Ambari安装指南
一、准备工作
l 基本工具
1) 安装epel,epel是一个提供高质量软件包的项目。先检查主机上是否安装:
rpm -q epel-release
2) 如果没有安装,使用rpm命令安装:
rpm -ivh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
(也可手动下载安装包安装)
3) 成功后查看其所依附的软件包:
rpm -qR epel-release
4) 导入key:
rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
5) 安装yum-priority:
yum install yum-priorities
6) 在主机仓库目录中可以查到epel.repo,命令:
①
cd /etc/yum.repos.d
②
ls | grep epel
7) 安装pdsh:
yum install pdsh
l 配置/etc/hosts和/etc/sysconfig/network
以Ambari节点下修改hosts文件为例说明:(本机192.168.1.162/hadoop03)


l 设置ssh免密码登录
略…
l 关闭SELinux、防火墙、packagekit
1) 关闭SELinux
① 暂时关闭:
setenforce 0
② 永久关闭:
vi /etc/selinux/config
,将其中的SELinux设置:SELINUX=disabled
2) 关闭防火墙 :
chkconfig iptables off
3) 关闭packagekit:
vi /etc/yum/pluginconf.d/refresh-packagekit.conf
,将enabled设为0
二、安装
l 下载Ambari仓库
1) 进入yum.repos.d仓库目录:
cd /etc/yum.repos.d
2) 下载Ambari仓库的资源清单文件:
wget http://public-repo-1.hortonworks.com/ambari/centos6/1.x/updates/1.6.1/ambari.repo

l 安装epel repository
1) 安装epel:
yum install epel-release
2) 查看是否配置成功,命令:
yum repolist
,若成功,则应显示如下:

l 用yum安装Ambari,同时也会安装PostgreSQL.
安装命令:
yum install ambari-server
l 配置ambari-server
执行命令:
ambari-server setup
,如果还没有关闭SELinux,执行这个命令的过程中会提示,选择y。然后会配置PostgreSQL,选择y自动下载安装jdk。之后配置数据库,选n使用默认数据库用户名ambari-server和密码bigdata,选y自己创建用户名密码。
三、启动
l 启动Ambari
1) 执行命令:
ambari-server start
启动服务,出现如下页面表示启动成功:

注意:如果是用普通用户例如hadoop安装ambari,并且数据库是mysql,启动时会报错,解决方案:
① 在mysql中建立用户
grant all privileges on *.* to 'admin'@'hadoop05' identified by ‘admin’
;
创建ambari数据库。
② 用admin用户登录mysql,
use ambari
;然后
source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
,
导入ambari的sql脚本。
2) 在浏览器中输入“主机IP:8080”进入登陆界面,默认用户名密码为admin/admin。

这里要注意,前提是必须安装好httpd,并且启动httpd服务:
① 查看是否安装:
rpm -qa | grep httpd
,如果没有,安装命令:
yum install httpd
② 修改配置文件:
vi /etc/httpd/conf/httpd.conf
,如下:


③ 重启主机:
shutdown -r now
,等启动完成后,启动httpd服务:
servie httpd start
3) Ambari的相关配置命令
① 修改端口号:
vi /etc/ambari-server/conf/ambari.properties
,在文件中增加client.api.port=<port_number>,本机port_number修改为8888。
② 查看Ambari进程:
ps -ef | grep ambari
③ 停止Ambari进程:
ambari-server stop
④ 重启Ambari进程:
ambari-server restart
四、磁盘扩容
问题引入:后续进行MR Job执行时,会报类似“磁盘空间不够”的错误,原因是Ambari安装所在目录的磁盘容量不够导致。
解决方案:由于Ambari安装后,会创建一个LVM的逻辑卷,供Hadoop运行产生的临时文件存储用,如下:

所以,我们只需要对vg_hadoop01进行扩容。操作如下:
1) 1表示第一块分区的信息,该分区已经被Hadoop占满;2表示第二块分区的信息,也就是我们需要将它扩容到vg_hadoop01上的分区。如下:

2) 现将/dev/sdb5分区块(注意这里Id必须是8e,System必须是Linux LVM)分配给vg_hadoop01.
① 8e和Linux LVM的设置命令:
fdisk /dev/sdb
,接着按m,根据提示设置。

② 输入命令:partprobe,让分区表生效。

③ 由于LVM所在的文件类型是ext4,所以新的分区必须格式化为ext4.

格式化命令:
mkfs –t ext4 /dev/sdb5
.
④ 创建PV(物理卷),命令:
pvcreate /dev/sdb5
,利用:pvdisplay查看:
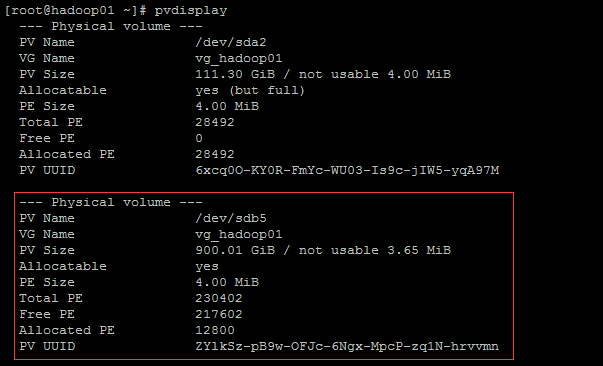
⑤ 扩容LVM,命令:
vgextend vg_hadoop01 /dev/sdb5
,利用:vgdisplay查看:

⑥ 将LVM中的容量扩展到LV(逻辑卷),命令:
lvextend –L 100G /dev/vg_hadoop01/lv_root
,将分区/dev/vg_hadoop01/lv_root的容量扩充到100G.利用lvdisplay查看:

3) 执行该重设大小,对于当前正在使用的/dev/vg_hadoop01/lv_root有效.命令:
resize2fs /dev/vg_hadoop01/lv_root
,查看扩容后的挂载情况:df -lhT.

Ambari安装指南的更多相关文章
- Ambari配置Hive,Hive的使用
mysql安装,hive环境的搭建 ambari部署hadoop 博客大牛:董的博客 ambari使用 ambari官方文档 hadoop 2.0 详细配置教程 使用Ambari快速部署Hadoop大 ...
- 【原创】大数据基础之Ambari(1)简介、编译安装、使用
官方:http://ambari.apache.org/ The Apache Ambari project is aimed at making Hadoop management simpler ...
- CentOS7离线安装Ambari与HDP
安装步骤总体说明 1.安装以前需要先规划服务器,一台主机多台从机.主从需要设置时间同步和免密. 2.建立离线源,因在线安装速度很慢,所以需要建立离线源. 3.在主机上安装Ambari,进入系统后,挂接 ...
- nGrinder安装指南
NGrinder 由两个模块组成,其运行环境为 Oracle JDK 1.6 nGrinder controller web 应用程序,部署在Tomcat 6.x 或更高的版本 nGrinder A ...
- postgresql pgsql最新版安装指南及数据存储路径更改及主从配置
postgresql pgsql最新版安装指南及数据存储路径更改及主从配置 安装指南 首先在apt的list添加你当前系统版本对应的apt列表 目前官网有16.04,14.04,12.04 分别对应下 ...
- Ambari组件黄色预警
Ambari组件黄色预警 组件上为黄色问号,代表心跳丢失,解决如下: 1. 查看个节点之间是否可以相互通信,若ssh连接不上,有可能是该节点关机了,没有打开,手动开启该节点,再次验证是否可互通. 2 ...
- 全新 Mac 安装指南(编程篇)(环境变量、Shell 终端、SSH 远程连接)
注:本文专门用于指导对计算机编程与设计(尤其是互联网产品开发与设计)感兴趣的 Mac 新用户,如何在 Mac OS X 系统上配置开发与上网环境,另有<全新 Mac 安装指南(通用篇)>作 ...
- 全新 Mac 安装指南(通用篇)(推荐设置、软件安装、推荐软件)
注:本文将会不定期维护与更新,有需要的朋友请在 Github 上订阅该条 Issues:<全新 Mac 安装指南(通用篇)>. 在 Mac 电脑上只用 Windows 操作系统的同学请看到 ...
- ArchLinux安装指南
将ArchLinux作为进阶Linux发行版,主要看重滚动更新和深入理解Linux的安装过程. 由于是新手,所以先选择在公司电脑上用VMware来安装.然后渐进到借助U盘在win10笔记本上安装双系统 ...
随机推荐
- Spring和Spring MVC包扫描
在Spring整体框架的核心概念中,容器是核心思想,就是用来管理Bean的整个生命周期的,而在一个项目中,容器不一定只有一个,Spring中可以包括多个容器,而且容器有上下层关系,目前最常见的一种场景 ...
- [LeetCode] 181. Employees Earning More Than Their Managers_Easy tag: SQL
The Employee table holds all employees including their managers. Every employee has an Id, and there ...
- Keras 源码分析
. │ activations.py │ callbacks.py │ constraints.py │ initializations.py │ metrics.py │ models.py │ o ...
- vs计算代码行数
1.用vs打开程序 2.编辑——查找——在文件中查找 3.查找内容^b*[^:b#/]+.*$ 应用正则表达式,在整个解决方案中,文件类型空 4.查找全部,仔细盯着右下角数字,查找完毕后会自动消失 ...
- chrome浏览器使用
1.如何打开多个历史网页.这个需求是这样的,有时候开了多个网页查找资料,但是又还没有做完,然后又需要重启电脑.显然重启电脑后再开启浏览器,一般都是显示浏览器的主页了,上次开的那些网页全部在历史记录里面 ...
- YUV编码格式
YUV是被欧洲电视系统采用的一种颜色编码方法.在现代彩色电视系统中,通常采用三管彩色摄影机或彩色CCD摄像机取像,然后把取 得的彩色图像信号经过分色,分别放大校正后得到RGB,在经过矩阵变换电路,得到 ...
- VS2010/MFC编程入门之四十五(MFC常用类:CFile文件操作类)
上一节中鸡啄米讲了定时器Timer的用法,本节介绍下文件操作类CFile类的使用. CFile类概述 如果你学过C语言,应该知道文件操作使用的是文件指针,通过文件指针实现对它指向的文件的各种操作.这些 ...
- CE寻找游戏基址
什么是游戏基址? 游戏基址是保持恒定的两部分内存地址的一部分并提供一个基准点,从这里可以计算一个字节数据的位置.基址伴随着一个加到基上的偏移值来确定信息准确的位置(绝对地址). 全局基址 一级基址 二 ...
- 20154312 曾林 EXP7 网络欺诈防范
目录 1.基础问题回答 ----1.1.通常在什么场景下容易受到DNS spoof攻击 ----1.2.在日常生活工作中如何防范以上两攻击方法 2.实践总结与体会 3.实践过程记录 ----3.1.简 ...
- iframe嵌套
iframe基本内涵 通常我们使用iframe直接直接在页面嵌套iframe标签指定src就可以了. <iframe src="demo_iframe_sandbox.htm" ...