[python每日一练]--0012:敏感词过滤 type2
题目链接:https://github.com/Show-Me-the-Code/show-me-the-code
代码github链接:https://github.com/wjsaya/python_spider_learn/tree/master/python_daily
个人博客地址:https://wjsaya.github.io
第 0012 题: 敏感词文本文件 filtered_words.txt,里面的内容 和 0011题一样,当用户输入敏感词语,则用 星号 替换,例如当用户输入「北京是个好城市」,则变成「*是个好城市」。
思路:
- 从文件解析敏感词、从终端获取用户输入。
- 根据敏感词对用户输入进行过滤。这里过滤需要考虑到输入内容不止一个需要过滤的词,所以稍微麻烦点:
- 读取所有的屏蔽词,放进一个列表
- 获取用户输入
- 遍历屏蔽词列表,用屏蔽词检索用户输入
- 如果有屏蔽词,将其替换为*
- 如果没有,不进行操作
- 返回处理后的用户输入
- 用下一个屏蔽词对处理后的用户输入进行上述操作
- 所有屏蔽词遍历完毕,输出过滤后字符串
敏感词列表(filtered_words.txt)
|
|
代码:
|
|
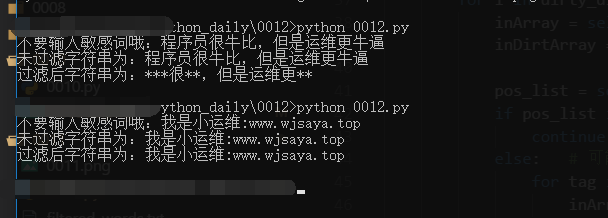
效果图:
[python每日一练]--0012:敏感词过滤 type2的更多相关文章
- DFA和trie特里实现敏感词过滤(python和c语言)
今天的项目是与完成python开展,需要使用做关键词检查,筛选分类,使用前c语言做这种事情.有了线索,非常高效,内存小了,检查快. 到达python在,第一个想法是pip基于外观的c语言python特 ...
- 8.2 前端检索的敏感词过滤的Python实现(针对元搜索)
对于前端的搜索内容进行控制,比如敏感词过滤,同样使用socket,这里使用Python语言做一个demo.这里不得不感叹一句,socket真是太神奇了,可以跨语言把功能封装,为前端提供服务. 下面就是 ...
- Python 每日一练(4)
引言 今天继续是python每日一练的几个专题,主要涵盖简单的敏感词识别以及图片爬虫 敏感词识别 这个敏感词的识别写的感觉比较简单,总的概括之后感觉功能可以简略成if filter_words in ...
- 超强敏感词过滤算法第二版 可以忽略大小写、全半角、简繁体、特殊符号、HTML标签干扰
上一篇 发一个高性能的敏感词过滤算法 可以忽略大小写.全半角.简繁体.特殊符号干扰 改进主要有几点: 用BitArray取代Dictionary用空间换时间 性能进一步提升 大概会增加词库的 6k* ...
- 5分钟构建无服务器敏感词过滤后端系统(基于FunctionGraph)
摘要:开发者通过函数工作流,无需配置和管理服务器,以无服务器的方式构建应用,便能开发出一个弹性高可用的后端系统.托管函数具备以毫秒级弹性伸缩.免运维.高可靠的方式运行,极大地提高了开发和运维效率,减小 ...
- 基于DFA算法、RegExp对象和vee-validate实现前端敏感词过滤
面临敏感词过滤的问题,最简单的方案就是对要检测的文本,遍历所有敏感词,逐个检测输入的文本是否包含指定的敏感词. 很明显上面这种实现方法的检测时间会随着敏感词库数量的增加而线性增加.系统会因此面临性能和 ...
- java实现敏感词过滤(DFA算法)
小Alan在最近的开发中遇到了敏感词过滤,便去网上查阅了很多敏感词过滤的资料,在这里也和大家分享一下自己的理解. 敏感词过滤应该是不用给大家过多的解释吧?讲白了就是你在项目中输入某些字(比如输入xxo ...
- 用php实现一个敏感词过滤功能
周末空余时间撸了一个敏感词过滤功能,下边记录下实现过程. 敏感词,一方面是你懂的,另一方面是我们自己可能也要过滤一些人身攻击或者广告信息等,具体词库可以google下,有很多. 过滤敏感词,使用简单的 ...
- 浅析敏感词过滤算法(C++)
为了提高查找效率,这里将敏感词用树形结构存储,每个节点有一个map成员,其映射关系为一个string对应一个TreeNode. STL::map是按照operator<比较判断元素是否相同,以及 ...
随机推荐
- div 命名规范! (野路子出来的好好看看)
DIV命名规范 DIV命名规范 企业DIV使用频率高的命名方法 网页内容类 --- 注释的写法: /* Footer */ 内容区/* End Footer */ 摘要: summary 箭头: ...
- uniapp结合小程序第三方插件“WechatSI”实现语音识别功能,进而实现终端控制
最近在用soket实现终端控制器的功能,然后就想用语音控制,这样显得更AI WechatSI在manifest.json中配置: 在vue中插入如下展示代码: <view class=" ...
- C++中free()与delete的区别
1.new/delete是C++的操作符,而malloc/free是C中的函数. 2.new做两件事,一是分配内存,二是调用类的构造函数:同样,delete会调用类的析构函数和释放内存.而malloc ...
- C++ for循环遍历几种写法
最近写for循环,发现以前用过的方法都忘记了,这里整理下几种方法,欢迎大佬补充: 1. for(itnt n =1;n<5;n++) { } 2. for (auto it = list.beg ...
- Pickle的简单使用
单词Pickle的中文意思是“泡菜.腌菜.菜酱”的意思,Pickle是Python的一个包,主要功能是对数据进行序列化和反序列化.那么什么叫序列化和反序列化呢? 其序列化过程就是把数据转化成二进制数据 ...
- 吴裕雄--天生自然python学习笔记:python 用pygame模块开发俄罗斯方块游戏
俄罗斯方块游戏 多年前,游戏机中最流行的游戏就是“俄罗斯方块”了.时至今日,虽然网络 游戏日新月异 ,但“俄罗斯方块”这款小游戏仍在许多人心中 占有一席之地.本例中, 我们将亲手设计一个简单的俄罗斯方 ...
- java replaceall 用法:处理特殊字符
public class TryDotRegEx { public static void main(String[] args) { // TODO Auto-generated method st ...
- <USACO09DEC>视频游戏的麻烦Video Game Troublesの思路
emm今天模拟赛的题.神奇地A了 #include<cstdio> #include<cstring> #include<iostream> #include< ...
- 分布式全局唯一ID与自增序列
包含时间顺序的ID 此场景最简单的实现方案,就是采用 twitter 的 Snowflake 算法.ID总长64位,第1位不可用,41位表示时间戳,10位表示生成机器的id,后12位表示序列号. 为什 ...
- [LC] 345. Reverse Vowels of a String
Write a function that takes a string as input and reverse only the vowels of a string. Example 1: In ...