Hadoop安装教程_单机(含Java、ssh安装配置)
文章更新于:2020-3-24
按照惯例,需要的文件附上链接放在文首
文件名:Java SE Development Kit 8u241
文件大小:72 MB+
下载链接:https://www.oracle.com/java/technologies/javase-jdk8-downloads.html
SHA256:不同文件hash不同,请在上方网址中自行查看。
文件名:hadoop-3.2.1.tar.gz
文件大小:243MB
下载链接:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
SHA256:f66a3a4115b8f16c1077d1a198a06854dbef0e4233291712ed08d0a10629ed37
一、先安装ssh
1、查看是否安装
ps -aux|grep ssh先查看有没有ssh进程。

发现只匹配到了grep ssh进程,也就是说,现在系统里面并没有与ssh相关的进程。
2、进行ssh服务端安装
这时我们使用sudo apt install openssh-server命令来安装ssh
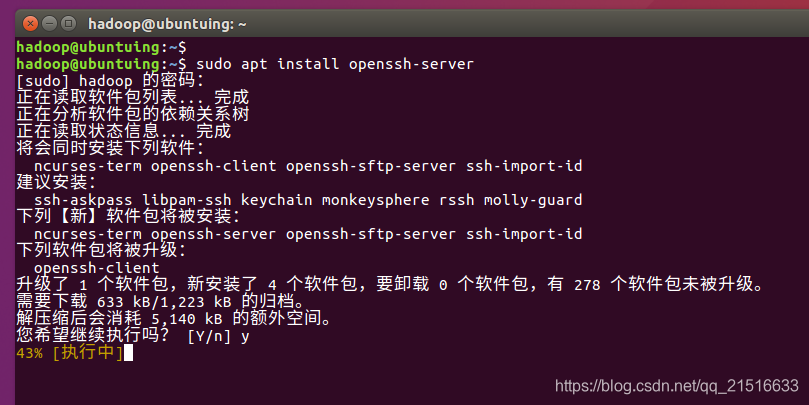
然后,等待安装完成。
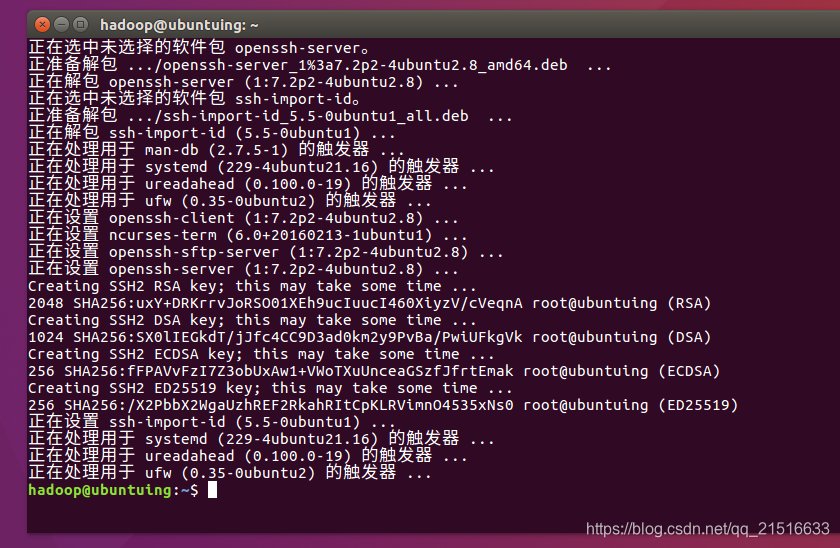
3、尝试登录
安装完成以后,我们先来测试一下能不能连到本机。

如上图,红框1是ssh首次登录提示。
红框2是提示输入ssh目标机器的密码。
密码验证通过后就登录成功了。
这样,输入密码我们就可以登录到目标机器了。
4、配置无密码登录
但是,为了更简便,我们还可以配置无密码登录,也就是将本机的公钥加到目标机器的授权文件中。
本机的公钥在~/.ssh中,上传到目标机器的.ssh/authorized_keys中
本机的私钥和公钥可以通过ssh-keygen -t rsa来生成,出现提示一路回车即可。
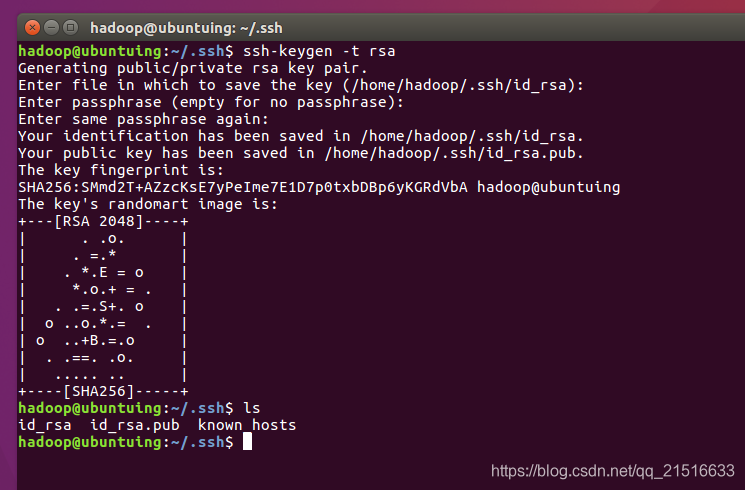
从上图可以看到,我们已经成功生成了id_rsa私钥文件和id_rsa.pub公钥文件。
因为此时我们要测试的目标机器就是本机,所以我们需要将本机的公钥文件放到本机的authorized_keys授权文件中,但从上图来看,并没有这个文件,这是因为我们还没有用过这个文件,所以还没有生成,我们手动生成一个就行。
我们使用cat id_rsa.pub >> authorized_keys命令来将本机公钥id_rsa.pub的内容追加到本机授权文件authorezed_keys中。
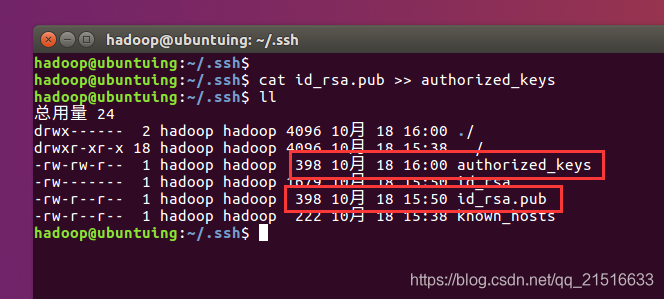
从上图可以看出,本机的授权文件和本机公钥文件是一样大小的,因为此时我们的授权文件中只有自己的公钥。而如果其他机器想要无密码登录到本机,则将其公钥追加到本机的授权文件中即可。注意,是追加,不是覆盖。如果覆盖掉了其他机器的公钥,其他机器将不能再登录到本机。
此时,我们测试一下无密码登录是否可用。
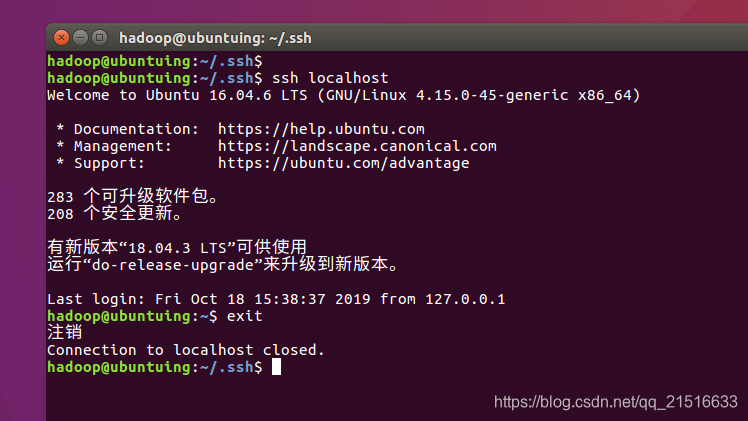
从上图可以看到,我们使用ssh命令登录,系统不再要求我们提供密码。这是因为我们机器的公钥已经在目标机器(这里还是本机)的授权文件中了。
二、安装Java环境
1、方法一:在线安装
这里我们使用sudo apt intall default-jre default-jdk命令来安装Java环境
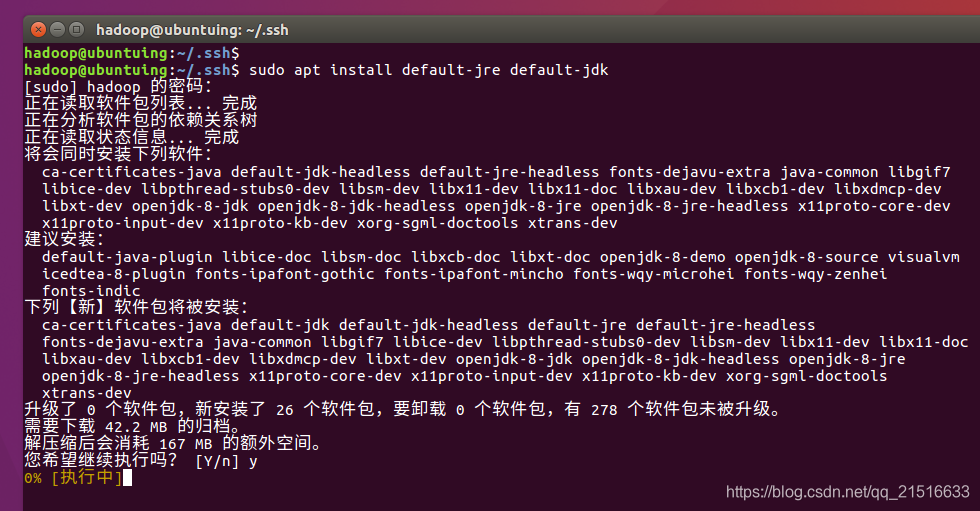
等待安装完成。
2、方法二:手动安装
官网安装手册说明如下:

1、需要先下载好安装包这里使用的是jdk-8u241-linux-x64.tar-gz
2、然后解压到你想要安装的目录。

3、配置环境变量
1、这时我们使用vi ~/.bashrc来配置JAVA_HOME、PATH等环境变量。

2、然后,在第一行加上
注:这里的jdk1.8是我的java安装路径,你需要改成你的。
export JAVA_HOME=/usr/local/jdk1.8/
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tool.jar

3、然后使用source ~./bashrc使命令立即生效

最后使用java -version查看是否安装成功
如上图,JAVA环境已经配置成功。
三、安装hadoop
1、检查文件的md5、sha512
# Check HashSum
md5sum hadoop-3.2.1.tar.gz
sha512sum hadoop-3.2.1.tar.gz
sha256sum hadoop-3.2.1.tar.gz
sha1sum hadoop-3.2.1.tar.gz

2、解压文件 == 安装程序
我们可以先在宿主机下载好hadoop文件,然后拷贝虚拟机共享文件夹。或者直接用wget在线获取文件。
这里我们使用第一种方法。
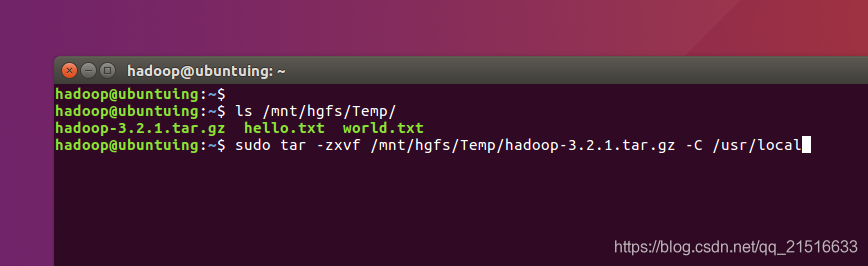
等待安装完成
3、更改文件名
进入/usr/local并将hadoop-3.2.1更名为hadoop
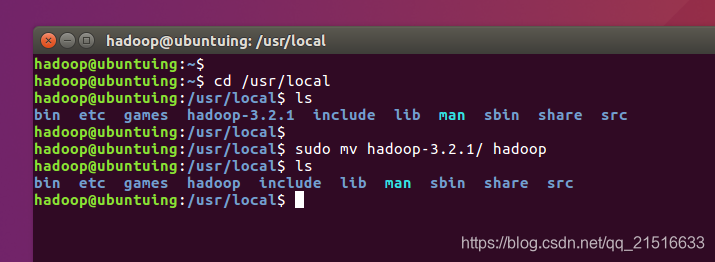
4、更改所有者
更改文件权限,并查看版本信息
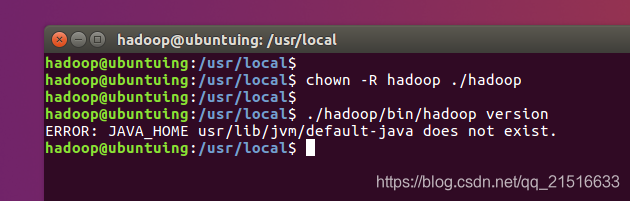
咦?发现报错了。提示JAVA_HOME的路径不存在
待续
2019年10月25日续
文章于2020-03-24再次更新时,使用hadoop3.2.1测试成功
续上
就这一个路径问题,我尝试了很多次都没有成功,怎么改都不行。
后来,我尝试了使用2.7.7版本的hadoop重新安装,成功了。
在此之前我使用的是最新的3.x版本,可能是因为新版的某些设置一些不一样吧。
在尝试过程中,我发现使用wget从官网直接获取hadoop.x.tar.gz总是失败然后我在宿主机把hadoop-2.7.7.tar.gz复制到共享文件夹。这个时候发现居然在虚拟机中看不到共享文件夹了,这时我已经安装过VMware Tools。我再次执行 sudo vmware-config-tools.pl之后重启解决。
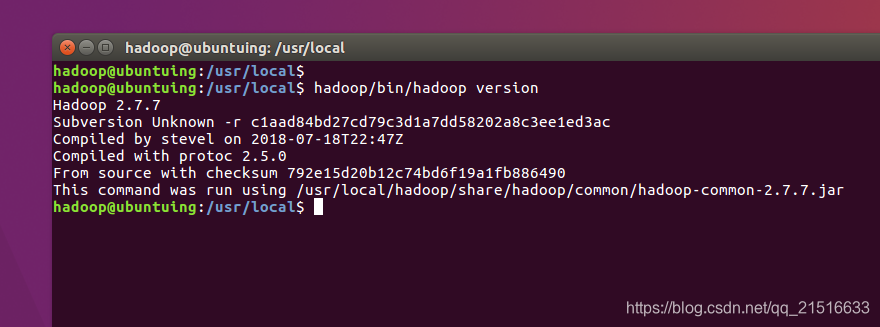
hadoop文档中附带了一些供我们测试的例子,我们可以先运行WordCount的例子来检测一下hadoop是否安装成功。
首先我们在hadoop目录下新建input文件夹cd /usr/local/hadoop;mkdir input
然后将/etc/hadoop下的*.xml文件拷贝至input文件夹中。然后执行代码 ./bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'

最后输出结果

至此,单机安装结束。
四、Enjoy!
Hadoop安装教程_单机(含Java、ssh安装配置)的更多相关文章
- Hadoop安装教程_单机/伪分布式配置_CentOS6.4/Hadoop2.6.0
Hadoop安装教程_单机/伪分布式配置_CentOS6.4/Hadoop2.6.0 环境 本教程使用 CentOS 6.4 32位 作为系统环境,请自行安装系统.如果用的是 Ubuntu 系统,请查 ...
- 转载:Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
原文 http://www.powerxing.com/install-hadoop/ 当开始着手实践 Hadoop 时,安装 Hadoop 往往会成为新手的一道门槛.尽管安装其实很简单,书上有写到, ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
摘自: http://www.cnblogs.com/kinglau/p/3796164.html http://www.powerxing.com/install-hadoop/ 当开始着手实践 H ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04(转)
http://www.powerxing.com/install-hadoop/ http://blog.csdn.net/beginner_lee/article/details/6429146 h ...
- 【转】Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
原文链接:http://dblab.xmu.edu.cn/blog/install-hadoop/ 当开始着手实践 Hadoop 时,安装 Hadoop 往往会成为新手的一道门槛.尽管安装其实很简单, ...
- Hadoop安装教程_单机/伪分布式配置
环境 本教程使用 CentOS 6.4 32位 作为系统环境,请自行安装系统(可参考使用VirtualBox安装CentOS).如果用的是 Ubuntu 系统,请查看相应的 Ubuntu安装Hadoo ...
- 新手推荐:Hadoop安装教程_单机/伪分布式配置_Hadoop-2.7.1/Ubuntu14.04
下述教程本人在最新版的-jre openjdk-7-jdk OpenJDK 默认的安装位置为: /usr/lib/jvm/java-7-openjdk-amd64 (32位系统则是 /usr/lib/ ...
- Hadoop安装教程_伪分布式
文章更新于:2020-04-09 注1:hadoop 的安装及单机配置参见:Hadoop安装教程_单机(含Java.ssh安装配置) 注2:hadoop 的完全分布式配置参见:Hadoop安装教程_分 ...
- [大数据从入门到放弃系列教程]在IDEA的Java项目里,配置并加入Scala,写出并运行scala的hello world
[大数据从入门到放弃系列教程]在IDEA的Java项目里,配置并加入Scala,写出并运行scala的hello world 原文链接:http://www.cnblogs.com/blog5277/ ...
随机推荐
- 痞子衡嵌入式:恩智浦SDK驱动代码风格检查工具预览版
大家好,我是痞子衡,是正经搞技术的痞子. 接上文 <恩智浦SDK驱动代码风格.模板.检查工具> 继续聊,是的,过去的三天里我花了一些时间做了一个基于 PyQt5 的 GUI 工具,可以帮助 ...
- vue的$message(提示框换行)
之前一直在搜怎么让提示框的文字换行,网上搜到的基本都是使用 ‘ /n ’,使用无效,也试了css换行,本来想用弹窗自己编辑html内容,还好回去官网看了一下: let arr = ['测试一', '测 ...
- 基于 HTML5 WebGL 的发动机 3D 可视化系统
前言 工业机械产品大多体积庞大.运输成本高,在参加行业展会或向海外客户销售时,如果没有实物展示,仅凭静态.简单的图片说明书介绍,无法让客户全面了解产品,不仅工作人员制作麻烦,客户看得也费力.如 ...
- (转)协议森林09 爱的传声筒 (TCP连接)
协议森林09 爱的传声筒 (TCP连接) 作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 在TCP协议与"流" ...
- Clipboard.SetText()卡住问题
调用 Clipboard.SetText(),每次都抛出异常:"CLIPBRD_E_CANT_OPEN" 调查后发现,实际上SetText有成功的将文本复制到Clipboard,但 ...
- shiro框架总结
一.概念 shiro是一个安全框架,主要可以帮助我们解决程序开发中认证和授权的问题.基于拦截器做的权限系统,权限控制的粒度有限,为了方便各种各样的常用的权限管理需求的实现,,我们有必要使用比较好的安全 ...
- Natas20 Writeup(Session登录,注入参数)
Natas20: 读取源码,发现把sessionID存到了文件中,按键值对存在,以空格分隔,如果$_SESSION["admin"]==1,则成功登陆,得到flag.并且通过查询所 ...
- Jenkins+Ant+JMeter集成
Tomcat是jenkins运行的容器,jenkins实际上是依赖于Tomcat才能启动的.Jenkins可以调度ant的脚本. Ant和maven类似,maven是执行pom文件,ant是执行bui ...
- Linux下安装MySQL的tar.gz包
以root用户登录待安装的服务器. 上传软件包并解压. 以root用户通过sftp/ftp工具上传“mysql-5.7.24-linux-glibc2.12-x86_64.tar.gz”软件包到“/o ...
- 强智教务系统验证码识别 OpenCV
强智教务系统验证码识别 OpenCV 强智教务系统验证码验证码字符位置相对固定,比较好切割 找准切割位置,将其分为四部分,匹配自建库即可,识别率近乎100%,如果觉得不错,点个star吧