LeetCode——1305. 两棵二叉搜索树中的所有元素
给你 root1 和 root2 这两棵二叉搜索树。
请你返回一个列表,其中包含 两棵树 中的所有整数并按 升序 排序。.
示例 1:
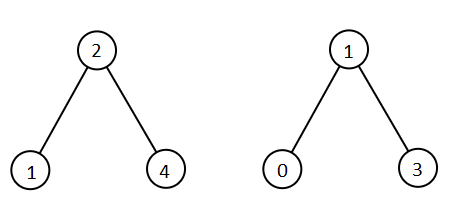
输入:root1 = [2,1,4], root2 = [1,0,3]
输出:[0,1,1,2,3,4]
示例 2:
输入:root1 = [0,-10,10], root2 = [5,1,7,0,2]
输出:[-10,0,0,1,2,5,7,10]
示例 3:
输入:root1 = [], root2 = [5,1,7,0,2]
输出:[0,1,2,5,7]
示例 4:
输入:root1 = [0,-10,10], root2 = []
输出:[-10,0,10]
示例 5:
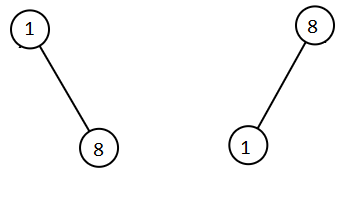
输入:root1 = [1,null,8], root2 = [8,1]
输出:[1,1,8,8]
提示:
每棵树最多有 5000 个节点。
每个节点的值在 [-10^5, 10^5] 之间。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/all-elements-in-two-binary-search-trees
方法一:遍历 + 排序
我们可以想到的最简单的方法是,对两棵树进行任意形式的遍历(深度优先搜索、广度优先搜索、前序遍历、中序遍历、后序遍历),并将遍历到的所有元素放入一个数组中,最后对这个数组进行排序即可。
C++
class Solution {
public:
void dfs(TreeNode* node, vector<int>& ans) {
if (!node) {
return;
}
ans.push_back(node->val);
dfs(node->left, ans);
dfs(node->right, ans);
}
vector<int> getAllElements(TreeNode* root1, TreeNode* root2) {
vector<int> ans;
dfs(root1, ans);
dfs(root2, ans);
sort(ans.begin(), ans.end());
return ans;
}
};
Python
class Solution:
def getAllElements(self, root1: TreeNode, root2: TreeNode) -> List[int]:
ans = list()
def dfs(node):
if not node:
return
ans.append(node.val)
dfs(node.left)
dfs(node.right)
dfs(root1)
dfs(root2)
ans.sort()
return ans
复杂度分析
时间复杂度:O((M+N)log(M+N)),其中 M 和 N 是两棵树中的节点个数。
空间复杂度:O(H_M + H_N + log(M + N)),其中 H_M 和 H_N是两棵树的高度,这里只计算除了存储答案的数组以外需要的额外空间。上面给出的代码使用深度优先搜索对两棵树进行遍历,需要 O(H_M + H_N)的栈空间;在对数组进行排序时,需要log(M+N) 的栈空间。
方法二:中序遍历 + 归并排序
方法一中并没有用到二叉搜索树本身的性质。如果我们对二叉搜索树进行中序遍历,就可以直接得到树中所有元素升序排序后的结果。因此我们可以对两棵树分别进行中序遍历,得到数组 v1 和 v2,它们分别存放了两棵树中的所有元素,且均已有序。在这之后,我们通过归并排序的方法对 v1 和 v2 进行排序,就可以得到最终的结果。
C++
class Solution {
public:
void dfs(TreeNode* node, vector<int>& v) {
if (!node) {
return;
}
dfs(node->left, v);
v.push_back(node->val);
dfs(node->right, v);
}
vector<int> getAllElements(TreeNode* root1, TreeNode* root2) {
vector<int> v1, v2;
dfs(root1, v1);
dfs(root2, v2);
vector<int> ans;
int i = 0, j = 0;
while (i < v1.size() || j < v2.size()) {
if (i < v1.size() && (j == v2.size() || v1[i] <= v2[j])) {
ans.push_back(v1[i++]);
}
else {
ans.push_back(v2[j++]);
}
}
return ans;
}
};
Python
class Solution:
def getAllElements(self, root1: TreeNode, root2: TreeNode) -> List[int]:
def dfs(node, v):
if not node:
return
dfs(node.left, v)
v.append(node.val)
dfs(node.right, v)
v1, v2 = list(), list()
dfs(root1, v1)
dfs(root2, v2)
ans, i, j = list(), 0, 0
while i < len(v1) or j < len(v2):
if i < len(v1) and (j == len(v2) or v1[i] <= v2[j]):
ans.append(v1[i])
i += 1
else:
ans.append(v2[j])
j += 1
return ans
复杂度分析
时间复杂度:O(M+N),其中 M 和 N 是两棵树中的节点个数。中序遍历的时间复杂度为 O(M+N),归并排序的时间复杂度同样为 O(M+N)。
空间复杂度:O(M+N)。我们需要使用额外的空间存储数组 v1 和 v2。
方法一 前序遍历+排序
先将两棵树的所有节点都放到一个list中,这里可以采用各种类型的遍历(前序、中序、后序、层次);
然后将list进行排序即可。
Java
public class Problem02 {
private List<Integer> ansList;
private void dfs(TreeNode root) {
if (root == null) {
return;
}
ansList.add(root.val);
dfs(root.left);
dfs(root.right);
}
public List<Integer> getAllElements(TreeNode root1, TreeNode root2) {
ansList = new ArrayList<>();
dfs(root1);
dfs(root2);
Collections.sort(ansList);
return ansList;
}
}
复杂度分析
时间复杂度:O(nlogn)。因为用到了排序。
空间复杂度:O(n)。开辟了一个m+n(跟n同量级)大小的list,m代表tree1的节点数、n代表tree2的节点数。
方法二 分别中序遍历+归并
前提:这两棵树都是二叉搜索树(BST),而一颗BST中序遍历的结果就是排好序的。
新建两个list,分别对两棵树进行中序遍历得到分别排好序的list1,list2;
已知list1和list2有序,那么将二者归并即可的到一个排好序的总list。(这里时间复杂度也就O(n))。
public class Problem02_1 {
private void dfs(TreeNode root, List<Integer> ansList) {
if (root == null) {
return;
}
dfs(root.left, ansList);
ansList.add(root.val);
dfs(root.right, ansList);
}
private List<Integer> merge(List<Integer> list1, List<Integer> list2) {
List<Integer> ansList = new ArrayList<>();
int size1 = list1.size();
int size2 = list2.size();
int index1, index2;
for (index1 = 0, index2 = 0; index1 < size1 && index2 < size2;) {
int num1 = list1.get(index1);
int num2 = list2.get(index2);
if (num1 < num2) {
ansList.add(num1);
index1++;
} else {
ansList.add(num2);
index2++;
}
}
while (index1 < size1) {
ansList.add(list1.get(index1++));
}
while (index2 < size2) {
ansList.add(list2.get(index2++));
}
return ansList;
}
public List<Integer> getAllElements(TreeNode root1, TreeNode root2) {
List<Integer> ansList1 = new ArrayList<>();
List<Integer> ansList2 = new ArrayList<>();
dfs(root1, ansList1);
dfs(root2, ansList2);
return merge(ansList1, ansList2);
}
}
复杂度分析
时间复杂度:O(n). 两次的中序遍历和一次的归并操作都是O(n)的时间复杂度。
空间复杂度:O(n).
方法三 遍历+优先队列
在树遍历的时候用一个优先队列(默认小根堆)来添加元素;
然后,将优先队列的元素逐个取出到list中即可。
Java
public class Problem02_2 {
private PriorityQueue<Integer> priorityQueue;
private void dfs(TreeNode root) {
if (root == null) {
return;
}
priorityQueue.offer(root.val);
dfs(root.left);
dfs(root.right);
}
public List<Integer> getAllElements(TreeNode root1, TreeNode root2) {
priorityQueue = new PriorityQueue<>();
dfs(root1);
dfs(root2);
List<Integer> ansList = new ArrayList<>();
while (!priorityQueue.isEmpty()) {
ansList.add(priorityQueue.poll());
}
return ansList;
}
}
复杂度分析
时间复杂度:O(nlogn)。因为优先队列插入和删除的操作的时间复杂度都是O(logn),然后有n节点,就是O(nlogn).
空间复杂度:O(n)
LeetCode——1305. 两棵二叉搜索树中的所有元素的更多相关文章
- Leetcode:1305. 两棵二叉搜索树中的所有元素
Leetcode:1305. 两棵二叉搜索树中的所有元素 Leetcode:1305. 两棵二叉搜索树中的所有元素 思路 BST树中序历遍有序. 利用双指针法可以在\(O(n)\)的复杂度内完成排序. ...
- [LeetCode] Delete Node in a BST 删除二叉搜索树中的节点
Given a root node reference of a BST and a key, delete the node with the given key in the BST. Retur ...
- [LeetCode] 450. Delete Node in a BST 删除二叉搜索树中的节点
Given a root node reference of a BST and a key, delete the node with the given key in the BST. Retur ...
- [LeetCode]230. 二叉搜索树中第K小的元素(BST)(中序遍历)、530. 二叉搜索树的最小绝对差(BST)(中序遍历)
题目230. 二叉搜索树中第K小的元素 给定一个二叉搜索树,编写一个函数 kthSmallest 来查找其中第 k 个最小的元素. 题解 中序遍历BST,得到有序序列,返回有序序列的k-1号元素. 代 ...
- [LeetCode] Insert into a Binary Search Tree 二叉搜索树中插入结点
Given the root node of a binary search tree (BST) and a value to be inserted into the tree, insert t ...
- LeetCode:二叉搜索树中第K小的数【230】
LeetCode:二叉搜索树中第K小的数[230] 题目描述 给定一个二叉搜索树,编写一个函数 kthSmallest 来查找其中第 k 个最小的元素. 说明:你可以假设 k 总是有效的,1 ≤ k ...
- LeetCode:二叉搜索树中的搜索【700】
LeetCode:二叉搜索树中的搜索[700] 题目描述 给定二叉搜索树(BST)的根节点和一个值. 你需要在BST中找到节点值等于给定值的节点. 返回以该节点为根的子树. 如果节点不存在,则返回 N ...
- Leetcode 701. 二叉搜索树中的插入操作
题目链接 https://leetcode.com/problems/insert-into-a-binary-search-tree/description/ 题目描述 给定二叉搜索树(BST)的根 ...
- LeetCode 230. 二叉搜索树中第K小的元素(Kth Smallest Element in a BST)
230. 二叉搜索树中第K小的元素 230. Kth Smallest Element in a BST 题目描述 给定一个二叉搜索树,编写一个函数 kthSmallest 来查找其中第 k 个最小的 ...
随机推荐
- UVA - 11093 Just Finish it up(环形跑道)(模拟)
题意:环形跑道上有n(n <= 100000)个加油站,编号为1~n.第i个加油站可以加油pi加仑.从加油站i开到下一站需要qi加仑汽油.你可以选择一个加油站作为起点,起始油箱为空(但可以立即加 ...
- POJ 1944:Fiber Communications
Fiber Communications Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 4236 Accepted: 1 ...
- 1834 [ZJOI2010]network 网络扩容
题解:先在原网络上跑最大流,然后加上带费用的边跑费用流 高一的时候做这道题怎么想不到? 注意:maxn代表的不一定是同一个变量的范围 #include<iostream> #include ...
- 一、SAP中添加一个模块到收藏夹后,显示事务代码
一.在SAP中,如果添加一个模块到收藏夹,默认是看不到事务代码的,如图: 二.我们在附件->设置中勾选显示技术名称 三.保存之后,就会显示出事务代码,如图所示: 不忘初心,如果您认为这篇文章有价 ...
- 十、CI框架之通过参数的办法输出URI路径
一.代码如下,index函数有2个参数 二.效果如下: 不忘初心,如果您认为这篇文章有价值,认同作者的付出,可以微信二维码打赏任意金额给作者(微信号:382477247)哦,谢谢.
- java集合对象实现原理
1.集合包 集合包是java中最常用的包,它主要包括Collection和Map两类接口的实现. 对于Collection的实现类需要重点掌握以下几点: 1)Collection用什么数据结构实现? ...
- jQuery课上笔记19.5.17
jQuery 选择器 $("*"):所有元素 $("#idname"):id="idname"的元素 $(".classname& ...
- 吴裕雄--天生自然TensorFlow2教程:张量限幅
import tensorflow as tf a = tf.range(10) a # a中小于2的元素值为2 tf.maximum(a, 2) # a中大于8的元素值为8 tf.minimum(a ...
- mybatis+maven+父子多模块进行crud以及动态条件查询
使用IDEA创建maven项目,File→New→Project→maven→Next→填写GroupId(例:com.zyl)和ArtifactId(mybatis-demo-parent)→Nex ...
- 强制浏览器以IE8版本运行
做为一个开发人员,经常被要求前端页面兼容ie8及以上,所以有时候我们希望ie默认以ie8的版本打开我们的页面. 1.“文档模式”: 在html页面中加入类似下面的代码: <meta http-e ...