1、Spark Core所处位置和主要职责
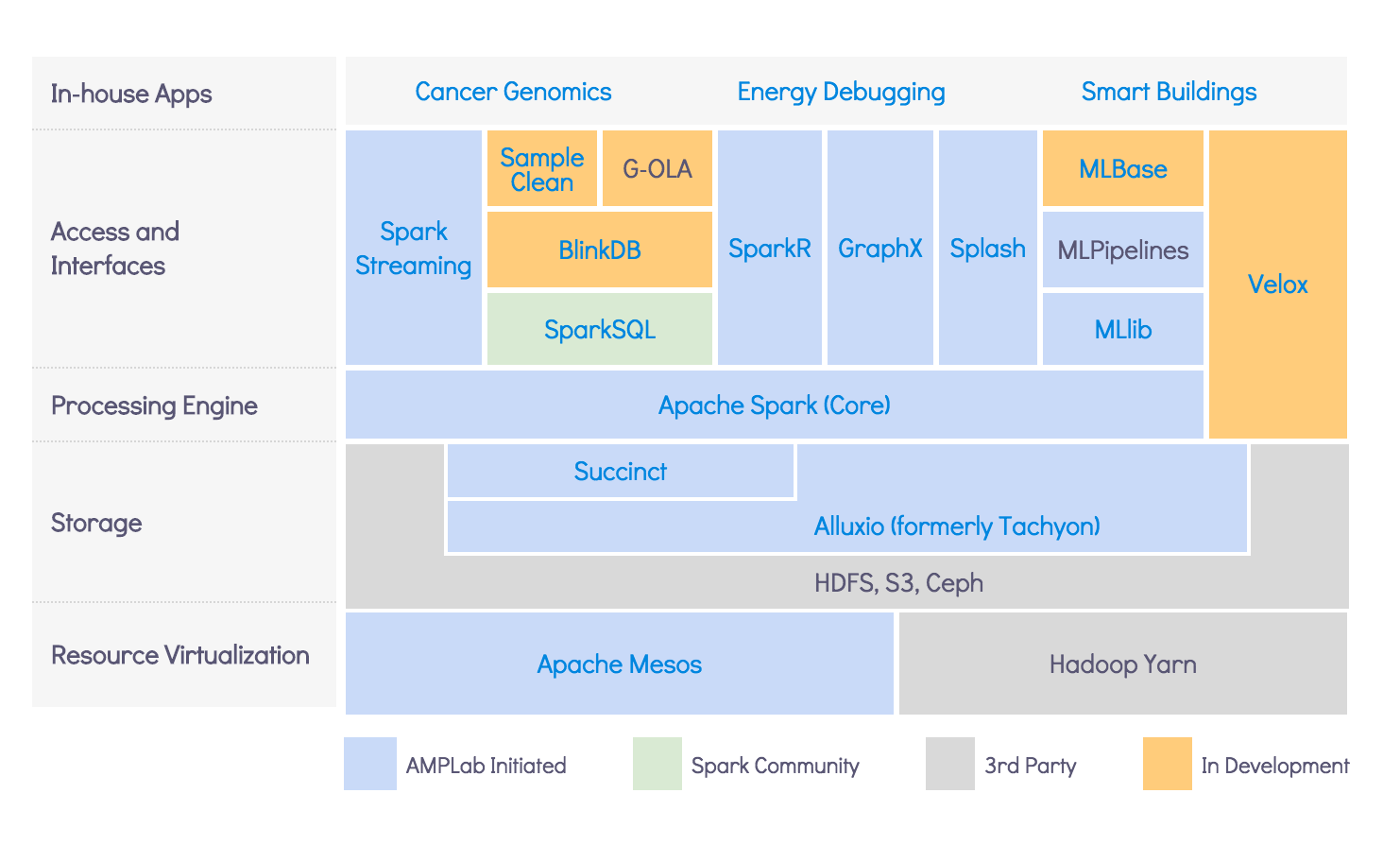
Spark组件是基于分布式资源引擎层(Yarn等)和分布式存储层(HDFS等)之上的一个组件,Spark本质上是一个计算引擎,负责计算的,根据不同计算场景划分出了SQL、Streaming、MLib、GraphX、R等模块,这些模块各自处理适合各自特点的计算场景。Spark Core作为Spark技术栈的底层,提供如Spark初始化、数据模型、远程调用、内存模型、存储体系、序列化、安全、Web UI、计算调度体系、广播变量、IO、运行模式等等的核心功能和解决各模块的公共需求,是Spark的核心层,为其他各模块提供支持服务。
1、Spark Core所处位置和主要职责的更多相关文章
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
- Spark Streaming揭秘 Day35 Spark core思考
Spark Streaming揭秘 Day35 Spark core思考 Spark上的子框架,都是后来加上去的.都是在Spark core上完成的,所有框架一切的实现最终还是由Spark core来 ...
- spark core (二)
一.Spark-Shell交互式工具 1.Spark-Shell交互式工具 Spark-Shell提供了一种学习API的简单方式, 以及一个能够交互式分析数据的强大工具. 在Scala语言环境下或Py ...
- Spark Core知识点复习-1
Day1111 Spark任务调度 Spark几个重要组件 Spark Core RDD的概念和特性 生成RDD的两种类型 RDD算子的两种类型 算子练习 分区 RDD的依赖关系 DAG:有向无环图 ...
- 上万字详解Spark Core(建议收藏)
先来一个问题,也是面试中常问的: Spark为什么会流行? 原因1:优秀的数据模型和丰富计算抽象 Spark 产生之前,已经有MapReduce这类非常成熟的计算系统存在了,并提供了高层次的API(m ...
- 需要设置jdk的三处位置:
需要设置jdk的三处位置:1.tomcat需要一个JDK : Windows--->Preferences--->MyEclipse--->Servers--->Tomcat- ...
- 【Spark Core】任务运行机制和Task源代码浅析1
引言 上一小节<TaskScheduler源代码与任务提交原理浅析2>介绍了Driver側将Stage进行划分.依据Executor闲置情况分发任务,终于通过DriverActor向exe ...
- TypeError: Error #1034: 强制转换类型失败:无法将 mx.controls::DataGrid@9a7c0a1 转换为 spark.core.IViewport。
1.错误描述 TypeError: Error #1034: 强制转换类型失败:无法将 mx.controls::DataGrid@9aa90a1 转换为 spark.core.IViewport. ...
随机推荐
- python3下BeautifulSoup练习一(爬取小说)
上次写博客还是两个月以前的事,今天闲来无事,决定把以前刚接触python爬虫时的一个想法付诸行动:就是从网站上爬取小说,这样可以省下好多流量(^_^). 因为只是闲暇之余写的,还望各位看官海涵:不足之 ...
- JavaScript 設計模型 - Iterator
Iterator Pattern是一個很重要也很簡單的Pattern:迭代器!我們可以提供一個統一入口的迭代器,Client只需要知道有哪些方法,或是有哪些Concrete Iterator,並不需要 ...
- sphinx + mysql 全文索引配置
参考地址 http://v9.help.phpcms.cn/html/2010/search_0919/35.html http://blog.sina.com.cn/s/blog_705e4fdc0 ...
- sklearn简单实现机器学习算法记录
sklearn简单实现机器学习算法记录 需要引入最重要的库:Scikit-learn 一.KNN算法 from sklearn import datasets from sklearn.model_s ...
- 疫情期,如何用A/B测试快速迭代你的产品?
作者:友盟+数据科学家 杨玉莲.陆子骏 冠状病毒来袭牵动着每个人的心,但是病毒影响的不仅仅是我们的健康,也以极快的速度极深远地影响了整个移动互联网的发展.主流阵地原本在线下的需求,如医疗和生鲜电商,快 ...
- git问题待更新
git pull failed 错误解决 情况: 刚开始的项目,需要创建一个项目,然后pull从远端的项目,创建分支dev,然后从dev分支开始拉取远端的代码 出现错误,说git pull faile ...
- 小白学 Python 数据分析(10):Pandas (九)数据运算
人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Pandas (一)概述 小白学 Python 数据分析(3):P ...
- iOS开发线程同步技术-锁
概览 1,什么是锁(临界区)? 2,常用的锁有哪些? 3,相关链接 什么是锁(临界区) 临界区:指的是一块对公共资源进行访问的代码,并非一种机制或是算法. 常用的锁有哪些? 互斥锁:是一种用于多线程编 ...
- 小白自学机器学习----3.令人头秃的pytorch安装 (No module named 'tools.nnwrap' 错误)
tensorflow 刚刚会写基础的模块了,今天找到研究方向的代码是pytorch实现的 总是看到这句话,人生苦短,我用pytorch 看来pytorch应该比tensorflow好学,但是!! py ...
- python数据分析工具 | pandas
pandas是python下强大的数据分析和探索工具,是的python在处理数据时非常快速.简单.它是构建在numpy之上的,包含丰富的数据处理函数,支持时间序列分析功能,支持灵活处理缺失数据. pa ...