Ubuntu中安装Hadoop
安装前
1,更新apt
sudo apt-get update
会让你输入密码(自己登录Ubuntu的时候设置的),输入密码不会显示在终端面板上,确定自己敲对之后点回车就行。
2,安装SSH服务器

sudo apt-get install openssh-server
安装过程中有个Y/N? 选Y
如果出现

解决一:
sudo rm /var/cache/apt/archives/lock
sudo rm /var/lib/dpkg/lock
sudo rm /var/lib/dpkg/lock-frontend
解决二:
ps -e | grep apt
会出现类似这样结果

这时我们只需要杀死apt-get进程就好了(找不到还是用解决一强制解锁吧-_-||)
sudo kill 【进程号(如701)】
3,登录本机
ssh localhost
出现yes or no ? yes
输入密码(你自己知道)
4,利用ssh-keygen生成密钥(主要用来设置下次登录不用输密码)
cd ~/.ssh/
ssh-keygen -t rsa
三下回车
cat ./id_rsa.pub >> authorized_keys
5,安装JAVA环境
sudo apt-get install default-jre default-jdk
1)打开环境变量配置文件
vim ~/.bashrc
按I键 在开头插入
export JAVA_HOME=/usr/lib/jvm/default-java
Esc键保存 输入 :wq 退出
如果没有安装vim 参考地址:https://blog.csdn.net/lixinghua666/article/details/82289809
vim基本使用:https://www.cnblogs.com/msq2000/p/11781332.html
sudo apt install vim
2)使变量生效
source ~/.bashrc
3)检查
echo $JAVA_HOME
出现

安装Hadoop
1)下载hadoop-2.7.1.tar.gz 下载地址:链接: https://pan.baidu.com/s/1Nkp4hQEMWblKqdBvj-lUZA 密码: yy18
参考地址:https://blog.csdn.net/se7en_q/article/details/47258007
https://www.cnblogs.com/bybdz/p/9534079.html
2)我把文件放在了共享文件夹/media/sf_gx下,解压,放到/usr/local下
sudo tar -zxf /media/sf_gx/hadoop-2.7.1_64bit.tar.gz -C /usr/local
3)改名
cd /usr/local
sudo mv ./hadoop-2.7.1 ./hadoop
4)修改权限(msq是我的用户名,根据你的实际情况修改)
sudo chown -R msq ./hadoop
5)在/usr/local/hadoop/目录下,建立tmp、hdfs/name、hdfs/data目录
cd /usr/local/hadoop
mkdir tmp
mkdir hdfs
mkdir hdfs/data
mkdir hdfs/name
6)Hadoop配置
进入/usr/local/hadoop/etc/hadoop目录,配置 hadoop-env.sh等。涉及的配置文件如下:
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
(1)配置core-site.xml
添加如下配置:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>
(2)配置hdfs-site.xml
添加如下配置
<configuration>
<!—hdfs-site.xml-->
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property> <property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property> <property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
</configuration>
(3)配置mapred-site.xml
这个文件初始时是没有的,有一个模板文件,mapred-site.xml.template
所以需要拷贝一份,并重命名为mapred-site.xml
添加如下配置:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(4)配置yarn-site.xml
添加如下配置:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>msq</value>
</property>
</configuration>
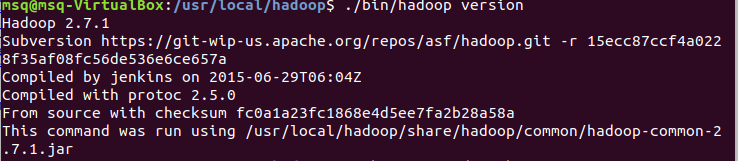
7)进入hadoop 查看版本信息
cd /usr/local/hadoop
./bin/hadoop version
8)启动hadoop
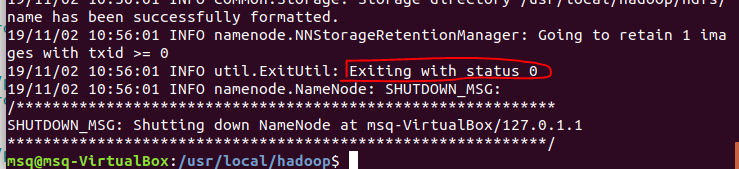
(1)格式化namenode
/usr/local/hadoop/bin/hdfs namenode -format
出现0代表成功
(2)启动NameNode 和 DataNode 守护进程(#是超级用户 $是一般用户)
$ ./sbin/start-dfs.sh
(3)启动ResourceManager 和 NodeManager 守护进程
$ ./sbin/start-yarn.sh
9)检查是否启动成功
jps
出现
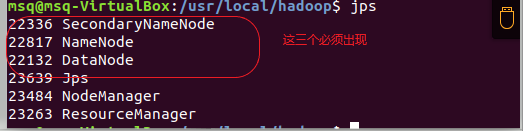
安装成功^.^
在浏览器中输入:localhost:50070/
出现
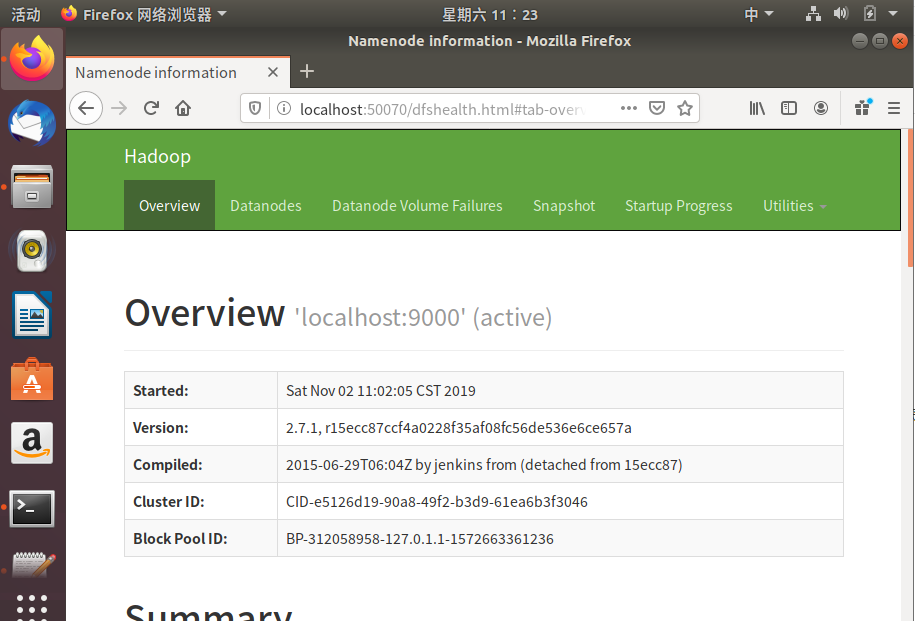
完美~~~
Ubuntu中安装Hadoop的更多相关文章
- ubuntu中安装hadoop集群
hadoop是由java 语言编写的主从结构分布式计算存储架构 准备工作: 操作系统: Ubuntu16.04 软件安装包:jdk-8u171-linux-x64.tar.gz : hadoop-2. ...
- 在ubuntu中安装maven
安装环境 操作系统:ubuntu 14.04.1 server amd64 安装jdk 在安装maven之前,必须确保已经安装过jdk. 安装jdk的方法请参考文章<在ubuntu中安装jdk& ...
- 【转】在Ubuntu中安装HBase
原博客出自于: http://blog.fens.me/category/%E6%95%B0%E6%8D%AE%E5%BA%93/ 感谢! Posted: Apr 3, 2014 Tags: Hado ...
- 在Ubuntu中安装Redis
原文地址:http://blog.fens.me/linux-redis-install/ 在Ubuntu中安装Redis R利剑NoSQL系列文章,主要介绍通过R语言连接使用nosql数据库.涉及的 ...
- ubuntu中安装Docker
系统要求: 必须时64位的系统,内核最低要求是3.10 查看系统内核: $ uname -r 3.11.0-15-generic 获取最新版本打Docker: $ wget -qO- https:// ...
- 如何在ubuntu中安装php
如何在ubuntu中安装php 情衅 | 浏览 692 次 发布于2016-05-07 12:36 最佳答案 关于Ubuntu下的LAMP配置步骤: 首先要安装LAMP 就是Apache,PH ...
- 在 ubuntu 中安装 python3.5、 tornado、 pymysql
一.在 ubuntu 中安装 python3.5 1.首先,在系统中是自带python2.7的.不要卸载,因为一些系统的东西是需要这个的.python2.7和python3.5是可以共存的. 命令如下 ...
- 解决在ubuntu中安装或升级时出现“11:资源暂时不可用”错误
解决在ubuntu中安装或升级时出现“11:资源暂时不可用”错误 解决在ubuntu中安装或升级时出现“11:资源暂时不可用”错误. 下图为具体情况: 出现问题: termial下在执行sudo ap ...
- 如何在ubuntu中安装中文输入法?
如何在ubuntu中安装中文输入法 在桌面右上角设置图标中找到“System Setting”,双击打开. 在打开的窗口里找到“Language Support”,双击打开. 可能打开会说没有安装 ...
随机推荐
- TensorFlow报错module 'tensorflow' has no attribute 'xxx'解决办法
原因:TensorFlow2.0版本修改了许多函数名字 tf.sub()更改为tf.subtract() tf.mul()更改为tf.multiply() tf.types.float32更改为tf. ...
- MySQL出现的问题
错误展示 今天还是老样子照常启动MySQL WorkBench的时候出了错误,无法连接服务器 CMD登陆也不行 发现mysql的服务都没启动,于是点击启动,却又报这个错 cmd查看MySQL的日志,想 ...
- Spring的IOC容器学习笔记
(一)Spring的IOC学习 在applicationContext.xml来配置bean,通过该接口,在主程序中,可以指定初始化的对象,不需要在进行赋值操作,直接在xml里配置好. 接下来分享的是 ...
- Matlab——m_map指南(4)——实例
1. 全球/地区温度图 (1)读取数据 clear all setup_nctoolbox %调用工具包 tic %计时 %% nc=ncgeodataset('tmpsfc.gdas.199401. ...
- Spinner的简单实用
1.Spinner的功能 Spinner在Android中主要实现的是一个下拉列表,这个下拉列表相当于弹出一个弹出一个菜单供用户选择.即Spinner提供一个快速的方法从一组中选择一个值,默认状态下S ...
- Redis对象——哈希(Hash)
哈希在很多编程语言中都有着很广泛的应用,而在Redis中也是如此,在redis中,哈希类型是指Redis键值对中的值本身又是一个键值对结构,形如value=[{field1,value1},...{f ...
- html前端之css基础
CSS 属性导航: CSS 属性组 动画 背景 边框和轮廓 框 颜色 内容页的媒体属性 尺寸 盒子模型(新) 盒子模型(旧) 字体 内容生成 网格 超链接 线框 列表 外边距 字幕 多列 内边距 页面 ...
- CentOS 6.5 nginx+tomcat+ssl配置
本文档用于指导在CentOS 6.5下使用nginx反向代理tomcat,并在nginx端支持ssl. 安装nginx.参见CentOS 6 nginx安装. SSL证书申请.参见腾讯SSL证书申请和 ...
- error: cannot bind non-const lvalue reference of type
这种问题一般是因为引用了匿名变量.涉及左值和右值的区别.一般函数的参数如果是一个表达式,那将会产生一个第3方的匿名变量传入这个函数中,此时如果引用,没用什么实际意义. c++中临时变量不能作为非con ...
- 项目组件:分页(pagination)
此分页组件可以辅助完成项目中前端页面分页展示 """ 分页组件应用: 1. 在视图函数中 queryset = models.Issues.objects.filter( ...