静听网+python爬虫+多线程+多进程+构建IP代理池
目标网站:静听网
网站url:http://www.audio699.com/
目标文件:所有在线听的音频文件
附:我有个喜好就是听有声书,然而很多软件都是付费才能听,免费在线网站虽然能听,但是禁ip很严重,就拿静听网来说,你听一个在线音频,不能一个没听完就点击下一集,甚至不能快进太快,否则直接禁你5分钟才能再听,真的是太太讨厌了...
于是我就想用爬虫给它爬下来存储本地就nice了.
我把我的大概分析步骤分享出来.
步骤1:
我查看静听网网页url有一个规律,基网址是http://www.audio699.com/book/,每本书对于一个唯一标识,比如 《借种》 这本书的url如下:(唯一标识1276)
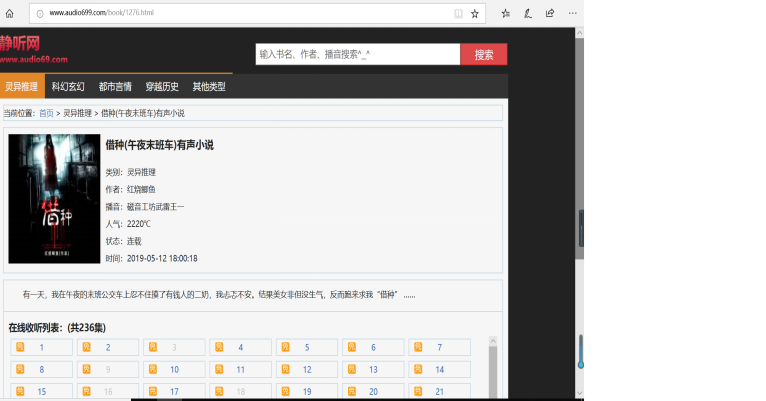
步骤2:
分析html源码:我发现这个网站的每本书的每一集的url就是再上述url后添加集数,并且网页html中包含了音频文件的src如下:
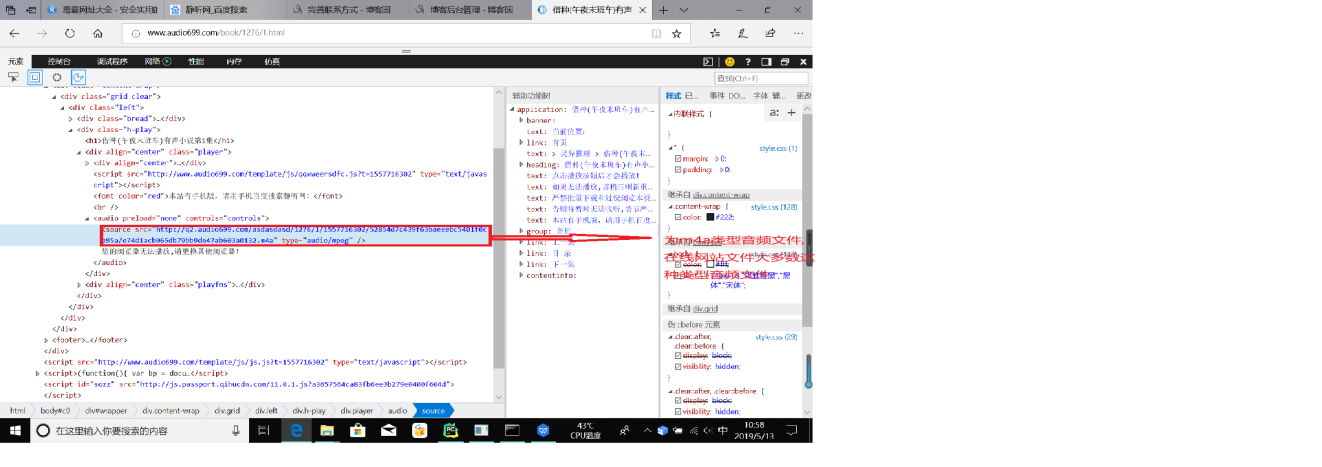
到这里我有点奇怪,这个网站封ip这么严,为什么src会直接放在静态网页中暴露如此明显,我尝试着随便复制一个src,使用python下载这个文件,嗯,瞬间就下载好了,我心想python还真不错,然而当我播放下载好的m4a文件时,发现只有5s,里面传来熟悉的声音"您访问过快,请5分钟后刷新网页重新访问",,,我心想果然没那么简单。。。
然后我重新打开网页获取刚才那个src发现src的值竟然变了,我经过测试发现这个src几乎时时刻刻都在变化,且毫无规律.
哼,想到这里我其实反倒松了口气,只要我用代码实时获取src并且开始下载应该就能解决这个问题吧,于是我测试了一下我的想法
果不其然,这样的确可以下载成功,但是这样一个一个下载速度太慢,一本有声书可是有好几百集音频文件,一集一集下不现实,于是我便用了多线程和多进程下载,
编写好python代码后,测试发现刚开始还行,但下了不到10个音频后出现错误,403 forbidden,503 service unaviable,意思是远程计算机拒绝我的计算机访问网页,文件传输服务不可用,就是这一系列的错误,就是禁了我的ip
我最开始本来想到要不要构建个ip代理池,我心想我的不同进程访问的网页url都不相同,应该没有什么大问题,哎,看来不能偷懒啊,于是我又到西刺高匿代理网站爬取了一些代理ip,我还专门写了一个筛选脚本,筛选能够成功获取目标网页html的ip,改写代码后,再次尝试,发现虽然没有再出现403等错误,但是下载成功率低的惊人,开30个线程,200个代理ip,等了半小时回来看,
tmd,才下好5,6个文件,很多文件只有十几k,看着贼烦,哎,看来这免费ip质量还是不行,存活时间太短,于是我只好到大象代理网站买了ip(一天9元好贵),然后经过
筛选再次爬取,这次一共爬200个音频,等了半个小时运行结束,发现大概下载成功了170个文件,其他文件要么直接0k,要么残缺不全,,,
为此我又写了一个脚本,专门用于下载文件夹中下载失败的文件,这次我采用多进程方式下载,写完后运行,等了一会,发现程序运行差不多了,但没运行结束,我直接结束运行,发现原来的30个残缺文件只有极少数几个还没下载成功,我筛选ip再运行脚本,这次很快就下好了,看来筛选出ip很重要,
接下来我又改进了脚本的一些地方,多线程,多进程个写了一个,配合着下载能够完全将几百集的音频文件全部下载
2019/6/4日追加:其实静听网src获取容易然而下载真的不容易,ip不够用,现在静听网ip封的更加严,也许站长发现有人大量爬取网站音频,新添了反扒手段,现在买的代理ip都不管用了,不想说了,都是伤心...
......................................三个月后..............................
2019/9/21日追加:目前已解决以上所有问题,亲测不需购买代理也能达到比较好的下载效果。博主写了一个命令行可执行文件(仅windows10可使用)
分享网盘链接:
1.19.9版本(第1版):链接:https://pan.baidu.com/s/1fZDcIgeiyR_AfMTQJbvbOQ
提取码:4qsl
2.19.11版本(第2版):链接:https://pan.baidu.com/s/175iLEzb9Vo5FhF1NNijkDg
提取码:v0y5
第2版本新增功能:(1)支持零散集数批量下载功能;
(2)支持用户指定代理IP文件路径(可以避开筛选代理的步骤,直接进入第二步【step 2】下载有声书阶段);
....................................N个月后..................................
静听网+python爬虫+多线程+多进程+构建IP代理池的更多相关文章
- python爬虫批量抓取ip代理
使用爬虫抓取数据时,经常要用到多个ip代理,防止单个ip访问太过频繁被封禁.ip代理可以从这个网站获取:http://www.xicidaili.com/nn/.因此写一个python程序来获取ip代 ...
- python 爬虫 多线程 多进程
一.程序.进程和线程的理解 程序:就相当于一个应用(app),例如电脑上打开的一个程序. 进程:程序运行资源(内存资源)分配的最小单位,一个程序可以有多个进程. 线程:cpu最小的调度单位,必须依赖 ...
- 免费IP代理池定时维护,封装通用爬虫工具类每次随机更新IP代理池跟UserAgent池,并制作简易流量爬虫
前言 我们之前的爬虫都是模拟成浏览器后直接爬取,并没有动态设置IP代理以及UserAgent标识,本文记录免费IP代理池定时维护,封装通用爬虫工具类每次随机更新IP代理池跟UserAgent池,并制作 ...
- python爬虫(3)——用户和IP代理池、抓包分析、异步请求数据、腾讯视频评论爬虫
用户代理池 用户代理池就是将不同的用户代理组建成为一个池子,随后随机调用. 作用:每次访问代表使用的浏览器不一样 import urllib.request import re import rand ...
- python爬虫实战(三)--------搜狗微信文章(IP代理池和用户代理池设定----scrapy)
在学习scrapy爬虫框架中,肯定会涉及到IP代理池和User-Agent池的设定,规避网站的反爬. 这两天在看一个关于搜狗微信文章爬取的视频,里面有讲到ip代理池和用户代理池,在此结合自身的所了解的 ...
- python爬虫18 | 就算你被封了也能继续爬,使用IP代理池伪装你的IP地址,让IP飘一会
我们上次说了伪装头部 ↓ python爬虫17 | 听说你又被封 ip 了,你要学会伪装好自己,这次说说伪装你的头部 让自己的 python 爬虫假装是浏览器 小帅b主要是想让你知道 在爬取网站的时候 ...
- Python爬虫之ip代理池
可能在学习爬虫的时候,遇到很多的反爬的手段,封ip 就是其中之一. 对于封IP的网站.需要很多的代理IP,去买代理IP,对于初学者觉得没有必要,每个卖代理IP的网站有的提供了免费IP,可是又很少,写了 ...
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
- python之squid实现免费 IP代理 (windows win7 单机 本机 本地 正向代理 区分 HTTPS)
0.目录 1.思路2.windows安装3.相关命令行4.简单配置和初步使用5.问题:squid是否支持HTTPS6.问题:配置多个代理条目,相同ip不同port报错7.问题:根据代理请求区分HTTP ...
随机推荐
- 实践 Network Policy 【转】
为了演示 Network Policy,我们先部署一个 httpd 应用,其配置文件 httpd.yaml 为: httpd 有三个副本,通过 NodePort 类型的 Service 对外提供服务. ...
- STM32+Nokia5110LCD
Nokia5110LCD(84*48) lcd.h #ifndef _LCD_H#define _LCD_H #include "sys.h" #include "std ...
- SpringBoot-集成通用mapper
SpringBoot-集成通用mapper SpringBoot-集成通用mapper 我们在SpringBoot中整合了MyBatis,但是大量重复的增删改查还是很头疼的问题,MyBatis也给 ...
- url中?的作用
http://123.206.87.240:8002/get/?what=flag? 分隔实际的URL和参数 ,用于动态页面的交互和传参
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 字体图标(Glyphicons):glyphicon glyphicon-forward
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name ...
- NFS挂载共享文件夹
修改rcS启动脚本,使开发板初始化完成,自动挂载共享文件夹 修改开发板ip,使之与虚拟机处于同一网段(二者可以互ping) 挂载虚拟机的共享文件夹 rcS 1 ifconfig eth ...
- c/c++ 计算屏幕的PPI
PPI(pixels per inch)是图像分辨率的单位,表示的是每英寸所拥有的像素(pixel)数目.那如何计算勒?其实PPI计算有这相应的公式,公式为:sqrt(横向的平方+纵向的平方)/屏幕尺 ...
- [LeetCode] 933. Number of Recent Calls 最近的调用次数
Write a class RecentCounter to count recent requests. It has only one method: ping(int t), where t r ...
- Vulkan 之 Synchronization
1.2之前定的版本采用 vkSemaphore和vkFence来进行同步, VkSemaphore allowed applications to synchronize operations acr ...
- 调试ASP.NET程序
用VS打开你的项目 从VS中找到"调试"-----"附件到进程",然后选中w3wp.exe,点击附件到进程,然后再发送数据进行调试就可以了