蛋白质修饰|phosphors|mascot+X|
生物医学大数据
重点:蛋白质定量
新蛋白可以是全新的蛋白质,也可以是知结构但未知功能的蛋白质,也可以是知道结构有新功能的蛋白质。
新蛋白鉴定可以使用以下方法。
基于基因组,可以基因组中的coding区数据库变成理论上的蛋白质数据库,利用密码子翻译出氨基酸,为准确可以有三种版本,可以敲除1个碱基,2个碱基,3个碱基等,同时考虑正反链因素,就有3*2=6种可能性。基于转录组翻译情况,采用搜索已知蛋白质信息数据库,准确率高。denovo方法,即从头测序的综合比较方法,可信度基于打分值或p-value等,
可以综合使用以上方法。
拿到原始数据后,因为许多蛋白质低峰度的部分不易被MSMR察觉,同时分析时是分时段取样,量更少,更加不易定量,所以将此数据过滤。可以使用pFind进行开放式搜索以先查全后查准的原则,为了缩小大误差而搜库,为了缩小小误差而过滤。
蛋白质鉴定概率计算是得到的置信度基于数据导向不是研究导向,即没有对单个蛋白做鉴定概率的计算,只有对同一批次数据所做的计算,同时不能直接合并不同数据处理后的数据。这也是多批次质控需要注意的内容。多搜索引擎使用2个引擎最佳,组合模式是mascot+X。
蛋白质翻译后会进行修饰。关于修饰的的现状是低谱图鉴定率,即蛋白质修饰没鉴定到,因此这些无法识别的修饰使得蛋白表达量被低估。修饰分为体内修饰、体外修饰和氨基酸突变,体内修饰是自然情况,翻译后修饰,大部分修饰是体内修饰。体外修饰是人为修饰,在实验研究中使用。氨基酸突变是通过氨基酸磷酸化扩大蛋白质种类。
具体而言,磷酸化有10^4 or 10^5种,泛素化可规模化鉴定,糖基化比较复杂,难以鉴定。
修饰鉴定原理是将正常和修饰两种谱图比对,y值变大则证明修饰存在。鉴定困难在于修饰种类多,修饰量少低丰度难察觉,修饰往往在动态变化,比如磷酸化的种类是发生或不发生^位点数。修饰研究的内容,有以下四个方面,包括修饰鉴定,修饰定量,修饰作用网络,新修饰的鉴定。
常规修饰鉴定流程用于对已存在的修饰进行鉴定:

首先指定修饰类型,修饰类型包括固定修饰和可变修饰,固定修饰是某位点100%发生修饰,可变修饰是某位点不一定发生修饰。通过数据库搜索,找到该修饰的修饰类型、修饰肽段和修饰位点。在质控时,对于体外修饰可以直接肽段质检;对于体内修饰,高丰度蛋白可以将修饰与非修饰分开再肽段质检,对于低丰度蛋白先卡质量值后肽段质检。肽段质控后进行位点质控,eg:phosphors软件可针对磷酸化修饰的鉴定。
探索新修饰可采用非限制性修饰鉴定:
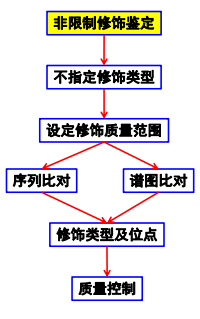
虽然不指定修饰类型,但规定修饰质量范围,通过与数据库中存在修饰信息进行序列比对或图谱比对,找到修饰类型和修饰位点,最后质控。
可以综合使用以上两种方法,取少样本加入不指定修饰类型,然后得到修饰类型,根据得到的修饰类型加入到常规修饰鉴定的流程中去,从而指定修饰类型。常用软件有mascot。
虽然可变修饰多使得搜库的灵敏度下降,但是首先保证准确度。可使用多批次搜库策略,即每次一种修饰作为一次搜寻,有n种修饰则并行n次搜寻,而不是N种修饰同时搜寻。
修饰鉴定与生物学过程,通过测得代谢途径中的所有物质的修饰来解释生物学过程。
蛋白质修饰|phosphors|mascot+X|的更多相关文章
- PEAKS|NovoHMM|Nover|DeepNovo|MAYUPercolator|UniprotKB|Swiss-prot|Mascot|SEQUEST|X!Tandem|pFind|MaxQuant|Msconvert|PEPMASS|LC|
质谱仪: 质谱分析法是先将大分子电离为带电粒子,按质核比分离,由质谱仪识别电信号得到质谱图. Top-down直接得到结果是蛋白. Bottom down使用shutgun方法得到结果是肽段. 由蛋白 ...
- 【3】蛋白鉴定软件之Mascot
目录 1.简介 2.配置 2.1在线版本 2.2 服务器版本 3.运行 3.1 在线版本 3.2 服务器版本 4.结果 1.简介 Mascot是非常经典的蛋白鉴定软件,被Frost & Sul ...
- The Practical Guide to Empathy Maps: 10-Minute User Personas
That’s where the empathy map comes in. When created correctly, empathy maps serve as the perfect lea ...
- 微信OAuth2.0网页授权
1.OAuth2.0网页授权 关于网页授权的两种scope的区别说明 1.以snsapi_base为scope发起的网页授权,是用来获取进入页面的用户的openid的,并且是静默授权并自动跳转到回调页 ...
- .NET微信开发通过Access Token和OpenID获取用户信息
本文介绍如何获得微信公众平台关注用户的基本信息,包括昵称.头像.性别.国家.省份.城市.语言. 本文的方法将囊括订阅号和服务号以及自定义菜单各种场景,无论是否有高级接口权限,都有办法来获得用户基本信息 ...
- 微信公众平台开发(71)OAuth2.0网页授权
微信公众平台开发 OAuth2.0网页授权认证 网页授权获取用户基本信息 作者:方倍工作室 微信公众平台最近新推出微信认证,认证后可以获得高级接口权限,其中一个是OAuth2.0网页授权,很多朋友在使 ...
- Java vs. C#
Java Program Structure C# package hello; public class HelloWorld { public static void main(String ...
- VB.NET vs. C#
VB.NET Program Structure C# Imports System Namespace Hello Class HelloWorld Overloads Shar ...
- Chinese culture
文房四宝 笔墨纸砚是中国古代文人书房中必备的宝贝,被称为“文房四宝”.用笔墨书写绘画在 中国可追溯到五千年前.秦(前221---前206)时已用不同硬度的毛和竹管制笔:汉代(前206—公元220) ...
随机推荐
- Node.js—第一个动态页面
话不多说 上代码 没有加什么处理也不严谨 只为效果 const http=require('http'), path=require('path'), fs=require('fs') //创建服务 ...
- 刷题33. Search in Rotated Sorted Array
一.题目说明 这个题目是33. Search in Rotated Sorted Array,说的是在一个"扭转"的有序列表中,查找一个元素,时间复杂度O(logn). 二.我的解 ...
- day60-mysql-正则表达式
.正则表达式: 8.1 ^ 匹配 name 名称 以 "e" 开头的数据 select * from person where name REGEXP '^e'; 8.2 $ 匹配 ...
- ZJNU 1422 - 碰撞的小球
完全弹性碰撞可以视作互相穿过 所以直接考虑只有单个小球的时候,从板子上滑下所需要的时间即可 最后以30000为界分开流读入与缓冲区优化的io方法 //Case4用缓冲区io优化会WA??? /* Wr ...
- JS 特效三大系列总结
一. offset系列 1. offset系列的5个属性 1. offsetLeft : 用于获取元素到最近的定位父盒子的左侧距离 * 计算方式: 当前元素的左边框的左侧到定位父盒子的左边框右侧 * ...
- 1.linux系统调优
首先来说调优是一门黑色艺术,使用来满足人的感知,通过人的感觉来进行配置,达到让人感觉操作系统速度很块的感觉. 操作系统拥有四个瓶颈:cpu,内存,网络,磁盘.调优主要是对上述四个子系统进行配置优化,其 ...
- RxJava的简单使用
0x00 介绍 先简单介绍一下这个库,Rx的一系列实现都是为了解决同一个问题,就是让异步编程变的更加简单.它的主要思想是使用观察者模式,分离了数据源和数据的使用者,同时它拓展了观察者模式,将数据源中的 ...
- 892A. Greed#贪婪(优先队列priority_queue)
题目出处:http://codeforces.com/problemset/problem/892/A 题目大意:有一些可乐(不一定装满),问能不能把所有可乐装进两个可乐瓶中 #include< ...
- soupUI解决md5加密签名,cookie传递
问题详情: 1.接口调用需要前提状态:登录状态(cookie) 2.接口请求需要签名,签名规则为:MD5(TokenKey+apikey+timestamp+nonc) 其中 1.TokenKey.a ...
- 用bosybox制作文件系统
在orangepi_sdk/source/busybox-1.25.0目录里有源码. ). 先清除编译出来的文件及配置文件 make distclean ). 配置busybox make menuc ...