吴裕雄--天生自然python学习笔记:抓取网络公开数据
当前,有许多政府或企事业单位会在网上为公众提供相关的公开数据。以 http://api.help.bj.cn/api/均 .cn/api /网站为例,打开这个链接,大家可以看到多种可供调用的数据 。
进入 http://api.help.bj.cn/api/网站,单击“空气质量 API ” 。

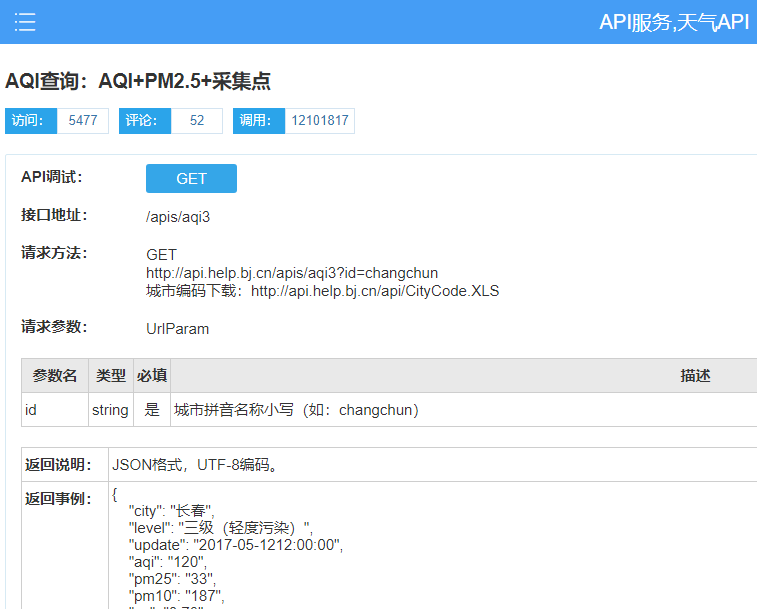

我们可以看到其中提供的数据格式为 JSON 格式
通过上图所示的接口地址,
apis/ aqilist/ 。 其中数据结构如下 : 可知保存该数据的 完整链接为 http://api.help.bj.cn/api/?id=56
数据格式如下:


from bs4 import BeautifulSoup
import sqlite3,ast,hashlib,os,requests conn = sqlite3.connect('E:\\DataBasePM25.sqlite') # 建立数据库连接
cursor = conn.cursor() # 建立 cursor 对象
# 建立一个数据表
sqlstr='''
CREATE TABLE IF NOT EXISTS TablePM25 ("no" INTEGER PRIMARY KEY AUTOINCREMENT
NOT NULL UNIQUE ,"SiteName" TEXT NOT NULL ,"PM25" INTEGER)
'''
cursor.execute(sqlstr)
http://api.help.bj.cn/apis/aqilist/

url = "http://api.help.bj.cn/apis/aqilist/"
html=requests.get(url).text.encode('utf-8-sig') # 读取网页原始码
# 判断网页是否更新
md5 = hashlib.md5(html).hexdigest()
old_md5 = ""
if os.path.exists('F:\\pythonBase\\pythonex\\ch06\\old_md5-.txt'):
with open('F:\\pythonBase\\pythonex\\ch06\\old_md5-.txt', 'r') as f:
old_md5 = f.read()
with open('F:\\pythonBase\\pythonex\\ch06\\old_md5-.txt', 'w') as f:
f.write(md5)
print("old_md5="+old_md5+";"+"md5="+md5) #显示新老md5码进行观察

if md5 != old_md5:
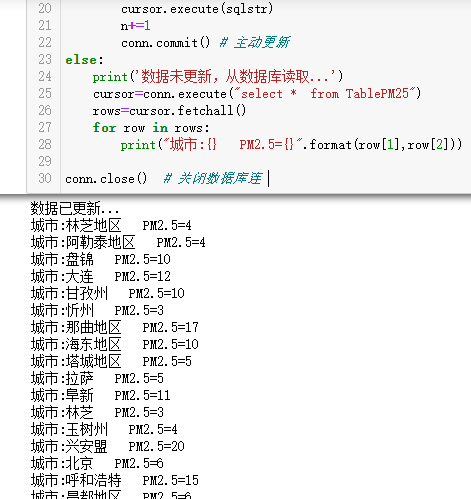
print('数据已更新...')
sp=BeautifulSoup(html,'html.parser') #解析网页内容
jsondata = ast.literal_eval(sp.text) #此时jscondata取到的是字典类型数据
# 删除数据表内容
js1=jsondata.get("aqidata") #取出字典数据中的aqidata项的值(值是列表)
conn.execute("delete from TablePM25")
conn.commit()
n=1
for city in js1: #city此时是列表js1中的第一条字典数据
CityName=city["city"] #取出city字典数据中的值为"city"的key
if(city["pm2_5"]==""):
PM25=0
else:
PM25=int(city["pm2_5"])
# PM25=0 if city["pm2_5"] == "" else int(city["pm2_5"]) #如果city字典中的key对应的value为空,则PM25=0,否则,把PM25=value
print("城市:{} PM2.5={}".format(CityName,PM25)) #显示城市对应的名称与PM2.5值
# 新增一笔记录
sqlstr="insert into TablePM25 values({},'{}',{})" .format(n,CityName,PM25)
cursor.execute(sqlstr)
n+=1
conn.commit() # 主动更新
else:
print('数据未更新,从数据库读取...')
cursor=conn.execute("select * from TablePM25")
rows=cursor.fetchall()
for row in rows:
print("城市:{} PM2.5={}".format(row[1],row[2])) conn.close() # 关闭数据库连
吴裕雄--天生自然python学习笔记:抓取网络公开数据的更多相关文章
- 吴裕雄--天生自然python学习笔记:pandas模块导入数据
有时候,手工生成 Pandas 的 DataFrame 数据是件非常麻烦的事情,所以我们通 常会先把数据保存在 Excel 或数据库中,然后再把数据导入 Pandas . 另 一种情况是抓 取网页中成 ...
- 吴裕雄--天生自然python学习笔记:pandas模块DataFrame 数据的修改及排序
import pandas as pd datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]] ...
- 吴裕雄--天生自然python学习笔记:Python3 网络编程
Python 提供了两个级别访问的网络服务.: 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统Socket接口的全部方法. 高级别的网络 ...
- 吴裕雄--天生自然python学习笔记:编写网络爬虫代码获取指定网站的图片
我们经常会在网上搜索井下载图片,然而一张一张地下载就太麻烦了,本案例 就是通过网络爬虫技术, 一次性下载该网站所有的图片并保存 . 网站图片下载并保存 将指定网站的 .jpg 和 .png 格式的图片 ...
- 吴裕雄--天生自然python学习笔记:WEB数据抓取与分析
Web 数据抓取技术具有非常巨大的应用需求及价值, 用 Python 在网页上收集数据,不仅抓取数据的操作简单, 而且其数据分析功能也十分强大. 通过 Python 的时lib 组件中的 urlpar ...
- 吴裕雄--天生自然python学习笔记:python通过“任务计划程序”实现定时自动下载或更新运行 PM2.5 数据抓取程序数据
在 Windows 任务计划程序中,设置每隔 30 分钟自动抓取 PM2.5 数据,井保存 在 SQLite 数据库中 . import sqlite3,ast,requests,os from bs ...
- 吴裕雄--天生自然python学习笔记:python实现自动网页测试
Python 可实现的网页测试的功能十分强大,甚至能通 过编程来实现让绝大多数的测试过程自动化. 这对很多开 发者来说,绝对是不可多得的神器. hash lib 纽件可以判别文件是否有过更改,只需要用 ...
- 吴裕雄--天生自然python学习笔记:python 用 Open CV抓取摄像头视频图像
Open CV 除了可以读取.显示静态图片外 , 还可 以加载及播放动态影片, 以 及 读取内置或外接摄像头的图像信息 . 很多笔记本电脑都具有摄像头 , OpenCV 可通过 VideoC aptu ...
- 吴裕雄--天生自然python学习笔记:python 用 Open CV抓取脸部图形及保存
将面部的范围识别出来后,可以对识别出来的部分进行抓取.抓取一张图片中 的部分图形是通过 pillow 包中的 crop 方法来实现的 我们首先学习用 pillow 包来读取图片文件,语法为: 例如,打 ...
- 吴裕雄--天生自然python学习笔记:pandas模块强大的数据处理套件
用 Python 进行数据分析处理,其中最炫酷的就属 Pa ndas 套件了 . 比如,如果我 们通过 Requests 及 Beautifulsoup 来抓取网页中的表格数据 , 需要进行较复 杂的 ...
随机推荐
- {转}Java 字符串分割三种方法
http://www.chenwg.com/java/java-%E5%AD%97%E7%AC%A6%E4%B8%B2%E5%88%86%E5%89%B2%E4%B8%89%E7%A7%8D%E6%9 ...
- ES系列之Promise async 和 await
概述 promise是异步编程的一种解决方案,比传统的解决方案—回调函数和事件—更合理更强大. 所谓的promise就是一个容器,里面保存着某个未来才会结束的事件(通常是一个异步操作的结果). Pro ...
- [转]Log4j使用总结
Log4j使用总结 一.介绍 Log4j是Apache的一个开放源代码项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台.文件.GUI组件.甚至是套接口服务 器.NT的事件记录器. ...
- JOIN US | 京东云诚聘技术精英
清新的办公区域感受自然的气息,温馨的团队为你我放飞青春的理想 上有天文下有地理的阅读区域 各类图书提供借阅 绿植环绕生机勃勃的会客区域洋溢青春 [高级Java工程师] 职位描述: 参与云计算相关平台/ ...
- 谈Web前端-html
什么是HTML? HTML 是用来描述网页的一种语言: HTML 值得是超文本标记语言:Hyper Text Markup Language HTML 不是一种编程语言,而是一种标 ...
- Python说文解字_杂谈07
1. 深入dict from collections.abc import Mapping,MutableMapping # dict 属于mapping类型 a = {} print(isinsta ...
- Creo 2.0 Toolkit 解锁的问题
近期开发Creo Toolkit遇到一个问题,在自己本机开发完成后运行并无问题,但是如果拿去给别人的机子运行会报出 提示“creo ToolKit应用程序在分配到您的地址之前未被解锁”,在与PTC 技 ...
- //使用PDO连接mysql数据库
<?php //使用PDO连接mysql数据库 class pdo_con{ var $dsn = 'mysql:dbname=test; host:127.0.0.1'; va ...
- 在scala命令行中加入类库
在scala命令行中加入scala的类库. scala -toolcp $HOME/.ivy2/cache/org.scalanlp/breeze_2.12/jars/breeze_2.12-0.13 ...
- 吴裕雄--天生自然 PYTHON3开发学习:运算符
#!/usr/bin/python3 a = 21 b = 10 c = 0 c = a + b print ("1 - c 的值为:", c) c = a - b print ( ...