Java 8 stream 实战
概述
平时工作用python的机会比较多,习惯了python函数式编程的简洁和优雅。切换到java后,对于数据处理的『冗长代码』还是有点不习惯的。有幸的是,Java8版本后,引入了Lambda表达式和流的新特性,当流和Lambda表达式结合起来一起使用时,因为流申明式处理数据集合的特点,可以让代码变得简洁易读。幸福感爆棚,有没有!
本文主要列举一些stream的使用例子,并附上相应代码。
实例
先准备测试用的数据,这里简单声明了一个Person类,有名称和年龄两个属性,采用 lombok 注解方式节省了一些模板是的代码,让代码更加简洁。
@Data
@AllArgsConstructor
@NoArgsConstructor
private static class Person {
private String name;
private Integer age;
}
private List<Person> initPersonList() {
return Lists.newArrayList(new Person("Tom", 18),
new Person("Ben", 22),
new Person("Jack", 16),
new Person("Hope", 4),
new Person("Jane", 19),
new Person("Hope", 16));
}filter
说明
- 遍历数据并检查其中的元素是否符合要求,不符合要求的过滤掉
- filter接受一个函数作为参数(Predicate),该函数用Lambda表达式表示,返回true or false,返回false的数据会被过滤
示例图
数据集合过Predicate方法,留下返回true的数据集合
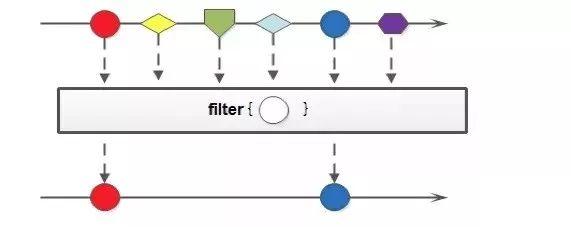
代码
@Test
public void filterTest() {
List<Person> personList = initPersonList();
// 过滤出年龄大于8的数据
List<Person> result = personList.stream().filter(x -> x.getAge() > 18).collect(Collectors.toList());
log.info(JsonUtils.toJson(result));
// filter 链式调用实现 and
result =
personList.stream().filter(x -> x.getAge() > 18).filter(x -> x.getName().startsWith("J")).collect(Collectors.toList());
log.info(JsonUtils.toJson(result));
// 通过 Predicate 实现 or
Predicate<Person> con1 = x -> x.getAge() > 18;
Predicate<Person> con2 = x -> x.getName().startsWith("J");
result =
personList.stream().filter(con1.or(con2)).collect(Collectors.toList());
log.info(JsonUtils.toJson(result));
}以上是filter的例子,可以使用链式调用实现『与』的逻辑。通过声明Predicate,并使用 or 实现『或』逻辑
map
说明
- map生成的是个一对一映射,for的作用
- map接收一个函数做为参数,此函数为Function,执行方法
R apply(T t),因此map是一对一映射
示例图
数据集合经过map方法后生成的数据集合,数据个数保持不变,即一对一映射
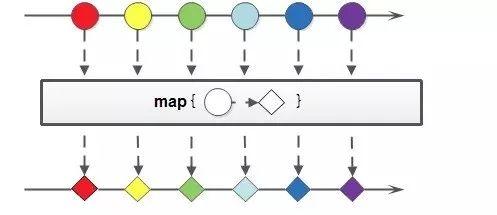
代码
@Test
public void mapTest() {
List<Person> personList = initPersonList();
List<String> result = personList.stream().map(Person::getName).collect(Collectors.toList());
log.info(JsonUtils.toJson(result));
Set<String> nameSet =
personList.stream().filter(x -> x.getAge() < 20).map(Person::getName).collect(Collectors.toSet());
log.info(JsonUtils.toJson(nameSet));
}map比较简单,这里不赘述了,直接看代码
flatmap
说明
- 和map不同的是,flatmap是个一对多的映射,然后把多个打平
- flatmap接收的函数参数也是Fuction,但是还和map的入参Function相比,可以看到返回值不同。flatmap,返回的是Stream<R>,map返回的是R,这就是上面说的一对多映射
示例图
从图中也可以看到一对多映射,例如红色圆圈经过flapmap后变成了2个(一个菱形、一个方形)
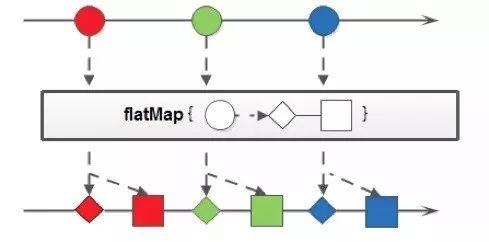
代码
@Test
public void flatMapTest() {
List<Person> personList = initPersonList();
List<String> result =
personList.stream().flatMap(x -> Arrays.stream(x.getName().split("n"))).collect(Collectors.toList());
log.info(JsonUtils.toJson(result));
}以上代码打印:["Tom","Be","Jack","Hope","Ja","e","Hope"],对每个人的姓名用字母n做了切分
reduce
说明
- 是个多对一的映射,概念和hadoop中常用的map-reduce中的reduce相同
- reduce接收两个参数,一个是identity(恒等值,比如累加计算中的初始累加值),另一个是BiFunction,调用方法
R apply(T t, U u),即把两个值reduce为一个值
示例图
下面是1+2+3+4+5的例子,可以用reduce来解决

代码
@Test
public void reduceTest() {
Integer sum = Stream.of(1, 2, 3, 4, 5).reduce(0, Integer::sum);
Assert.assertEquals(15, sum.intValue());
sum = Stream.of(1, 2, 3, 4, 5).reduce(10, Integer::sum);
Assert.assertEquals(25, sum.intValue());
String result = Stream.of("1", "2", "3")
.reduce("0", (x, y) -> (x + "," + y));
log.info(result);
}对应示例图的代码实现,有数字求和的例子和字符串拼接的例子
collect
collect在流中生成列表,map,等常用的数据结构。常用的有toList(), toSet(), toMap()
下面代码列举了几个常用的场景
@Test
public void collectTest() {
List<Person> personList = initPersonList();
// 以name为key, 建立name-person的映射,如果key重复,后者覆盖前者
Map<String, Person> result = personList.stream().collect(Collectors.toMap(Person::getName, x -> x,
(x, y) -> y));
log.info(JsonUtils.toJson(result));
// 以name为key, 建立name-person_list的映射,即一对多
Map<String, List<Person>> name2Persons = personList.stream().collect(Collectors.groupingBy(Person::getName));
log.info(JsonUtils.toJson(name2Persons));
String name = personList.stream().map(Person::getName).collect(Collectors.joining(",", "{", "}"));
Assert.assertEquals("{Tom,Ben,Jack,Hope,Jane,Hope}", name);
// partitioningBy will always return a map with two entries, one for where the predicate is true and one for where it is false. It is possible that both entries will have empty lists, but they will exist.
List<Integer> integerList = Arrays.asList(3, 4, 5, 6, 7);
Map<Boolean, List<Integer>> result1 = integerList.stream().collect(Collectors.partitioningBy(i -> i < 3));
log.info(JsonUtils.toJson(result1));
result1 = integerList.stream().collect(Collectors.groupingBy(i -> i < 3));
log.info(JsonUtils.toJson(result1));
}- 建立name-person的映射,如果key重复,后者覆盖前者。
Collectors.toMap的第三个参数就是BiFunction,和reduce中的一样,输入两个参数,返回一个参数。(x, y) -> y就是(oldValue, newValue) -> oldValue,如果不加这个方法,那么当出现map的key重复,会直接抛异常 - 将list转化为一对多的map,可以采用
Collectors.groupingBy,上述例子就是用person的name做为key,建议一对多映射关系 - 这里提到了
groupingBy和partitioningBy的区别,前者是根据某个key进行分组,后者是分类,看他们的入参就明白了,groupingBy的入参是Function,partitioningBy的入参是Predicate,即返回的是true/false。所以partitioningBy的key就是两类,true和false(即使存在空列表,true 和 false 两类还是会存在)
代码下载
- Java 8 stream 实战:代码 commit,源码下载
参考文档
- 使用 Stream API 优化代码
- Java 8 - Stream 集合操作快速上手
Java 8 stream 实战的更多相关文章
- Java JDBC学习实战(二): 管理结果集
在我的上一篇博客<Java JDBC学习实战(一): JDBC的基本操作>中,简要介绍了jdbc开发的基本流程,并详细介绍了Statement和PreparedStatement的使用:利 ...
- Java工程师 基础+实战 完整路线图(详解版)
Java工程师 基础+实战 完整路线图(详解版) Java 基础 Java 是一门纯粹的面向对象的编程语言,所以除了基础语法之外,必须得弄懂它的 oop 特性:封装.继承.多态.此外还有泛型.反射 ...
- java版gRPC实战之三:服务端流
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- java版gRPC实战之四:客户端流
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- java版gRPC实战之五:双向流
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- 【Java并发编程实战】----- AQS(四):CLH同步队列
在[Java并发编程实战]-–"J.U.C":CLH队列锁提过,AQS里面的CLH队列是CLH同步锁的一种变形.其主要从两方面进行了改造:节点的结构与节点等待机制.在结构上引入了头 ...
- 【Java并发编程实战】----- AQS(三):阻塞、唤醒:LockSupport
在上篇博客([Java并发编程实战]----- AQS(二):获取锁.释放锁)中提到,当一个线程加入到CLH队列中时,如果不是头节点是需要判断该节点是否需要挂起:在释放锁后,需要唤醒该线程的继任节点 ...
- 【Java并发编程实战】----- AQS(二):获取锁、释放锁
上篇博客稍微介绍了一下AQS,下面我们来关注下AQS的所获取和锁释放. AQS锁获取 AQS包含如下几个方法: acquire(int arg):以独占模式获取对象,忽略中断. acquireInte ...
- 【Java并发编程实战】-----“J.U.C”:CountDownlatch
上篇博文([Java并发编程实战]-----"J.U.C":CyclicBarrier)LZ介绍了CyclicBarrier.CyclicBarrier所描述的是"允许一 ...
随机推荐
- DP_1d1d诗人小G
显然:f[i]=min{f[j]+(s[i]-s[j]+i-j-1-l)^p} 此题可以基于决策单调优化 证明,反正我现在不打算学 实际上就是双向队列 不停弹出队头的元素,直到当前位置在队头元素最优的 ...
- 「题解」「CF468D」树中的配对
目录 题目大意 思路 源代码 本博客除代码之外,来自 skylee 大佬. 题目大意 一棵\(n(n\le10^5)\)个编号为\(1\sim n\)的点的带边权的树,求一个排列\(p_{1\sim ...
- Loading class `com.mysql.jdbc.Driver'. This is deprecated
注意mysql的版本,pom.xml里面的版本.External Librarlies里面的mysql版本.application.properties版本都要检查 有时候还会报 Invalid bo ...
- js 判断数组中是否包含某个元素
vuex中结合使用v-if: 链接:https://www.cnblogs.com/hao-1234-1234/p/10980102.html
- MXnet的使用
关于MXnet的介绍: MXNet: A flexible and efficient library for deep learning. 这是MXNet的官网介绍,“MXNet是灵活且高效的深度学 ...
- Go错误
1. error package main import ( "errors" "fmt" ) func main() { /* error:内置的数据类型,内 ...
- SOCV/POCV 开篇 (1)
1.功能:模拟工艺偏差对芯片性能的影响 2. 40nm之前 flat derate模型可以基本覆盖大部分情况 3.AOCV (Adance OCV) 考虑distance 和depth的影响. AOC ...
- libcurl库的简介(二)
下面是使用libcurl库实现文件上传的一个实例: void CDataProcess::sendFileToServer(void) { string netIp = strNetUrl + &qu ...
- 题解 CF492C Vanya and Exams
CF492C Vanya and Exams 有了Pascal题解,来一波C++题解呀qwq.. 简单的贪心题 按b[i]从小到大排序,一个一个学科写直到达到要求即可 #include<cstd ...
- mybatis批量插入和更新
批量插入 <insert id="add" parameterType="java.util.List"> insert all <forea ...