Hive环境的安装部署(完美安装)(集群内或集群外都适用)(含卸载自带mysql安装指定版本)
Hive 安装依赖 Hadoop 的集群,它是运行在 Hadoop 的基础上。 所以在安装 Hive 之前,保证 Hadoop 集群能够成功运行。
同时,比如我这里的master、slave1和slave2组成的hadoop集群。hive的安装可以安装在任一一个节点上,当然,也可以安装在集群之外,取名为client。只需要ssh免密码通信即可。
1、 下载Hive
这里很简单,不多赘述。
http://archive.apache.org/dist/
2、安装Hive
把Hive安装包apache-hive-1.0.0-bin.tar.gz移动到/home/hadoop/app/目录下并解压,然后将文件名称改为 hive-1.0.0。并做好软链接(实现多版本切换,别问这么多,高手必须掌握的技巧)
[hadoop@master app]$ tar -zxvf apache-hive-1.0.0-bin.tar.gz
[hadoop@master app]$ mv apache-hive-1.0.0-bin hive-1.0.0
[hadoop@master app]$ ln -s hive-1.0.0 hive
添加hive环境变量

[root@master ~]$ vi /etc/profile #hive
export HIVE_HOME=/home/hadoop/app/hive
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin:$PATH [root@master ~]# source /etc/profile

3、安装为hive存放元数据的MySQL
Hive 将元数据存储在 RDBMS 中,一般常用 MySQL 和 Derby。默认情况下,Hive 元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的测试。实际生产环境中不适用, 为了支持多用户会话,则需要一个独立的元数据库,使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持,配置一个独立的元数据库需要增加以下步骤。
如果你是一名有经验大数据工程师,无论是安装jdk(注意:CentOS6.5有自带的jdk),还是安装mysql。都是先查看系统是否已经安装Mysql包。
[root@master app]# rpm -qa|grep mysql
mysql-libs-5.1.71-1.el6.x86_64
[root@master app]# rpm -e --nodeps mysql-libs-5.1.71-1.el6.x86_64
[root@master app]# rpm -qa|grep mysql
[root@master app]#
在线安装 mysql 数据库
[root@master app]# yum install mysql-server
Loaded plugins: fastestmirror
Determining fastest mirrors
* base: mirrors.yun-idc.com
* extras: mirrors.btte.net
* updates: mirrors.163.com
....
Is this ok [y/N]: y
...

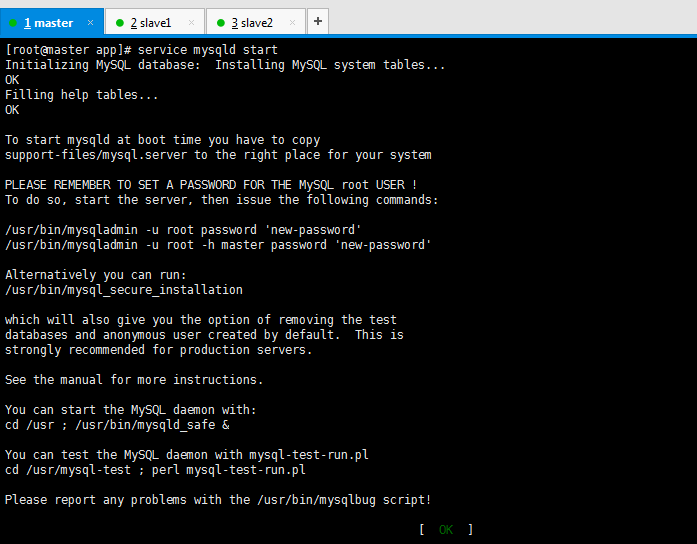
启动mysql服务
[root@master app]# service mysqld start
Initializing MySQL database: Installing MySQL system tables...
OK
Filling help tables...
OK To start mysqld at boot time you have to copy
support-files/mysql.server to the right place for your system
...
设置 mysql 的 root 密码
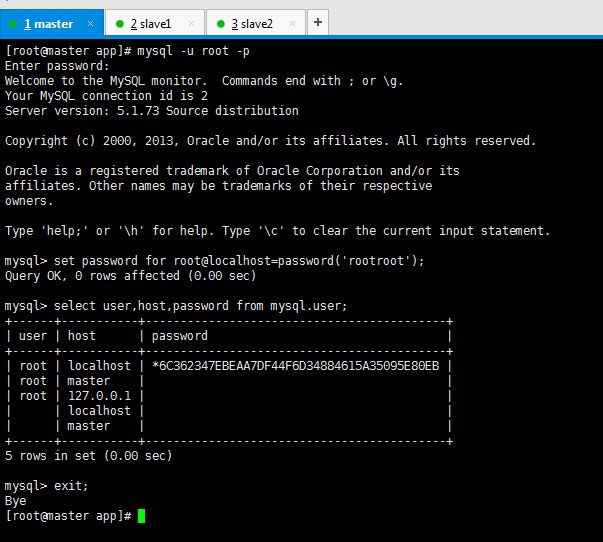
MySQL在刚刚被安装的时候,它的 root 用户是没有被设置密码的,即回车就好。但是一般需要自定义配置,首先来设置 MySQL 的 root 密码。
[root@master app]# mysql -u root -p
Enter password: //默认密码为空,输入后回车即可
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.1.73 Source distribution
Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.
mysql> set password for root@localhost=password('rootroot'); 密码设置为rootroot
默认情况下Mysql只允许本地登录,所以只需配置root@localhost就好
mysql> set password for root@%=password('rootroot'); 密码设置为rootroot (其实这一步可以不配)
mysql> set password for root@master=password('rootroot'); 密码设置为rootroot (其实这一步可以不配)
mysql> select user,host,password from mysql.user; 查看密码是否设置成功
mysql> exit;
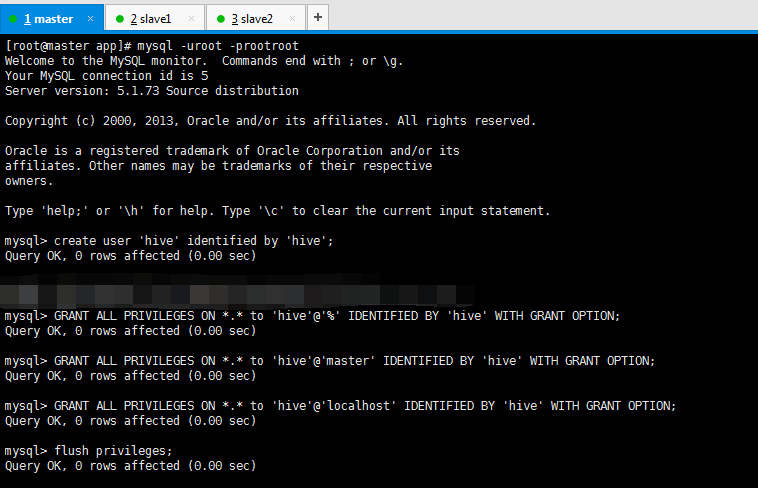
为 Hive 建立相应的 Mysql 账户,并赋予足够的权限。
[root@master app]# mysql -uroot -prootroot
mysql> create user 'hive' identified by 'hive'; //创建一个账号:用户名为hive,密码为hive 或者
mysql> create user 'hive'@'%' identified by 'hive'; //创建一个账号:用户名为hive,密码为hive
mysql> GRANT ALL PRIVILEGES ON *.* to 'hive'@'%' IDENTIFIED BY 'hive' WITH GRANT OPTION; //将权限授予host为%即所有主机的hive用户
mysql> GRANT ALL PRIVILEGES ON *.* to 'hive'@'master' IDENTIFIED BY 'hive' WITH GRANT OPTION; //将权限授予host为master的hive用户
mysql> GRANT ALL PRIVILEGES ON *.* to 'hive'@'localhost' IDENTIFIED BY 'hive' WITH GRANT OPTION; //将权限授予host为localhost的hive用户(其实这一步可以不配)
默认情况下Mysql只允许本地登录,所以需要修改配置文件将地址绑定给注释掉。 Query OK, 0 rows affected (0.00 sec) mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec) mysql> select user,host,password from mysql.user; mysql> exit;

建立 Hive 专用的元数据库,记得用刚才创建的 “hive” 账号登录,命令如下。
[root@master app]# mysql -uhive -phive //用hive用户登录,密码hive
mysql> create database hive; //创建为hive存放的元数据库的名称为hive
Query OK, 1 row affected (0.00 sec)
mysql> exit;

找到Hive安装目录 conf/下的 hive-site.xml文件,修改以下几个属性。
如果conf/目录下没有 hive-site.xml文件,则需要拷贝一个名为hive-site.xml的文件。
[hadoop@master conf]$ cp hive-default.xml.template hive-site.xml
[hadoop@master conf]$ vi hive-site.xml
< property>
< name>javax.jdo.option.ConnectionDriverName< /name>
< value>com.mysql.jdbc.Driver< /value>
< description>Driver class name for a JDBC metastore< /description>
< /property> < property>
< name>javax.jdo.option.ConnectionURL< /name>
< value>jdbc:mysql://master:3306/hive?characterEncoding=UTF-8< /value>
< description>JDBC connect string for a JDBC metastore< /description>
< /property> < property>
< name>javax.jdo.option.ConnectionUserName< /name>
< value>hive< /value>
< description>Username to use against metastore database< /description>
< /property> < property>
< name>javax.jdo.option.ConnectionPassword< /name>
< value>hive< /value>
< description>password to use against metastore database< /description>
< /property>
在hive 安装目录下,创建一个临时的IO文件iotmp,专门为hive来存放临时的io文件。
[hadoop@master hive]$ pwd
/home/hadoop/app/hive
[hadoop@master hive]$ mkdir iotmp
[hadoop@master hive]$ ls
bin derby.log hcatalog lib metastore_db README.txt scripts
conf examples iotmp LICENSE NOTICE RELEASE_NOTES.txt
然后将路径配置到hive-site.xml文件的以下参数中:
[hadoop@master conf]$ vi hive-site.xml
< property>
< name>hive.querylog.location< /name>
< value>/home/hadoop/app/hive/iotmp< /value>
< description>Location of Hive run time structured log file< /description>
< /property> < property>
< name>hive.exec.local.scratchdir< /name>
< value>/home/hadoop/app/hive/iotmp< /value>
< description>Local scratch space for Hive jobs< /description>
< /property> < property>
< name>hive.downloaded.resources.dir< /name>
< value>/home/hadoop/app/hive/iotmp< /value>
< description>Temporary local directory for added resources in the remote file system.< /description>
< /property>
将mysql-connector-java-5.1.21.jar驱动包,拷贝到 $HIVE_HOME/lib 目录下。
[hadoop@master lib]#pwd
/home/hadoop/app/hive/lib
[hadoop@master lib]#rz //回车,选择已经下载好的mysql驱动包即可
[hadoop@master lib]$ ls
mysql-connector-java-5.1.21.jar
开启hive前,先启动mysql和hadoop集群
[hadoop@master app]$ pwd
/home/hadoop/app
[hadoop@master app]$ service mysqld status
[hadoop@master app]$ service mysqld start




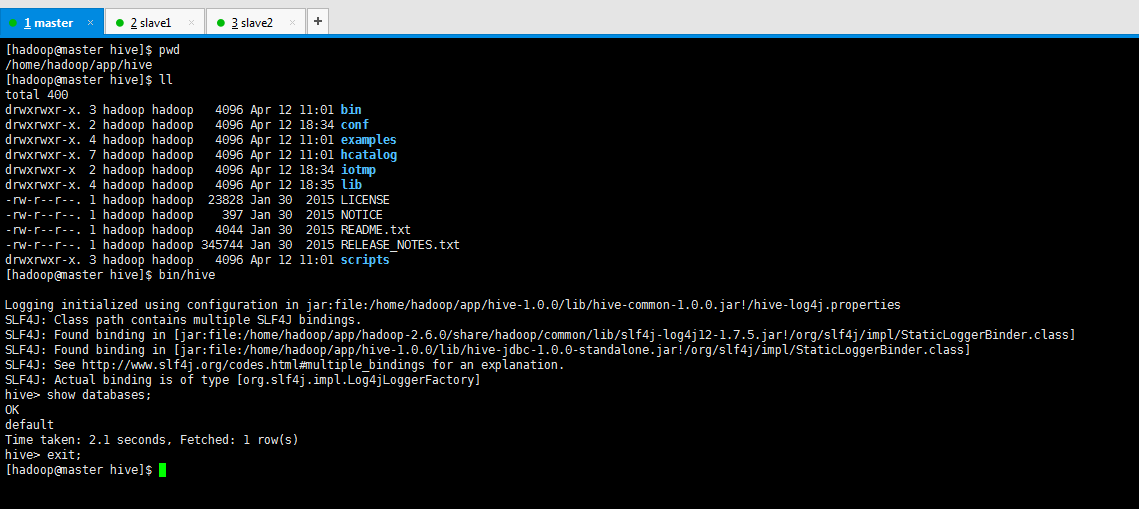
保存,开启hive即可。
[hadoop@master hive]$ pwd
/home/hadoop/app/hive
[hadoop@master hive]$ ll
total 400
drwxrwxr-x. 3 hadoop hadoop 4096 Apr 12 11:01 bin
drwxrwxr-x. 2 hadoop hadoop 4096 Apr 12 18:34 conf
drwxrwxr-x. 4 hadoop hadoop 4096 Apr 12 11:01 examples
drwxrwxr-x. 7 hadoop hadoop 4096 Apr 12 11:01 hcatalog
drwxrwxr-x 2 hadoop hadoop 4096 Apr 12 18:34 iotmp
drwxrwxr-x. 4 hadoop hadoop 4096 Apr 12 18:35 lib
-rw-r--r--. 1 hadoop hadoop 23828 Jan 30 2015 LICENSE
-rw-r--r--. 1 hadoop hadoop 397 Jan 30 2015 NOTICE
-rw-r--r--. 1 hadoop hadoop 4044 Jan 30 2015 README.txt
-rw-r--r--. 1 hadoop hadoop 345744 Jan 30 2015 RELEASE_NOTES.txt
drwxrwxr-x. 3 hadoop hadoop 4096 Apr 12 11:01 scripts
[hadoop@master hive]$ bin/hive
hive> show databases;
OK
default
Time taken: 3.684 seconds, Fetched: 1 row(s)
hive> exit;
Hive环境的安装部署(完美安装)(集群内或集群外都适用)(含卸载自带mysql安装指定版本)的更多相关文章
- VSTO安装部署(完美解决XP+2007)
从开始写VSTO的插件开始,安装部署一直就是一个很大的难题,其实难题的原因主要是针对XP+2007而言.在Win7上,由于基本上都预装了.net framework,所以安装起来其实问题不大. 主要需 ...
- 使用CentOS7卸载自带jdk安装自己的JDK1.8
不管在什么地方,什么时候,学习是快速提升自己的能力的一种体现!!!!!!!!!!! 关于JDK1.8 与之前的版本相比有哪些变化和新特性我也不在这详细的说明了,毕竟一度娘啥都有了,既然不多说那就直接开 ...
- CentOS5.5中卸载自带jdk 安装自己的jdk
因为需要使用JDK1.6的版本,但是RedHat6.4自带的JDK是1.7版本,因此需要卸载JDK1.7,安装JDK1.6的版本,我使用的JDK1.6版本为:jdk-6u45-Linux-x64.bi ...
- k8s暴露集群内和集群外服务的方法
集群内服务 一般 pod 都是根据 service 资源来进行集群内的暴露,因为 k8s 在 pod 启动前就已经给调度节点上的 pod 分配好 ip 地址了,因此我们并不能提前知道提供服务的 pod ...
- 编译安装带ssl 模块指定版本Python
出现这个或者fatal error: openssl/名单.h: No such file or directory.都是没有安装libssl-dev- libssl-dev包含libraries ...
- CentOS7卸载自带jdk安装自己的JDK1.8
1.查看centos自带的jdk rpm -qa | grep Java 2.删除自带的jdk 例如:rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b1 ...
- linux应用之mysql数据库指定版本的yum安装(centos)
A Quick Guide to Using the MySQL Yum Repository Abstract The MySQL Yum repository provides RPM packa ...
- Cloudera Manager安装之利用parcels方式安装单节点集群(包含最新稳定版本或指定版本的安装)(添加服务)(CentOS6.5)(四)
不多说,直接上干货! 福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 ...
- Azkaban2.5安装部署(系统时区设置 + 安装和配置mysql + Azkaban Web Server 安装 + Azkaban Executor Server安装 + Azkaban web server插件安装 + Azkaban Executor Server 插件安装)(博主推荐)(五)
Azkaban是什么?(一) Azkaban的功能特点(二) Azkaban的架构(三) Hadoop工作流引擎之Azkaban与Oozie对比(四) 不多说,直接上干货! http://www.cn ...
随机推荐
- tmux安装与使用
安装 用法 重点 一prefix前缀键 二window和pane的区分 tmux 按照官方给出的介绍是:终端复用工具.说白了就是可以仅仅在开启一个终端的情况下同时处理多个任务. 比如下面我设置的这样一 ...
- 题目1001:A+B for Matrices
题目1001:A+B for Matrices 时间限制:1 秒内存限制:32 兆 题目描述: This time, you are supposed to find A+B where A and ...
- spark 与 Hadoop 融合后启动 slf4j提示Class path contains multiple SLF4J bindings
相关参考文献: https://www.oschina.net/question/93435_174549 警告信息如下: 看起来明明就是一个文件,怎么还提示multiple bindings呢,sl ...
- linux shell except tcl login ssh Automatic interaction
/*************************************************************************************** * linux she ...
- win10笔记本实现双屏显示的自如切换
前言 使用电脑的过程中想一边看内容,一边进行编辑,这就涉及到双屏显示并实现扩展分屏,本文就介绍一下这些操作. 工具 win10-thinkpad-E470:另一块显示屏(博主的是戴尔的显示器):一条外 ...
- for (Sms sms : smsLists){}
for (Sms sms : smsLists){ } //类似下面的for循环 :Smslists[i]!=NULL;i++) { Sms sms=Smslists[i]; } /*其实就是把Sms ...
- 一定要记住这20种PS技术,让你的照片美的不行! - imsoft.cnblogs
照片名称:调出照片柔和的蓝黄色-简单方法, 1.打开原图素材,按Ctrl + J把背景图层复制一层,点通道面板,选择蓝色通道,图像 > 应用图像,图层为背景,混合为正片叠底,不透明度50%,反相 ...
- JAVA爬取百度贴吧图片
package com.wang.xiaowei.utils; import com.sun.image.codec.jpeg.JPEGCodec; import com.sun.image.code ...
- 《DSP using MATLAB》Problem 4.8
代码: %% ---------------------------------------------------------------------------- %% Output Info a ...
- 【C#】 增加多个分部类
有时需要在一个类下面增加多个不同功能的分部类,或者是不同开发组员以其命名的分部类. eg: 首先创建一个类,改为分部类,partial.. 复制此类的文件,改一个文件名.然后修改项目文件.csproj ...