本书实在是太短.太简单了,总体的意思就是要顺应变化,要跳出自己的舒适区,全文不 ...
- Java Concurrency In Practice -Chapter 2 Thread Safety
Writing thread-safe code is managing access to state and in particular to shared, mutable state. Obj ...
随机推荐
- html_位置偏移属性position
定位属性 位置属性position:static.relative.absolute.fixed 偏移属性:top.bottom.left.right 浮动定位属性:float/clear 1.浮动定 ...
- Java8集合框架——集合工具类Arrays内部方法浅析
java.util.Arrays 备注:本文只对 Java8 中的 java.util.Arrays 中提供的基本功能进行大致介绍,并没有对其具体的实现原理进行深入的探讨和分析.详情可自己深入观摩源码 ...
- 程序员用 Python 扒出 B 站那些“惊为天人”的UP主!
前言 ! 近期B站的跨年晚会因其独特的创意席卷各大视频网站,给公司带来了极大的正面影响,股价也同时大涨,想必大家都在后悔没有早点买B站的股票: 然而今天我们要讨论的不是B站的跨年晚会,而是B站 ...
- Maven--配置 Maven 从 Nexus 下载构件
在 POM 中配置: <project> ... <repositories> <repository> <id>nexus</id> &l ...
- zabbix几个配置的关系
- Paper Review: Epigenetic Landscape, Cell Differentiation 02
I'll share another review paper about Epigenetic Landscape, it comes from Nature Review, published i ...
- Wallet file not specified (must request wallet RPC through /wallet/<filename> uri-path). BitcoinJSONRPCClient异常、及其他异常
1.异常信息 Wallet file not specified (must request wallet RPC through /wallet/<filename> uri-path) ...
- Maven--归类依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/20 ...
- Linux文件共享的实现方式
前两天跟老师去北京开了一个会议,好久没学习了,今天才回学校,其中的辛酸就不说了.来正文: 1.什么是文件共享 (1).文件共享就是同一个文件(同一个文件指的是同一个inode,同一个pathname) ...
- vi——终端中的编辑器
vi--终端中的编辑器 目标 vi 简介 打开和新建文件 三种工作模式 常用命令 分屏命令 常用命令速查图 01. vi 简介 1.1 学习 vi 的目的 在工作中,要对 服务器 上的文件进行 简单 ...