支持向量机SVM知识梳理和在sklearn库中的应用
SVM发展史

线性SVM=线性分类器+最大间隔
间隔(margin):边界的活动范围。The margin of a linear classifier is defined as the width that the boundary could be increased by before hitting a data point.
预备知识
- 线性分类器的分割平面(超平面):
Wx+b=0 - 点到超平面的距离:\(M=\frac{ \vert g(x) \vert }{\left\|W\right\| }\),其中\(g(x)=Wx+b\)
- SVM中正样本定义为g(x)>=1,负样本定义为g(x)<=-1
- SVM中Wx+b=1或者Wx+b=-1的点称为支持向量
间隔的形式化描述
\(M=\frac{2}{\left\|W\right\| }\)
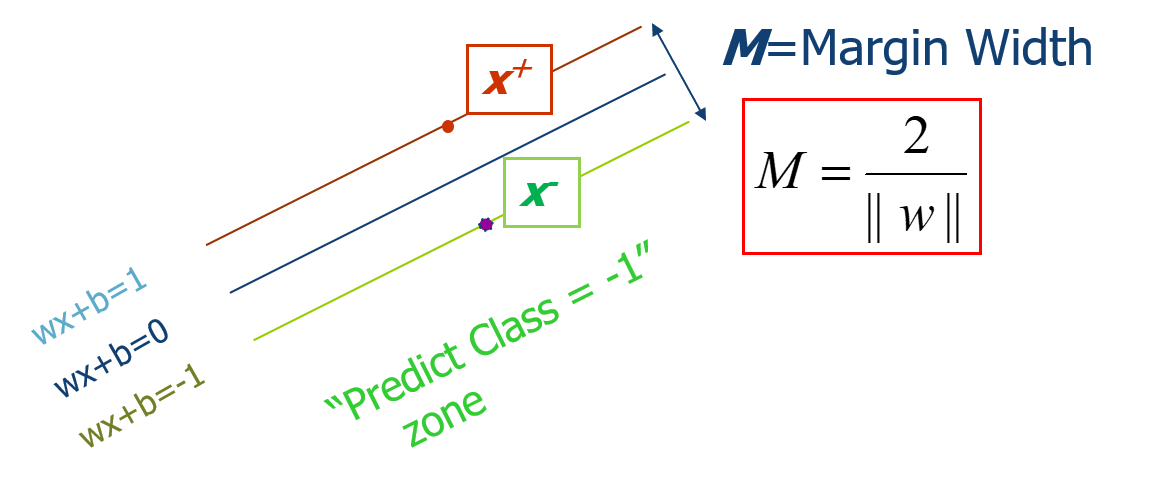
SVM通过最大化M来求解参数W和b的,目标函数如下:
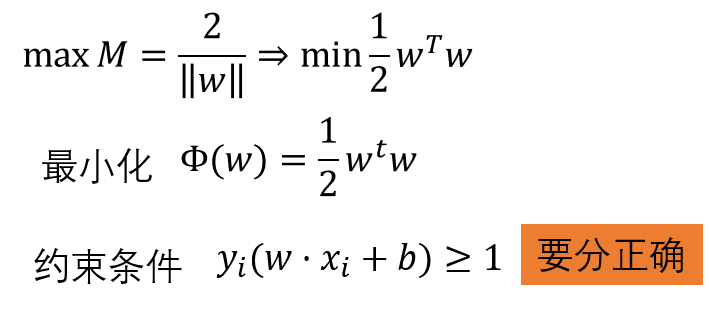
求解 :拉格朗日乘数法,偏导为0后回带
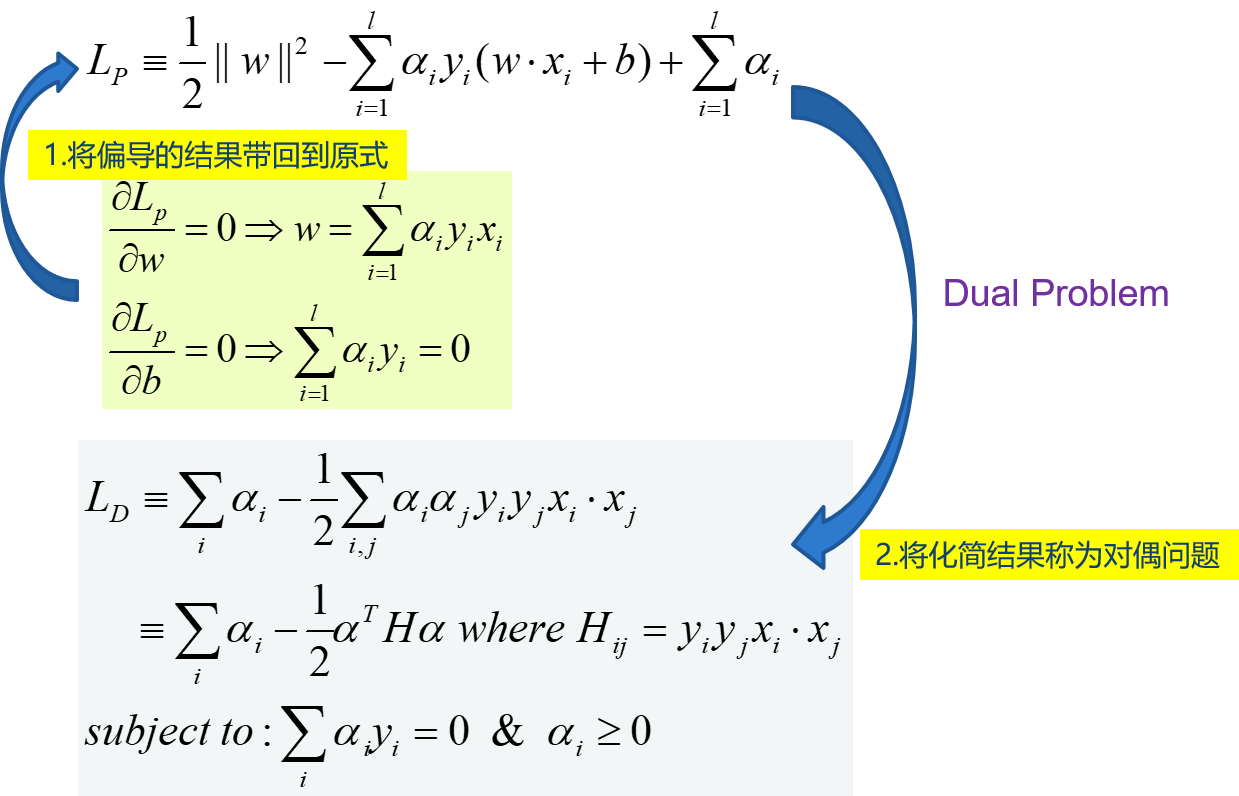
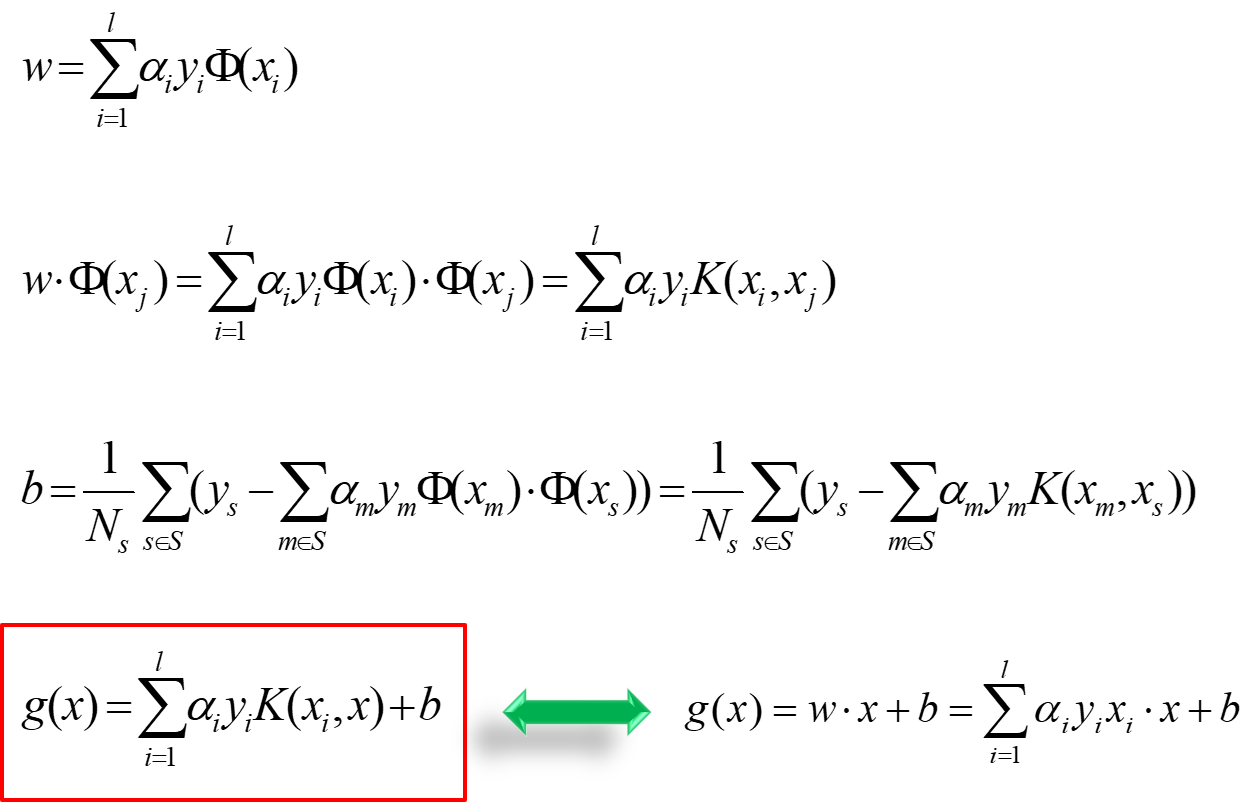
在SVM中,原问题和对偶问题具有相同的解,W已经求出:\(W=\sum_{i=1}^{l}{\alpha_iy_ix_i}\), 不等式约束,还需要满足KKT条件。若\(\alpha_i>0\),则必有xi为支持向量,即:训练完毕后,最终模型仅和支持向量有关。

b的求解过程如下

一个实例

软间隔:加入容错量
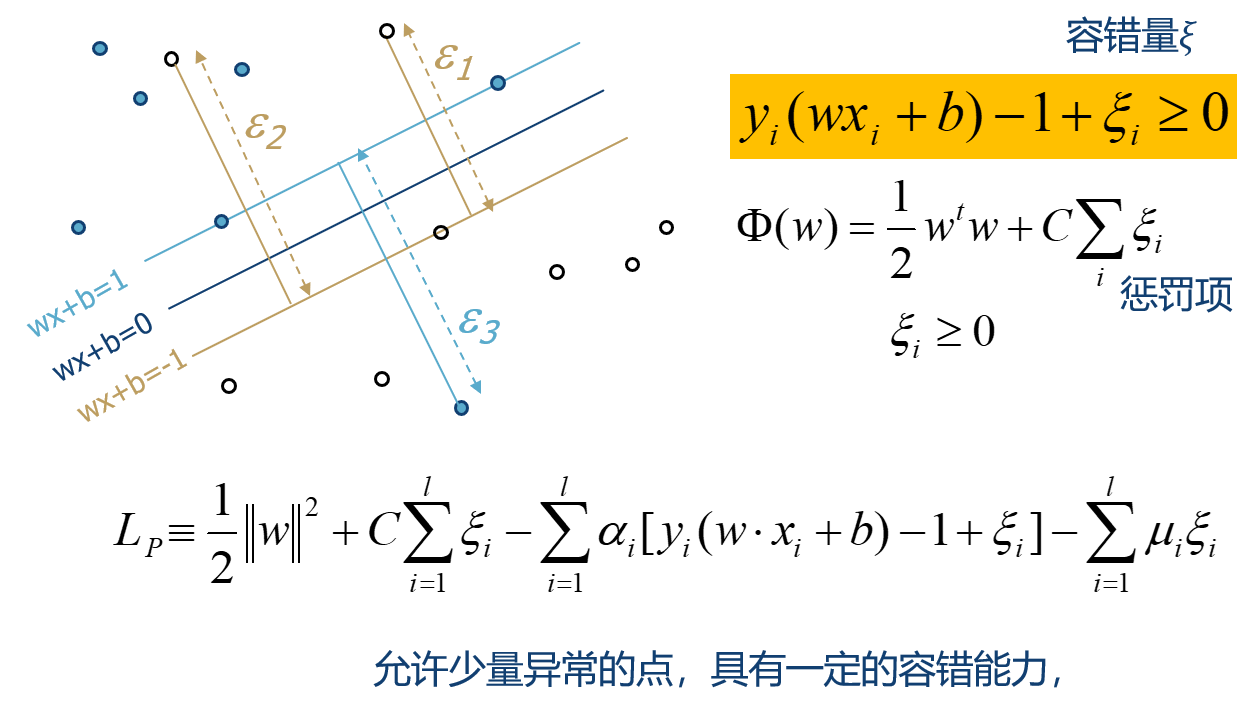
同样采用拉格朗日乘数法求解
LD的区别仅仅体现为\(\alpha_i\)的约束不同。

非线性SVM:特征空间
通过映射到高维空间来将线性不可分的问题转换为线性可分的问题。
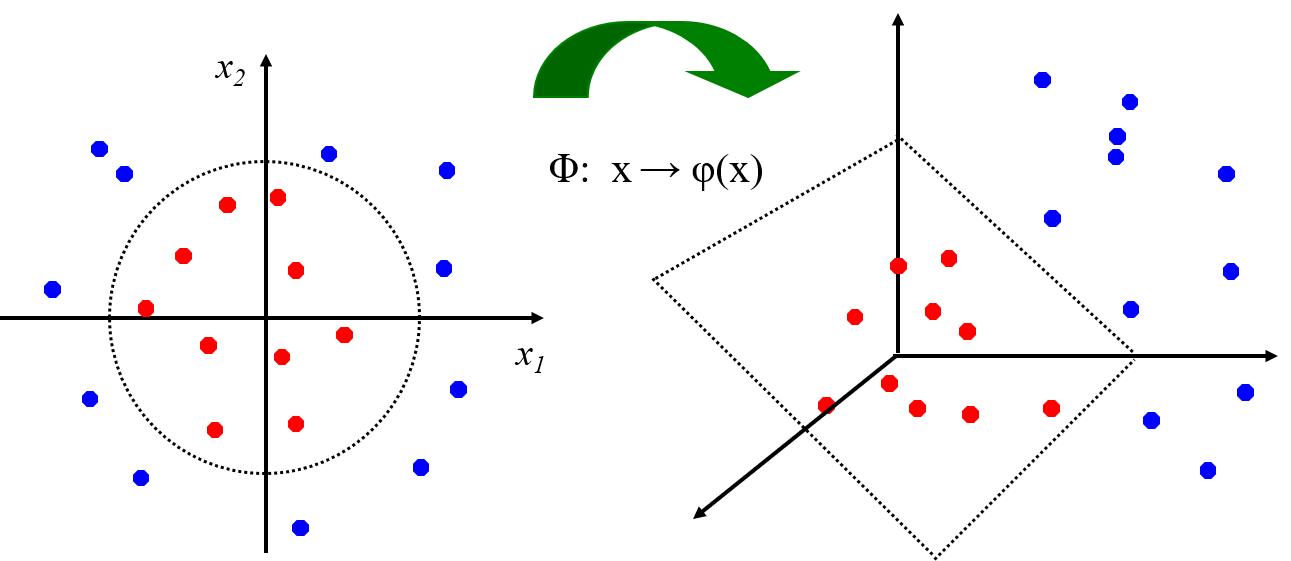
高维空间向量内积运算复杂度高。以二次型为例,直接计算
\(x_i⋅x_j⇒Φ(x_i)⋅Φ(x_j)\),直接计算的话,复杂度会成倍增加。
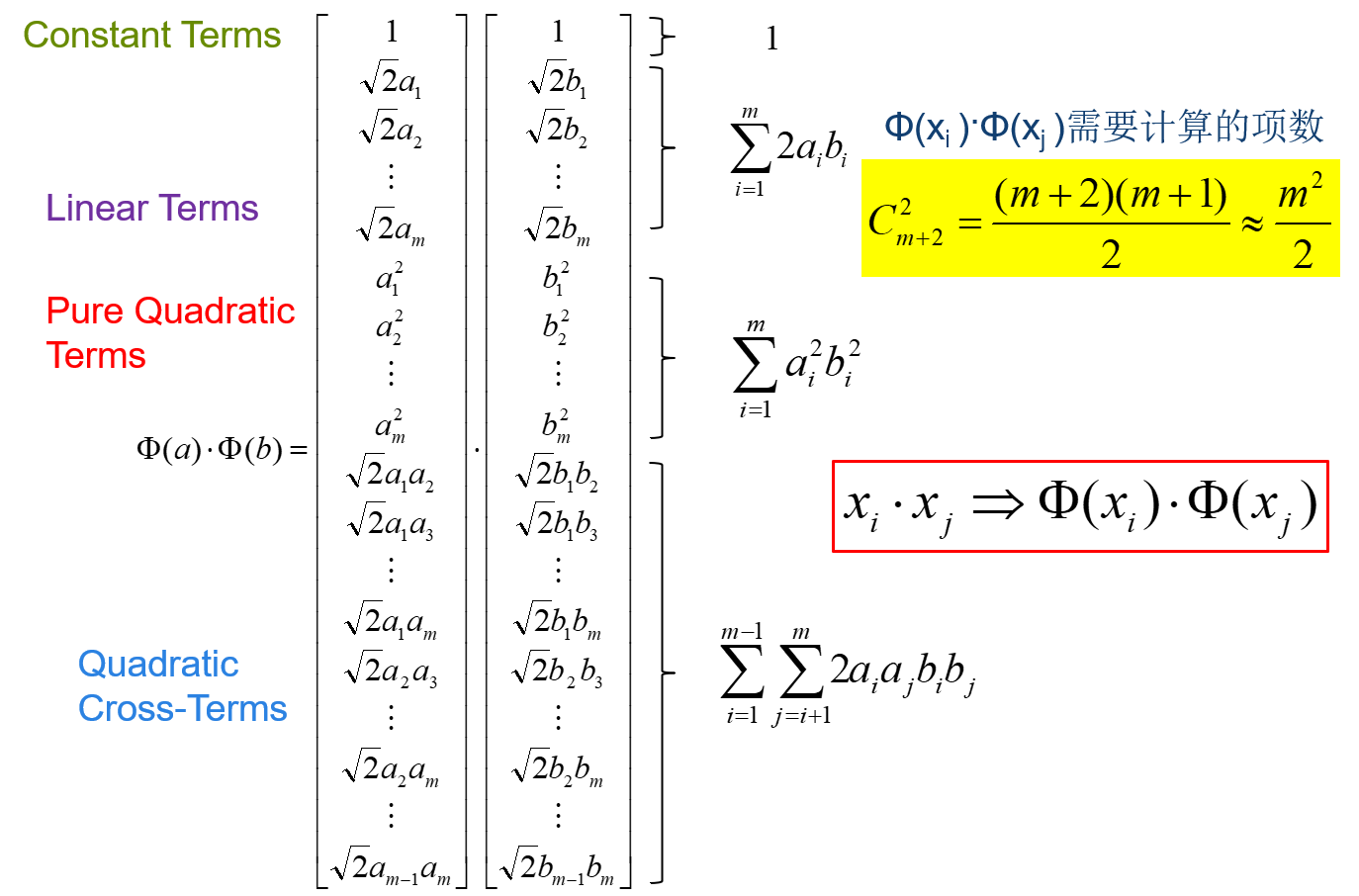
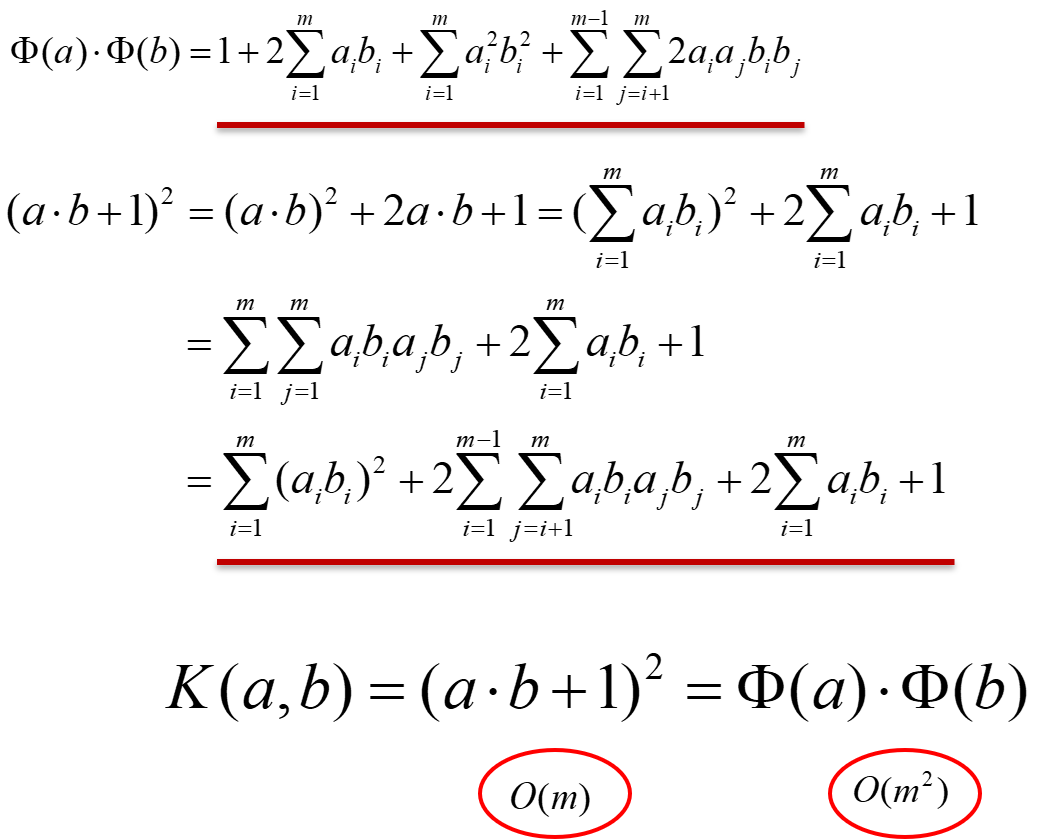
以二次型为例,理解核技巧
通过在低维空间的计算o(m),得到高维空间的结果,不需要知道变换是什么,更不需要变换结果的内积,只需要知道核函数,就可以达到相同的目标。(变换结果的内积)
请看实例,二维空间
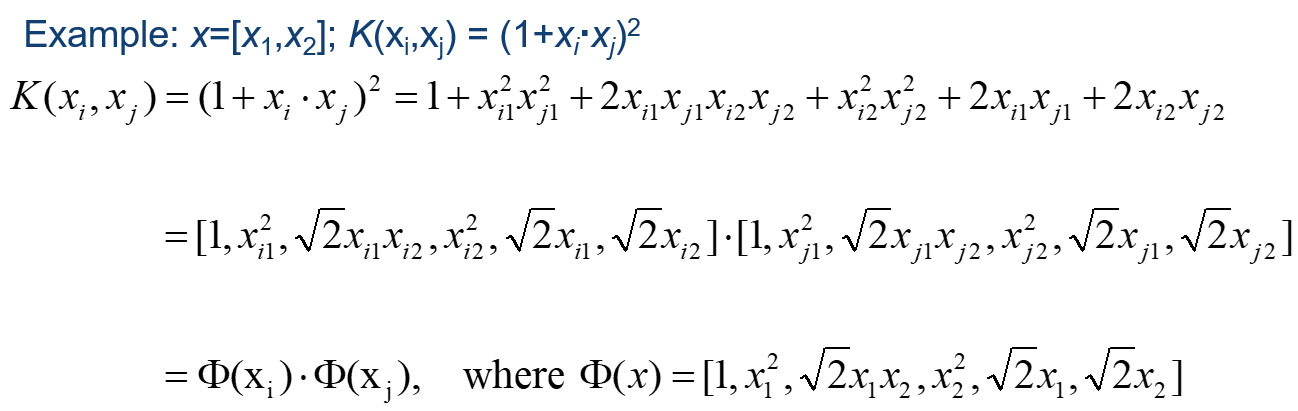
常用的核函数
多项式变换中,当d=2时,就是二次型变换。
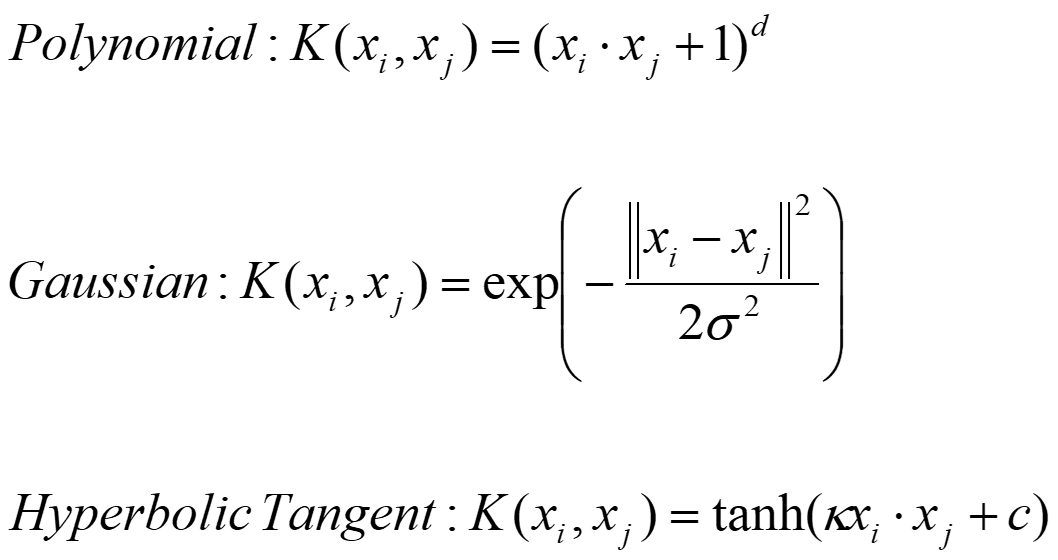
此时w和b的结果如下:
将\(x_i\)换为\(\phi(x_i)\),将\(\phi(x_i)\cdot \phi(x_j)\)换为\(K(x_i,x_j)\),其余都不变,真的很简洁。
SVM在Scikit-Learn中的应用
- Linear SVM:\(min\frac{1}{2}\left\|w\right\|^2+C\sum{\zeta^2}\)
LinearSVC(
penalty='l2',
C=1.0,#就是目标函数的C,C越大(eg:1e9),容错空间越小,越接近硬边界的SVM(最初的SVM,基本不用),C越小(eg:C=0.01),容错空间越大,越接近soft Magin.
)
- 核函数 SVM:
from sklearn.svm import SVC
SVC(
C=1.0,
kernel='rbf',
degree=3,#多项式核函数的指数d
gamma='scale',#高斯基函数中的参数gamma,越大,函数分布越狭窄; gamma越小,决策边界越松弛,当很小时,可以认为趋于无穷大成一条直线了,这时就欠拟合了。gamma取值越大,决策边界越收紧,当很小时,会无限包紧样本点,这时就过拟合了。
)
支持向量机SVM知识梳理和在sklearn库中的应用的更多相关文章
- 2.sklearn库中的标准数据集与基本功能
sklearn库中的标准数据集与基本功能 下面我们详细介绍几个有代表性的数据集: 当然同学们也可以用sklearn机器学习函数来挖掘这些数据,看看可不可以捕捉到一些有趣的想象或者是发现: 波士顿房价数 ...
- scikit_learn (sklearn)库中NearestNeighbors(最近邻)函数的各参数说明
NearestNeighbors(n_neighbors=5, radius=1.0, algorithm='auto', leaf_size=30, metric='minkowski', p=2, ...
- Sklearn库例子1:Sklearn库中AdaBoost和Decision Tree运行结果的比较
DisCrete Versus Real AdaBoost 关于Discrete 和Real AdaBoost 可以参考博客:http://www.cnblogs.com/jcchen1987/p/4 ...
- Python初探——sklearn库中数据预处理函数fit_transform()和transform()的区别
敲<Python机器学习及实践>上的code的时候,对于数据预处理中涉及到的fit_transform()函数和transform()函数之间的区别很模糊,查阅了很多资料,这里整理一下: ...
- 1.sklearn库的安装
sklearn库 sklearn是scikit-learn的简称,是一个基于Python的第三方模块.sklearn库集成了一些常用的机器学习方法,在进行机器学习任务时,并不需要实现算法,只需要简单的 ...
- day-10 sklearn库实现SVM支持向量算法
学习了SVM分类器的简单原理,并调用sklearn库,对40个线性可分点进行训练,并绘制出图形画界面. 一.问题引入 如下图所示,在x,y坐标轴上,我们绘制3个点A(1,1),B(2,0),C(2,3 ...
- [转]支持向量机SVM总结
首先,对于支持向量机(SVM)的简单总结: 1. Maximum Margin Classifier 2. Lagrange Duality 3. Support Vector 4. Kernel 5 ...
- Python中的支持向量机SVM的使用(有实例)
除了在Matlab中使用PRTools工具箱中的svm算法,Python中一样可以使用支持向量机做分类.因为Python中的sklearn也集成了SVM算法. 一.简要介绍一下sklearn Scik ...
- 以图像分割为例浅谈支持向量机(SVM)
1. 什么是支持向量机? 在机器学习中,分类问题是一种非常常见也非常重要的问题.常见的分类方法有决策树.聚类方法.贝叶斯分类等等.举一个常见的分类的例子.如下图1所示,在平面直角坐标系中,有一些点 ...
随机推荐
- ios shell打包脚本 xcodebuild
#! /bin/bash project_path=$() project_config=Release output_path=~/Desktop build_scheme=YKTicketsApp ...
- [讲解]网络流最大流dinic算法
网络流最大流算法dinic ps:本文章不适合萌新,我写这个主要是为了复习一些细节,概念介绍比较模糊,建议多刷题去理解 例题:codevs草地排水,方格取数 [抒情一下] 虽然老师说这个多半不考,但是 ...
- [noip模拟]计蒜姬<BFS>
Description 兔纸们有一个计蒜姬,奇怪的是,这个计蒜姬只有一个寄存器X.兔纸们每次可以把寄存器中的数字取出,进行如下四种运算的一种后,将结果放回寄存器中.1.X=X+X2.X=X-X3.X= ...
- 商品spu 和 sku的关系
总结一下在目前的电商系统中的商品涉及的属性spu,sku.搞清楚两者之间的关系对表的设计非常重要 spu Standard Product Unit (标准产品单位) ,一组具有共同属性的商品集 SK ...
- VirtualBox 安装 Arch Linux 并配置桌面环境
最近无聊,就找来 Arch Linux 来玩一玩,去 archlinux wiki上看了一下教程.以下是操作过程. 1. 下载镜像,下载地址; 2. 启动 Archlinux 并选择 Boot Arc ...
- js 调用铃声
<audio autoplay="autoplay" id="auto" src=""> </audio> play ...
- 万字长文带你入门Zookeeper!!!
导读 文章首发于微信公众号[码猿技术专栏],原创不易,谢谢支持. Zookeeper 相信大家都听说过,最典型的使用就是作为服务注册中心.今天陈某带大家从零基础入门 Zookeeper,看了本文,你将 ...
- 使用Azure Rest API获得Access Token介绍
背景 本文主要介绍如何获取如何获取Azure Rest API的访问token,所采用的是v2.0版本的Microsoft标识平台,关于1.0和2.0的区别可以参考 https://docs.azur ...
- NS网络仿真,小白起步版,模拟仿真之间注意的事项
FTP是基于TCP的,所以FTP应用不可以绑定UDP发送代理 FTP和CBR属于应用流,他们用来绑定TCP和UDP发送代理 TCP用于发送代理时,接收代理为TCPSink,可以绑定FTP应用.CBR流 ...
- ssm整合简单例子
1.首先新建一个maven项目 2.在pom.xml文件中加入以下代码引入包 <properties> <project.build.sourceEncoding>UTF-8& ...