INFINI Gateway 如何防止大跨度查询
背景
业务每天生成一个日期后缀的索引,写入当日数据。
业务查询有时会查询好多天的数据,导致负载告警。
现在想对查询进行限制--只允许查询一天的数据(不限定是哪天),如果想查询多天的数据就走申请。
技术分析
在每天一个索引的情况下,要进行多天的数据查询,有三种途径:
- 查询时,指定多个索引
- 查询时,写前缀+*号,模糊匹配多个索引
- 查询别名,别名关联多个索引
需求实现
我们只需用网关代理 ES 集群,并在 default_flow 中增加一段 request_path_filter 过滤器的配置,只允许查询一个索引且格式如 "xxx-2023-12-06", "xxx.2023.12.06", "xxx20231206" 。
- request_path_filter:
message: "Query scope exceeds limit, please contact the administrator for application."
must:
suffix:
- _search
regex:
- \/[a-z]+[-.]?\d{4}[-.]?\d{1,2}[-.]?\d{1,2}\/
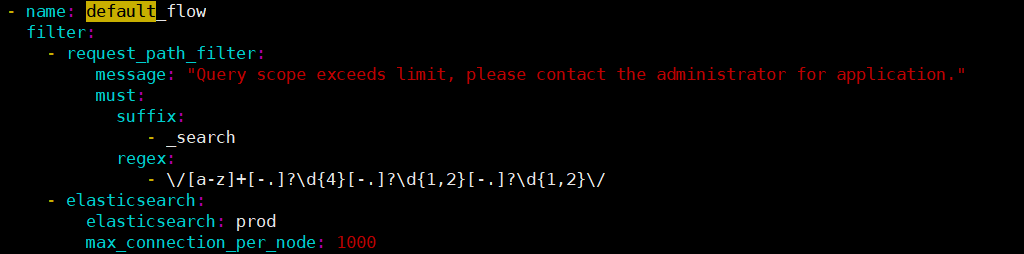
如果需要指定其他格式,请自行修改 regex 的正则表达式。
创建测试索引
在 INFINI Console 开发工具中执行下列语句:
POST test-2023-12-06/_doc
{
"test":"test"
}
POST test-2023-12-6/_doc
{
"test":"test"
}
POST test.2023.12.06/_doc
{
"test":"test"
}
POST test.2023.12.6/_doc
{
"test":"test"
}
POST test20231206/_doc
{
"test":"test"
}
POST test/_doc
{
"test":"test"
}
查询测试语句
#预计成功的查询
curl localhost:8000/test-2023-12-06/_search?pretty
curl localhost:8000/test-2023-12-6/_search?pretty
curl localhost:8000/test.2023.12.06/_search?pretty
curl localhost:8000/test.2023.12.6/_search?pretty
curl localhost:8000/test20231206/_search?pretty
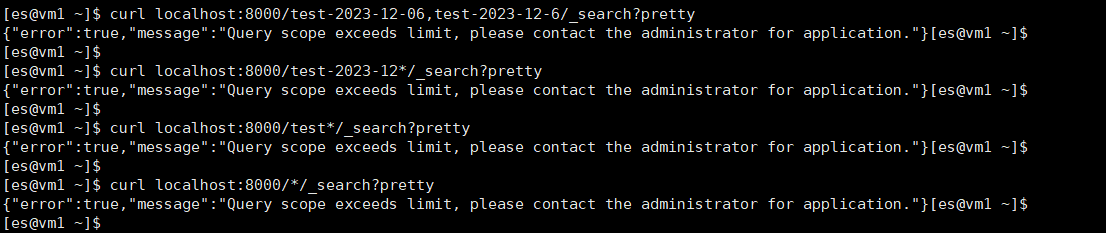
#预计失败的查询
curl localhost:8000/test-2023-12-06,test-2023-12-6/_search?pretty
curl localhost:8000/test-2023-12*/_search?pretty
curl localhost:8000/test*/_search?pretty
curl localhost:8000/*/_search?pretty
查询结果
预计成功的查询

预计失败的查询
此外,我们在 Console 中的 Request Analysis 看板中也能看到,哪些请求被拒绝,哪些请求被“放行”。

查询多个索引(多天)
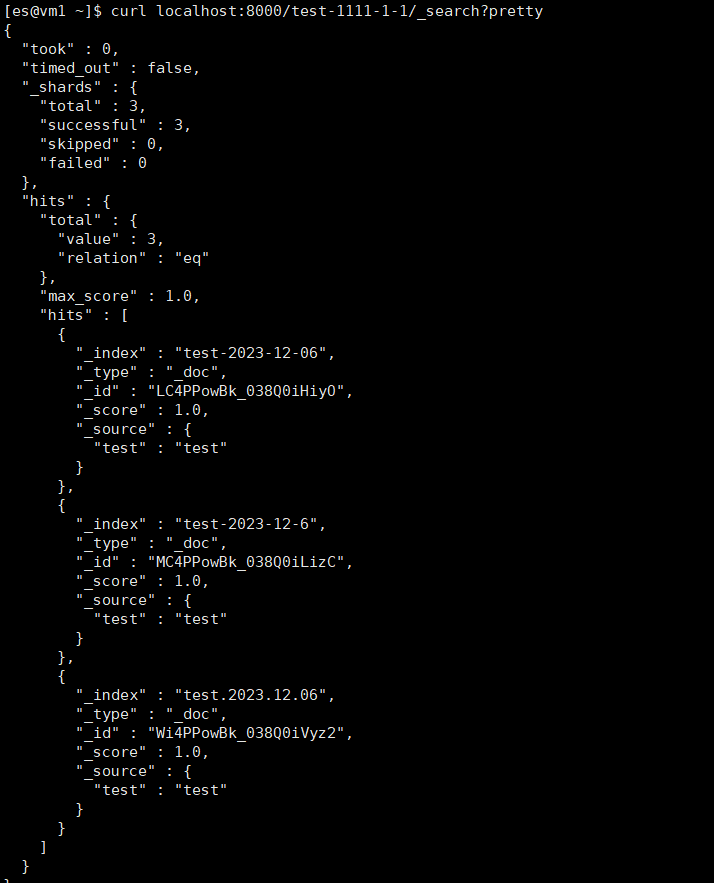
现在我们已经实现了业务只能查一个索引,即一天的数据。当业务需要查询多天的索引时,我们只需创建一个别名,关联多个索引就行了。注意别名也要符合格式要求:字母开头 + 日期格式后缀。
下面我们创建一个 test-1111-1-1 的别名,关联前面的三个测试索引。
POST /_aliases
{
"actions" : [
{ "add" : { "indices" : ["test-2023-12-06", "test.2023.12.06","test-2023-12-6"], "alias" : "test-1111-1-1" } }
]
}
查询别名
待业务查询用完之后,删除别名即可。
POST /_aliases
{
"actions" : [
{ "remove": { "indices" : ["test-2023-12-06", "test.2023.12.06","test-2023-12-6"], "alias" : "test-1111-1-1" } }
]
}
最后,我们只需严格控制别名的创建,就能实现我们最初的需求了。
INFINI Gateway 如何防止大跨度查询的更多相关文章
- Elasticsearch Span Query跨度查询
ES基于Lucene开发,因此也继承了Lucene的一些多样化的查询,比如本篇说的Span Query跨度查询,就是基于Lucene中的SpanTermQuery以及其他的Query封装出的DSL,接 ...
- Facebook 正式开源其大数据查询引擎 Presto
Facebook 正式宣布开源 Presto —— 数据查询引擎,可对250PB以上的数据进行快速地交互式分析.该项目始于 2012 年秋季开始开发,目前该项目已经在超过 1000 名 Faceboo ...
- 利用SQL Profiler处理开销较大的查询
当SQL Server的性能变差时,最可能发生的是以下两件事: 首先,某些查询产生了系统资源上很大的压力.这些查询影响整个系统的性能,因为服务器无法足够快速地服务其他SQL查询. 另外,开销较大的查询 ...
- lucene-SpanQuery跨度查询基础
1.跨度查询SpanQuery5个子类 SpanQuery类型 描述 SpanTermQuery 和其他跨度查询结合 ...
- lucene-SpanFirstQuery 和SpanNearQuery 跨度查询
1.SpanFirstQuery查询 对出现在一个域中前n个位置的跨度查询. public void testSpanFirstQuery() throws Exception{ SpanzFirts ...
- SQL命令语句进行大数据查询如何进行优化
SQL 大数据查询如何进行优化? 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索 2.应尽量避免在 where 子句中对字段进行 null 值 ...
- mysql 5.7 innodb count count(*) count(1) 大数据 查询慢 耗时多 优化
原文:mysql 5.7 innodb count count(*) count(1) 大数据 查询慢 耗时多 优化 问题描述 mysql 5.7 innodb 引擎 使用以下几种方法进行统计效率差不 ...
- 比hive快10倍的大数据查询利器presto部署
目前最流行的大数据查询引擎非hive莫属,它是基于MR的类SQL查询工具,会把输入的查询SQL解释为MapReduce,能极大的降低使用大数据查询的门槛, 让一般的业务人员也可以直接对大数据进行查询. ...
- MySQL 如何优化大分页查询?
一 背景 大部分开发和DBA同行都对分页查询非常非常了解,看帖子翻页需要分页查询,搜索商品也需要分页查询.那么问题来了,遇到上千万或者上亿的数据量怎么快速的拉取全量,比如大商家拉取每月千万级别的订单数 ...
- 015-elasticsearch5.4.3【五】-搜索API【四】Joining 多文档查询、GEO查询、moreLikeThisQuery、script脚本查询、span跨度查询
一.Joining 多文档查询 joining query 像Elasticsearch这样的分布式系统中执行完整的SQL样式连接非常昂贵.相反,Elasticsearch提供两种形式的连接,旨在水平 ...
随机推荐
- 力扣598(java)-范围求和Ⅱ(简单)
题目: 给你一个 m x n 的矩阵 M ,初始化时所有的 0 和一个操作数组 op ,其中 ops[i] = [ai, bi] 意味着当所有的 0 <= x < ai 和 0 <= ...
- 力扣524(java)-通过删除字母匹配到字典里最长单词(中等)
题目: 给你一个字符串 s 和一个字符串数组 dictionary ,找出并返回 dictionary 中最长的字符串,该字符串可以通过删除 s 中的某些字符得到. 如果答案不止一个,返回长度最长且字 ...
- 【pytorch学习】之自动微分
5 自动微分 求导是几乎所有深度学习优化算法的关键步骤.虽然求导的计算很简单,只需要一些基本的微积分.但对于复杂的模型,手工进行更新是一件很痛苦的事情(而且经常容易出错).深度学习框架通过自动计算导数 ...
- Understand Abstraction and Interface
Foreword 抽象和接口是Java中的两个关键字,也是两种最基本的优化软件项目手段.为什么说它们是一种优化项目的手段? 人分三六九等,不同等级的人,所接触的事和处理的事是不一样的.同理,项目也分大 ...
- MaxCompute管家详解--管家助力,轻松玩转MaxCompute
精彩视频回顾请点击:MaxCompute管家详解以下是直播内容精华整理,主要包括以下四个方面:1.背景速览:2.功能介绍:3.案例讲解:4.新功能预告. 一.背景速览 MaxCompute(原ODPS ...
- [FAQ] pdf 无法导入 adobe AI, 分辨率 or 颜色缺失 or 字体缺失
属于Adoge软件不支持问题, 可能是分辨率.字体等多种原因. https://www.codebye.com/adobe-reader-or-acrobat-opens-pdf-file-drawi ...
- 网站访问速度优化实战:CDN源/Nginx压缩/全站CDN加速
前言 接触到CDN的起因: 我自己搭建的网站https://price.monitor4all.cn/网页打开的速度一直比较慢,经查证是我的网站有很多静态js大文件,通过浏览器读取这些js比较耗时间. ...
- three.js教程1-快速入门
1.项目开发环境引入threeJs 如果采用的是Vue + threejs或React + threejs技术栈,threejs就是一个js库,直接通过npm命令行安装就行. npm安装特定版本thr ...
- JavaScript中对数组.map()、some()、every()、filter()、forEach的区别
1.区别说明 共同点: 不会对原数组发生修改,而是返回新的变量,用变量接收. 不同点: 1.some():返回一个Boolean类型变量,判断是否有元素符合func条件 2.every():返回一个B ...
- 从零在win10上测试whisper、faster-whisper、whisperx在CPU和GPU的各自表现情况
Anaconda是什么? Anaconda 是一个开源的 Python 发行版本,主要面向数据科学.机器学习和数据分析等领域.它不仅包含了 Python 解释器本身,更重要的是集成了大量的用于科学计算 ...