对“深入理解 Java 内存模型(六)——final”的学习
转载自https://www.infoq.cn/article/java-memory-model-6/
与前面介绍的锁和 volatile 相比较,对 final 域的读和写更像是普通的变量访问。对于 final 域,编译器和处理器要遵守两个重排序规则:
- 在构造函数内对一个 final 域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
- 初次读一个包含 final 域的对象的引用,与随后初次读这个 final 域,这两个操作之间不能重排序。
下面,我们通过一些示例性的代码来分别说明这两个规则:
public class FinalExample {
int i; // 普通变量
final int j; //final 变量
static FinalExample obj;
public void FinalExample () { // 构造函数
i = 1; // 写普通域
j = 2; // 写 final 域
}
public static void writer () { // 写线程 A 执行
obj = new FinalExample ();
}
public static void reader () { // 读线程 B 执行
FinalExample object = obj; // 读对象引用
int a = object.i; // 读普通域
int b = object.j; // 读 final 域
}
}
这里假设一个线程 A 执行 writer () 方法,随后另一个线程 B 执行 reader () 方法。下面我们通过这两个线程的交互来说明这两个规则。
写 final 域的重排序规则
写 final 域的重排序规则禁止把 final 域的写,重排序到构造函数之外。这个规则的实现包含下面 2 个方面:
- JMM 禁止编译器把 final 域的写重排序到构造函数之外。
- 编译器会在 final 域的写之后,构造函数 return 之前,插入一个 StoreStore 屏障。这个屏障禁止处理器把 final 域的写重排序到构造函数之外。
现在让我们分析 writer () 方法。writer () 方法只包含一行代码:finalExample = new FinalExample ()。这行代码包含两个步骤:
- 构造一个 FinalExample 类型的对象;
- 把这个对象的引用赋值给引用变量 obj。
假设线程 B 读对象引用与读对象的成员域之间没有重排序(马上会说明为什么需要这个假设),下图是一种可能的执行时序:
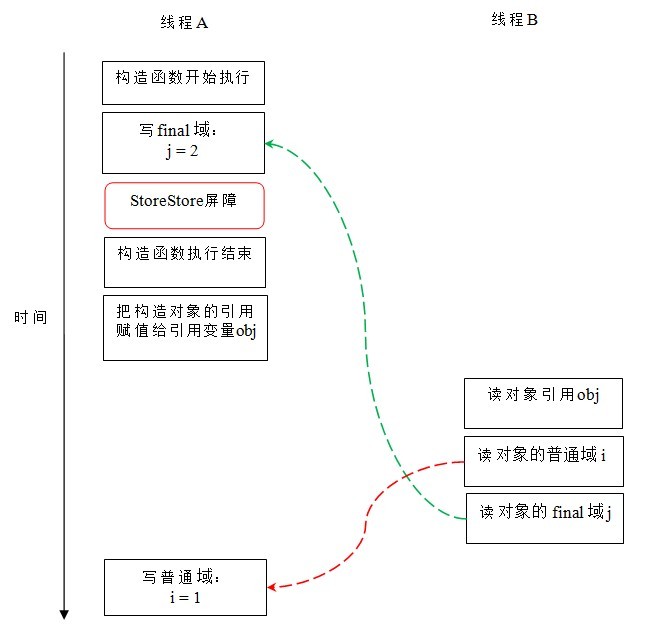
在上图中,写普通域的操作被编译器重排序到了构造函数之外,读线程 B 错误的读取了普通变量 i 初始化之前的值。而写 final 域的操作,被写 final 域的重排序规则“限定”在了构造函数之内,读线程 B 正确的读取了 final 变量初始化之后的值。
写 final 域的重排序规则可以确保:在对象引用为任意线程可见之前,对象的 final 域已经被正确初始化过了,而普通域不具有这个保障。以上图为例,在读线程 B“看到”对象引用 obj 时,很可能 obj 对象还没有构造完成(对普通域 i 的写操作被重排序到构造函数外,此时初始值 2 还没有写入普通域 i)。
读 final 域的重排序规则
读 final 域的重排序规则如下:
- 在一个线程中,初次读对象引用与初次读该对象包含的 final 域,JMM 禁止处理器重排序这两个操作(注意,这个规则仅仅针对处理器)。编译器会在读 final 域操作的前面插入一个 LoadLoad 屏障。
初次读对象引用与初次读该对象包含的 final 域,这两个操作之间存在间接依赖关系。由于编译器遵守间接依赖关系,因此编译器不会重排序这两个操作。大多数处理器也会遵守间接依赖,大多数处理器也不会重排序这两个操作。但有少数处理器允许对存在间接依赖关系的操作做重排序(比如 alpha 处理器),这个规则就是专门用来针对这种处理器。
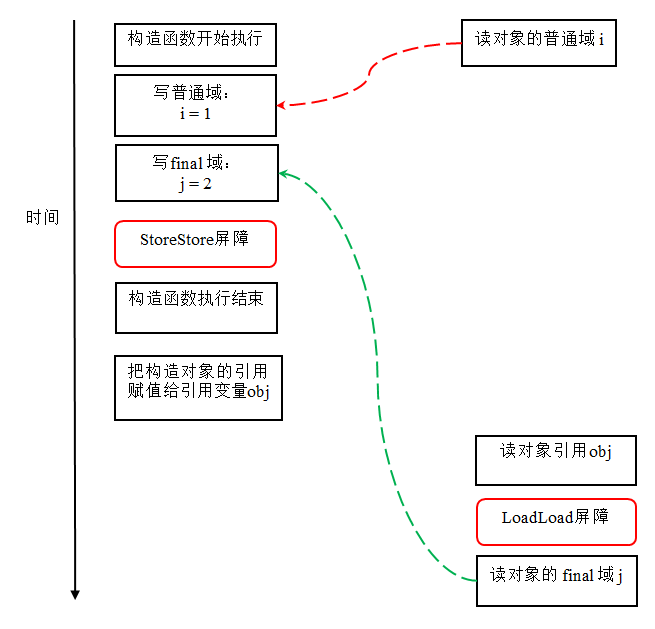
在上图中,读对象的普通域的操作被处理器重排序到读对象引用之前。读普通域时,该域还没有被写线程 A 写入,这是一个错误的读取操作。而读 final 域的重排序规则会把读对象 final 域的操作“限定”在读对象引用之后,此时该 final 域已经被 A 线程初始化过了,这是一个正确的读取操作。
如上所说,读一个对象的引用与读该对象的变量之间,存在着间接依赖关系,那么编译器是否还会重排序这两个操作?
如果 final 域是引用类型
上面我们看到的 final 域是基础数据类型,下面让我们看看如果 final 域是引用类型,将会有什么效果?
public class FinalReferenceExample {
final int[] intArray; //final 是引用类型
static FinalReferenceExample obj;
public FinalReferenceExample () { // 构造函数
intArray =
intArray[0] = 1;
}
public static void writerOne () { // 写线程 A 执行
obj =
}
public static void writerTwo () { // 写线程 B 执行
obj.intArray[0] = 2;
}
public static void reader () { // 读线程 C 执行
}
}
}
在构造函数内对一个 final 引用的对象的成员域的写入,与随后在构造函数外把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
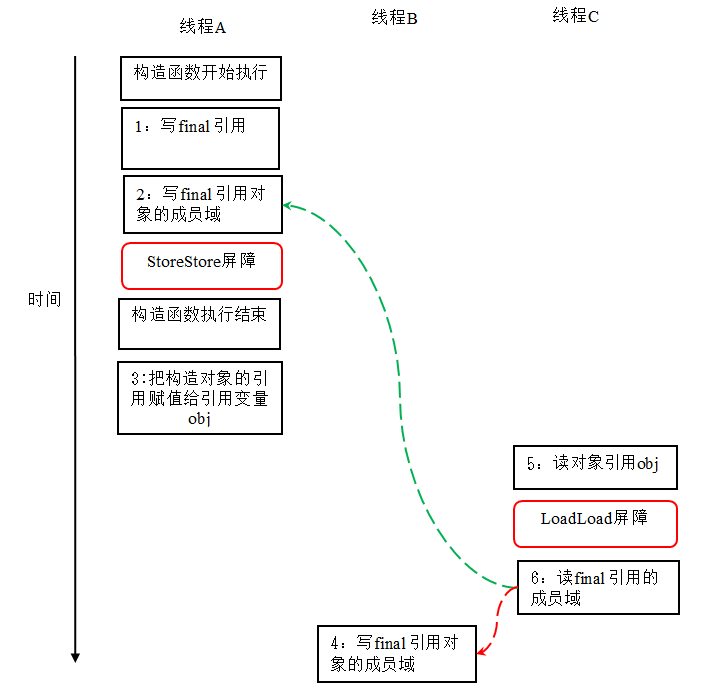
在上图中,1 是对 final 域的写入,2 是对这个 final 域引用的对象的成员域的写入,3 是把被构造的对象的引用赋值给某个引用变量。这里除了前面提到的 1 不能和 3 重排序外,2 和 3 也不能重排序
JMM 可以确保读线程 C 至少能看到写线程 A 在构造函数中对 final 引用对象的成员域的写入。即 C 至少能看到数组下标 0 的值为 1。而写线程 B 对数组元素的写入,读线程 C 可能看的到,也可能看不到。JMM 不保证线程 B 的写入对读线程 C 可见,因为写线程 B 和读线程 C 之间存在数据竞争,此时的执行结果不可预知。
如果想要确保读线程 C 看到写线程 B 对数组元素的写入,写线程 B 和读线程 C 之间需要使用同步原语(lock 或 volatile)来确保内存可见性。
为什么 final 引用不能从构造函数内“逸出”
前面我们提到过,写 final 域的重排序规则可以确保:在引用变量为任意线程可见之前,该引用变量指向的对象的 final 域已经在构造函数中被正确初始化过了。其实要得到这个效果,还需要一个保证:在构造函数内部,不能让这个被构造对象的引用为其他线程可见,也就是对象引用不能在构造函数中“逸出”。为了说明问题,让我们来看下面示例代码:
public class FinalReferenceEscapeExample {
final int i;
static FinalReferenceEscapeExample obj;
public FinalReferenceEscapeExample () {
i = 1; //1 写 final 域
obj = this; //2 this 引用在此“逸出”
}
public static void writer() {
new FinalReferenceEscapeExample ();
}
public static void reader {
}
}
}
假设一个线程 A 执行 writer() 方法,另一个线程 B 执行 reader() 方法。这里的操作 2 使得对象还未完成构造前就为线程 B 可见。即使这里的操作 2 是构造函数的最后一步,且即使在程序中操作 2 排在操作 1 后面,执行 read() 方法的线程仍然可能无法看到 final 域被初始化后的值,因为这里的操作 1 和操作 2 之间可能被重排序。实际的执行时序可能如下图所示:
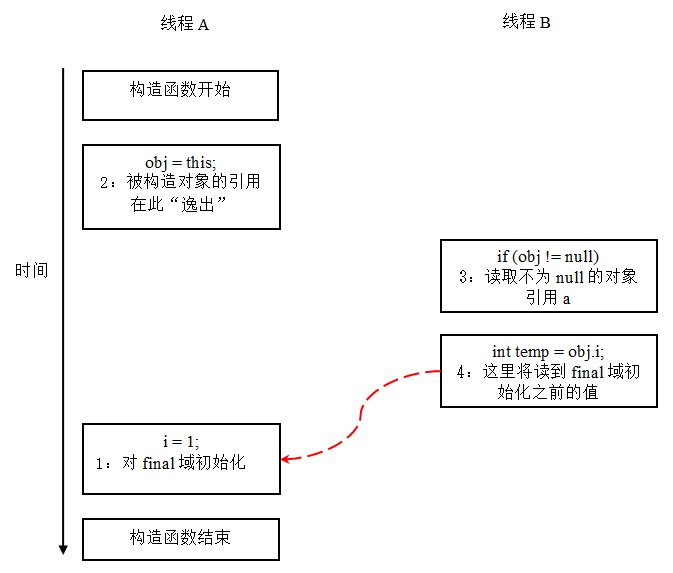
从上图我们可以看出:在构造函数返回前,被构造对象的引用不能为其他线程可见,因为此时的 final 域可能还没有被初始化。在构造函数返回后,任意线程都将保证能看到 final 域正确初始化之后的值。
个人总结:
1.写 final 域的重排序规则可以确保:在对象引用为任意线程可见之前,对象的 final 域已经被正确初始化过了,而普通域不具有这个保障。
2.在一个线程中,初次读对象引用与初次读该对象包含的 final 域,JMM 禁止处理器重排序这两个操作。
3.在构造函数内对一个 final 引用的对象的成员域的写入,与随后在构造函数外把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
final变量能够保证该变量在构造函数构造完成之前是不可访问的。但是其他非变量没有这种约束,即可能在构造函数结束之前被访问到。那么,被访问的数据是这些变量初始化之前的值,是错误的值。
因此,在多线程环境中,如果该变量可能被其他线程所访问到,要尽可能地将其声明为final变量。否则,会发生读取错误值的情况。
对“深入理解 Java 内存模型(六)——final”的学习的更多相关文章
- 深入理解java内存模型系列文章
转载关于java内存模型的系列文章,写的非常好. 深入理解java内存模型(一)--基础 深入理解java内存模型(二)--重排序 深入理解java内存模型(三)--顺序一致性 深入理解java内存模 ...
- 【深入理解Java内存模型】
深入理解Java内存模型(一)--基础 深入理解Java内存模型(二)--重排序 深入理解Java内存模型(三)--顺序一致性 深入理解Java内存模型(四)--volatile 深入理解Java内存 ...
- java内存模型(二)深入理解java内存模型的系列好文
深入理解java内存模型(一)--基础 深入理解java内存模型(二)--重排序 深入理解java内存模型(三)--顺序一致性 深入理解java内存模型(四)--volatile 深入理解java内存 ...
- 深入理解java内存模型
深入理解Java内存模型(一)——基础 深入理解Java内存模型(二)——重排序 深入理解Java内存模型(三)——顺序一致性 深入理解Java内存模型(四)——volatile 深入理解Java内存 ...
- 深入理解Java内存模型之系列篇
深入理解Java内存模型(一)——基础 并发编程模型的分类 在并发编程中,我们需要处理两个关键问题:线程之间如何通信及线程之间如何同步(这里的线程是指并发执行的活动实体).通信是指线程之间以何种机制来 ...
- 深入理解Java内存模型之系列篇[转]
原文链接:http://blog.csdn.net/ccit0519/article/details/11241403 深入理解Java内存模型(一)——基础 并发编程模型的分类 在并发编程中,我们需 ...
- 深入理解 Java 内存模型(一)- 内存模型介绍
深入理解 Java 内存模型(一)- 内存模型介绍 深入理解 Java 内存模型(二)- happens-before 规则 深入理解 Java 内存模型(三)- volatile 语义 深入理解 J ...
- 《深入理解Java内存模型》读书总结(转-总结很好)
概要 文章是<深入理解Java内容模型>读书笔记,该书总共包括了3部分的知识. 第1部分,基本概念 包括“并发.同步.主内存.本地内存.重排序.内存屏障.happens before规则. ...
- 深入理解 Java 内存模型(转载)
摘要: 原创出处 http://www.54tianzhisheng.cn/2018/02/28/Java-Memory-Model/ 「zhisheng」欢迎转载,保留摘要,谢谢! 0. 前提 &l ...
- (转)深入理解Java内存模型之系列篇
原文地址: http://blog.csdn.net/ccit0519/article/details/11241403 深入理解Java内存模型(一)——基础 并发编程模型的分类 在并发编程中,我们 ...
随机推荐
- (转)绝对路径${pageContext.request.contextPath}用法及其与web.xml中Servlet的url-pattern匹配过程
以系统的一个“添加商品”的功能为例加以说明,系统页面为add.jsp,如图一所示: 图一 添加商品界面 系统的代码目录结构及add.jsp代码如图二所示: 图二 系统的代码目录结构及add.js ...
- mysql 启动报错Host name could not be resolved解决办法
mysql 启动报错信息如下: [root@xxx ~]# 2018-01-26 17:06:35 33 [Warning] Host name 'bogon' could not be resolv ...
- ZJNU 2354 - 进贡
分开考虑k=1 k=2和k>=3的情况 2和3这两个质数比较特殊,遇到的话直接输出1就行 对于“神灵的不满意度为m的约数中,比m小且最大的那个”这句描述,指m除了自身和1这两个因子里找最大的那个 ...
- 扫描转换算法——DDA、中点画线画圆、椭圆
我的理解:在光栅图形学中,由于每一个点的表示都只能是整数值,所以光栅图形学实际只是对对实际图形的近似表示. 数值微分法(DDA):以下PPT截图来自北京化工大学李辉老师 代码实现: import ma ...
- PAT Vocabulary
数字 单词 词性 中文意 常用 音标 non-negative 非负数 non-negative number Positive 正整数 Positive integer Negative 负数 Ne ...
- PAT Basic 1020 ⽉饼 (25) [贪⼼算法]
题目 ⽉饼是中国⼈在中秋佳节时吃的⼀种传统⻝品,不同地区有许多不同⻛味的⽉饼.现给定所有种类⽉饼的库存量.总售价.以及市场的最⼤需求量,请你计算可以获得的最⼤收益是多少. 注意:销售时允许取出⼀部分库 ...
- UML-领域模型-属性
1.属性预览 2.导出属性是什么? 3.属性使用什么样的数据类型? 常见的数据类型:boolean.Date.String(Text).Integer 其他常见的:SKU.枚举类型等 而在java类中 ...
- [原]排错实战——VS清空最近打开的工程记录
原脚本how-toprocess monitorsysinternalsvsvisual studiovs2017vs2019注册表 缘起 vs有一个功能 -- 在起始页会显示最近打开的工程列表,方便 ...
- JVM(三)内存结构图
JVM内存结构图:
- iTOP-3399开发板搭建Android编译坏境
基于迅为iTOP-3399开发板2.1 装 安装 d android 源码依赖包登录进 Ubuntu 系统,输入“ctrl+alt+t”,打开超级终端,使用“su root”命令,切换到 root ...