Spark On YARN 分布式集群安装
一、导读
最近开始学习大数据分析,说到大数据分析,就必须提到Hadoop与Spark。要研究大数据分析,就必须安装这两个软件,特此记录一下安装过程。Hadoop使用V2版本,Hadoop有单机、伪分布式、分布式三种部署方案,这里使用分布式部署方案。而Spark有三种部署方案:Standalone, Mesos, YARN,而本文采用在YARN上的分布式集群部署方案。
具体软件环境:
Ubuntu 14.04. LTS (GNU/Linux 3.16.--generic x86_64)
jdk: 1.7.0_95
scala: 2.10.
Hadoop: 2.6.
Spark: 1.6.
集群环境:(3台主机)
master #主节点
slave1 #从节点1
salve2 #从节点2
二、准备工作
重命名主机
准备好三台Linux系统的主机后,将三台主机进行重命名,采用下面的命令
sudo vim /etc/hostname
将1台主机名称改为master,另外两台主机改为slave1与slave2。
配置hosts文件
在每台主机上修改hosts文件,配置文件如下:
127.0.0.1 localhost
10.21.71.132 master
10.21.71.125 slave1
10.21.71.119 slave2
配置完成后,需要使用ping命令测试修改是否生效
ping master
ping slave1
ping slave2
SSH免密码登录
SSH(Secure Shell)是类Unix系统上进行远程登录的安全协议,简单理解为远程加密登录。集群安装需要使用SSH登录,Ubuntu自带Client端,需要安装Server端,命令如下:
sudo apt-get install openssh-server
免密码登录需要进行一定的配置,通过RSA生成公钥与私钥,将公钥发送给其他主机,其他主机把它加入authorized_keys,自己保留私钥,以后就可进行免密码登录。这里公钥相当于锁头,私钥相当于钥匙,当其他主机接收到公钥并进行授权后,相当于公钥对其他主机进行加密,可以使用私钥解密。
- 在所有的机器上生成私钥和公钥
sudo ssh-keygen -t rsa #一路回车
2. 让master能进行自身登录与被slave1与slave2访问,将两台slav2机器公钥发给master
# 将两台slave机器公钥发给master主机
scp ~/.ssh/id_rsa.pub hadoop@master:~/.ssh/id_rsa.pub.slave1
scp ~/.ssh/id_rsa.pub hadoop@master:~/.ssh/id_rsa.pub.slave2
# master主机上,将所有公钥加入被认证的公钥文件
cat ~/.ssh/id_rsa.pub* >> ~/.ssh/authorized_keys
此时,应该slave1与slave2能够登录master主机并且master能够自身登录。
3. 让每台主机互相免密码登录。将公钥文件分发给每台slave
scp ~/.ssh/authorized_keys hadoopk@slave1:~/.ssh/
scp ~/.ssh/authorized_keys hadoopk@slave2:~/.ssh/
4. 在每台主机验证SSH免密码登录。
ssh master
ssh slave1
ssh slave2
三、安装Java
虽然Linux自带了OpenJDK,但感觉还是要下载官网的JDK,Spark需要JDK6以上的版本,我下的版本为JDK1.7,使用下面的命令进行解压:
sudo tar zxvf jdk-7u79-linux-x64.gz -C /usr/local/
然后修改环境变量
sudo vi /etc/profile/
在文件末尾添加相应的环境变量
export JAVA_HOME=/usr/local/jdk1.
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
重新载入环境变量,并查看JAVA是否安装成功
$ source /etc/profile #生效环境变量
$ java -version #如果打印出如下版本信息,则说明安装成功
java version "1.7.0_79"
Java(TM) SE Runtime Environment (build 1.7.0_79-b15)
Java HotSpot(TM) -Bit Server VM (build 24.79-b02, mixed mode)
四、安装Scala
因为Spark1.6.1需要版本Scala版本为2.10.x,因此在官网下载地址下载了2.10.6版本,下载后解压
sudo tar zxvf scala-2.10..tgz -C /usr/local/
再次添加环境变量,再次使用使用
sudo vi /etc/profile
添加以下内容:
export SCALA_HOME=/usr/local/scala-2.10.
export PATH=$PATH:$SCALA_HOME/bin
重新载入环境变量,并验证scala是否安装成功
$ source /etc/profile #重新载入环境变量
$ scala -version #查看scala安装版本,如出现以下版本信息,则安装成功
Scala code runner version 2.10. — Copyright -, LAMP/EPFL
五、Hadoop安装
下载Hadoop
从官网下载Hadoop2.6.0版本,官网下载地址,下载成功后解压
tar -zxvf hadoop-2.6..tar.gz -C /opt/
配置Hadoop
Hadoop的集群部署模式需要修改Hadoop文件夹中/etc/hadoop/中的配置文件,更多设置项可见官方说明,这里只设置了常见的设置项:hadoop-env.sh,yarn-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、slaves。
- 在hadoop-env.sh中配置JAVA_HOME
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk1. - yarn-env.sh中配置JAVA_HOME
# some Java parameters
export JAVA_HOME=/usr/local/jdk1. - core-site.xml为全局配置文件,修改core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>dfs.http.address</name>
<value>50070</value>
</property>
</configuration> - hdfs-site.xml为HDFS的配置文件,修改hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration> - mapred-site.xml为MapReduce的配置文件,修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> - yarn-site.xml为YARN资源管理器的配置文件,修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> - slaves文件配置从节点,配置slaves
slave1
slave2
将配置好的Hadoop文件夹分发给slaves
scp -r /opt/hadoop-2.6. hadoop@slave1:/opt/
scp -r /opt/hadoop-2.6. hadoop@slave2:/opt/
验证Hadoop是否安装成功
启动Hadoop,只需要在master进行下列操作即可
cd /opt/hadoop-2.6. #进入Hadoop目录
sudo bin/hadoop namenode –format #格式化namenode
sbin/start-dfs.sh #启动HDFS
sbin/start-yarn.sh #启动资源管理器
用jps查看机器上的进程,是否包含以下的进程:
master上的进程:
SecondaryNameNode
Jps
ResourceManager
NameNode
slave上的进程:
DataNode
Jps
NodeManager
进入Hadoop的Web管理页面:http://master:50070/
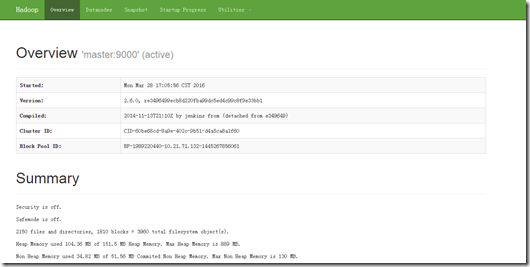
六、Spark安装
下载Spark
进入官方网站下载最新Spark,下载地址,这里我下载的是spark-1.6.1-bin-hadoop2.6.tgz,能够在Hadoop2.6及更高版本上运行。
下载后,进行解压
sudo tar -zxvf spark-1.6.-bin-hadoop2..tgz -C /opt/
sudo mv spark-1.6.-bin-hadoop2./ spark-1.6. #重命名文件
配置Spark
cd /opt/spark-1.6./conf/
cp spark-env.sh.template spark-env.sh
sudo vi spark-env.sh
在Spark-env.sh文件尾部添加以下配置:
export JAVA_HOME=/usr/local/jdk1. #Java环境变量
export SCALA_HOME=/usr/local/scala-2.10. #SCALA环境变量
export SPARK_WORKING_MEMORY=1g #每一个worker节点上可用的最大内存
export SPARK_MASTER_IP=master #驱动器节点IP
export HADOOP_HOME=/opt/hadoop #Hadoop路径
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop #Hadoop配置目录
配置slave主机
$ cp slaves.template slaves
$ sudo vim slaves
添加slave主机
slave1
slave2
将配置好的Spark分发给所有的slave
scp -r /opt/spark-1.6. hadoop@slave1:~/opt/
验证Spark是否安装成功
使用下面的命令,运行Spark
sbin/start-all.sh
用jps查看机器上的进程,是否包含以下的进程:
master上的进程: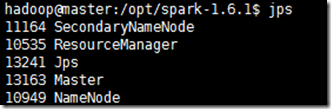
slave上的进程:
进入Spark的Web管理页面:http://master:8080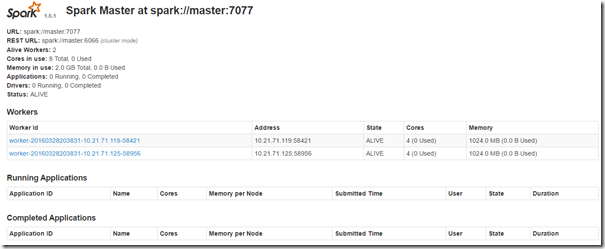
运行简单示例
当需要运行Spark终端,必须将Spark的bin目录加入到系统路径。
export SPARK_HOME=/opt/spark-1.6.
export PATH=$PATH:${SPARK_HOM}/bin
添加Spark的bin目录路径后,运行
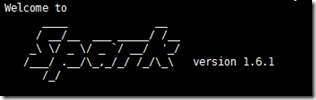
spark-shell
查看是否出现欢迎界面,并可以运行scala脚本
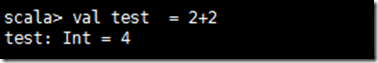
Spark On YARN 分布式集群安装的更多相关文章
- (转)ZooKeeper伪分布式集群安装及使用
转自:http://blog.fens.me/hadoop-zookeeper-intro/ 前言 ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品.在单机中,系统协作大都是进程级的 ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- 一张图讲解最少机器搭建FastDFS高可用分布式集群安装说明
很幸运参与零售云快消平台的公有云搭建及孵化项目.零售云快消平台源于零售云家电3C平台私有项目,是与公司业务强耦合的.为了适用于全场景全品类平台,集团要求项目平台化,我们抢先并承担了此任务.并由我来主 ...
- ZooKeeper伪分布式集群安装及使用
ZooKeeper伪分布式集群安装及使用 让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务. 现在硬件越来越 ...
- CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装
1 2 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 2.9.1 2.9.2 2.9.2.1 2.9.2.2 2.9.3 2.9.3.1 2.9.3.2 2.9.3.3 2. ...
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
- Hadoop2.8分布式集群安装与测试
1.hadoop2.x 概述 个).每一个都有相同的职能.一个是active状态的,一个是standby状态的.当集群运行时,只有active状态的NameNode是正常工作的,standby状态的N ...
- hadoop2.7.7 分布式集群安装与配置
环境准备 服务器四台: 系统信息 角色 hostname IP地址 Centos7.4 Mster hadoop-master-001 10.0.15.100 Centos7.4 Slave hado ...
随机推荐
- Map集合遍历
Map<String,String> map = new HashMap<String, String>(); map.put("1","java ...
- [python-opencv]图像二值化【图像阈值】
图像二值化[图像阈值]简介: 如果灰度图像的像素值大于阈值,则为其分配一个值(可以是白色255),否则为其分配另一个值(可以是黑色0) 图像二值化就是将灰度图像上的像素值设置为0或255,也就是将整个 ...
- 在mysql Navicat中怎样设置ID自动递增
1.打开设计表 2.在添加或变更表结构时,把id字段设置为整型,下面的选项就会出现auto increment的选择框,勾选中就可以了.
- Dubbo简单环境搭建
Dubbo服务的发展和作用: 首先,看下一般网站架构随着业务的发展,逻辑越来越复杂,数据量越来越大,交互越来越多之后的常规方案演进历程. 其次,当服务越来越多之后,我们需要做哪些服务治理? 最后,是d ...
- pycharm中python模板代码自动生成
# -*- coding: utf-8 -*- """ ------------------------------------------------- File Na ...
- QQ公众号?是的,你没看错!
微信公众平台培育了800多万的微信公众号,自身也通过微信游戏.广告分销等找到了一些增值盈利模式.作为同门大师兄,qq也在11月份推出了QQ公众号,第一个手机QQ上的“生活服务号”——YTO圆通速递上线 ...
- android ImageView加圆角
1.attrs添加 <declare-styleable name="RoundImageView"> <attr name="circle" ...
- vue:Group XSwitch Actionsheet,Toast控件使用
<template> <div> <div class="vux-demo"> <img class="logo" s ...
- android activity and fragment活动周期
1.状态 /* 每个活动一共有四种状态 *:1.运行状态,就是栈顶的那个 * 2.暂停状态:就是不处于栈顶,但是依然可见,比如对话框下面的界面 * 3.停止状态:不处于栈顶,并且不可见 * 4.销毁状 ...
- Git warning:LF will be replaced by CRLF in readme.txt的原因与解决方案
今天用Git bash遇到的问题,看了几个回答之后发现一个比较有价值的,给大家分享一下,其他很多的回答都有很或多或少存在一些弊端. 原回答地址在stackoverflow上,附上链接--http:// ...