Ubuntu安装Elasticsearch6.3
本文使用的 Ubuntu 版本信息:
Distributor ID: Ubuntu
Description: Ubuntu 16.04. LTS
Release: 16.04
Codename: xenial
1、新增es用户
elasticsearch 默认不允许以 root 账号运行
adduser es #新增 es 用户,期间需要设置密码
2、上传软件
使用 root 用户将 elasticsearch-6.3.0.tar.gz 和 elasticsearch-analysis-ik-6.3.0.zip(中文分析器)上传到服务器,设置权限
chown es:es elasticsearch-6.3..tar.gz
chown es:es elasticsearch-analysis-ik-6.3..zip

将 elasticsearch-6.3.0.tar.gz 和 elasticsearch-analysis-ik-6.3.0.zip 移动到 /home/es/ 目录下
mv elasticsearch-* /home/es
切换es用户
su - es #切换用户
3、解压
tar -zxvf elasticsearch-6.3..tar.gz #解压
mv elasticsearch-6.3./ elasticsearch #更改目录
4、修改配置
进入elasticsearch 目录

修改 config 目录下配置文件:jvm.options 和 elasticsearch.yml
首先是jvm.options:elasticsearch基于Lucene的,而Lucene底层是java实现,因此我们需要配置jvm参数
默认配置:
-Xms1g
-Xmx1g
修改为:
-Xms512m
-Xmx512m

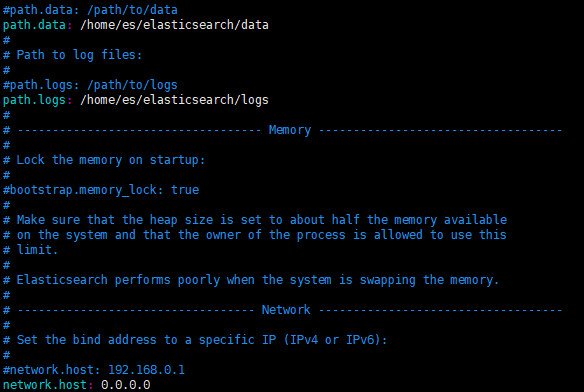
其次是 elasticsearch.yml
path.data: /home/es/elasticsearch/data # 数据目录位置
path.logs: /home/es/elasticsearch/logs # 日志目录位置
network.host: 0.0.0.0 # 绑定到0.0.0.,允许任何ip来访问
在 elasticsearch 目录下创建 data 和 logs 文件夹(logs可能已经存在)
mkdir data logs
5、运行
进入elasticsearch/bin目录,输入命令:
./elasticsearch
# 报错
ERROR: [] bootstrap checks failed
[]: max number of threads [] for user [es] is too low, increase to at least []
[]: max virtual memory areas vm.max_map_count [] is too low, increase to at least []
6、解决报错
1) max number of threads [3616] for user [es] is too low, increase to at least [4096]
最大线程个数太低,修改配置文件 /etc/security/limits.conf,增加配置
* soft nproc
* hard nproc

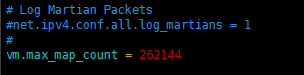
2)max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
修改/etc/sysctl.conf文件,增加配置
vm.max_map_count=
sysctl -p # 执行命令生效
如果还报错:
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
修改/etc/security/limits.conf文件,增加配置,用户退出后重新登录生效
* soft nofile
* hard nofile
重新运行elasticsearch 。
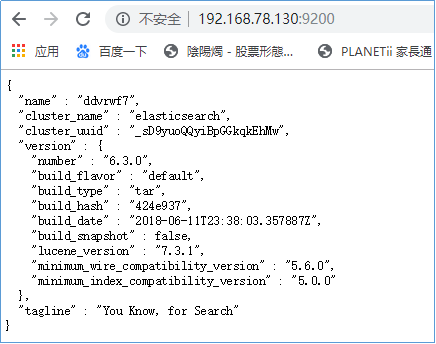
7、测试
访问192.168.61.149:9200
8、安装 ik 分词器
将 elasticsearch-analysis-ik-6.3.0.zip 移动到 elasticsearch/plugins/ 目录
mv elasticsearch-analysis-ik-6.3..zip elasticsearch/plugins/
使用unzip解压
unzip elasticsearch-analysis-ik-6.3..zip -d ik-analyzer
rm -f elasticsearch-analysis-ik-6.3..zip
然后重启elasticsearch
9、安装Kibana图形界面
直接解压:kibana-6.3.0-windows-x86_64.zip
修改配置文件:config/kibana.yml 修改安装的 elasticsearch 的 ip
elasticsearch.url: "http://192.168.78.130:9200"

进入bin目录下双击 kibana.bat 启动。

elasticsearch安装到此完成,下一篇讲 SpringBoot 集成 elasticsearch。
Ubuntu安装Elasticsearch6.3的更多相关文章
- Mac OS、Ubuntu 安装及使用 Consul
Consul 概念(摘录): Consul 是 HashiCorp 公司推出的开源工具,用于实现分布式系统的服务发现与配置.与其他分布式服务注册与发现的方案,比如 Airbnb 的 SmartStac ...
- ubuntu安装mysql
好记性不如烂笔头,记录一下,ubuntu安装mysql的指令. 安装MySQL: sudo apt-get install mysql-server sudo apt-get install mysq ...
- ubuntu安装vim时提示 没有可用的软件包 vim,但是它被其它的软件包引用了 解决办法
ubuntu安装vim时提示 没有可用的软件包 vim-gtk3,但是它被其它的软件包引用了 解决办法 本人在ubuntu系统安装vim 输入 sudo apt-get install vim 提示 ...
- docker 1.8+之后ubuntu安装指定版本docker-engine
这边记录ubuntu安装过程,首先是官网文档 If you haven’t already done so, log into your Ubuntu instance. Open a termina ...
- debian/ubuntu安装桌面环境
apt-get install xorg apt-get install gnome 然后startx ubuntu 安装Gnome桌面 1.安装全部桌面环境,其实Ubuntu系列桌面实际上有几种桌面 ...
- 一个ubuntu phper的自我修养(ubuntu安装)
ubuntu安装篇 一.ubuntu下载 到ubuntu官网下载适合自己电脑配置的系统版本,此处不做展开. 二.制作USB启动盘 在windows下制作USB启动盘,工具是universal usb ...
- ubuntu 安装JAVA jdk的两种方法:
ubuntu 安装jdk 的两种方式: 1:通过ppa(源) 方式安装. 2:通过官网下载安装包安装. 这里推荐第1种,因为可以通过 apt-get upgrade 方式方便获得jdk的升级 使用pp ...
- [其他]Ubuntu安装genymotion后unable to load VirtualBox engine
问题: Ubuntu安装genymotion后unable to load VirtualBox engine 解决办法: 如果没有安装VirtualBox,要先安装VirtualBox. 安装Vir ...
- Ubuntu安装出现左上角光标一直闪解决方式
Ubuntu安装出现左上角光标一直闪解决方式: 01下载ubunu http://cn.ubuntu.com/download/ 02.软碟通 http://pan.baidu.com/s/1qY8O ...
随机推荐
- 扯一扯基于4046系IC的锁相电路设计
4046系IC(下简称4046),包括最常见的CD4046(HEF4046),可以工作在更高频的74(V)HC4046,以及冷门而且巨难买到的74HC(T)7046和74HCT904 ...
- 【Excel使用技巧】vlookup函数
背景 前不久开发了一个运营小工具,运营人员上传一个id的列表,即可导出对应id的额外数据.需求本身不复杂,很快就开发完了,但上线后,运营反馈了一个问题,导出后的数据跟导出之前的数据顺序不一致. 经过沟 ...
- 我们是怎么实现Grpc CodeFirst
前言: Grpc默认是ProtoFirst的,即先写 proto文件,再生成代码,需要人工维护proto,生成的代码也不友好,所以出现了Grpc CodeFirst,下面来说说我们是怎么实现Grpc ...
- windows10删除用户头像
点击开始菜单,然后这里我们点击最上方的用户,弹出的界面,点击这里的更改帐户设置,大家如图进行操作,点击这里即可. 这里我们通过浏览可以修改自己的账户头像,问题是怎么删除这里使用过的账户头像呢?这里 ...
- IDEA 快捷键大全及常用插件
IDEA快捷键操作 颜色主题插件: **Material Theme UI Plugin ** 快捷键提醒: **Key Promoter X ** 查找Bug: QAPlig-FindBugs 热部 ...
- PYTHON数据类型(基础)
PYTHON数据类型(基础) 一.列表.字典.元祖.集合的基本操作 列表 创建 l1=[] l1=list() l1=list(['你好',6]) 增 l1.append('hu') l1.inser ...
- 机器学习中的 7 大损失函数实战总结(附Python演练)
介绍 想象一下-你已经在给定的数据集上训练了机器学习模型,并准备好将它交付给客户.但是,你如何确定该模型能够提供最佳结果?是否有指标或技术可以帮助你快速评估数据集上的模型? 当然是有的,简而言之,机器 ...
- 一、【Docker笔记】进入Docker世界
我们平时判断一个电脑的性能主要看什么?磁盘读写?CPU的主频高低?还是内存的大小?可是作为个人使用者来说,这些参数高一些足够我们去使用了,可是对于一个大型系统甚至是超大型系统,当前的硬件是远远达不 ...
- JS函数详解
什么是函数呢? 对于JS来说,我们可以把函数理解为任意一段代码放在一个盒子里,在我们想要让这段代码执行的时候,直接执行这个盒子里的代码就行.专业一点来讲:js函数就是由事件驱动的可执行课重复只用的代码 ...
- Spring Cache 缺陷,我好像有解决方案了
Spring Cache 缺陷 Spring Cache 是一个非常优秀的缓存组件. 但是在使用 Spring Cache 的过程当中,小黑同学也遇到了一些痛点. 比如,现在有一个需求:通过多个 us ...