1. 常用的一些系统性能排查linux命令
目录
- 一、CPU
- 1.1 top命令--CPU性能
- 1.2 负载 —— CPU 任务排队情况
- 1.3 vmstat —— CPU 繁忙程度
- 二、内存
- 2.1 top命令
- 三、IO
- 3.1 iostat
- 3.2 零拷贝
当系统存在短板时,就会对性能造成较大的负面影响,比如当 CPU 的负载特别高时,任务就会排队,不能及时执行。而其中,CPU、内存、I/O 这三个系统组件,又往往容易成为瓶颈,所以接下来我会对这三方面分别进行讲解。
一、CPU
首先介绍计算机中最重要的计算组件中央处理器 CPU,围绕 CPU 一般我们可以:
通过 top 命令,来观测 CPU 的性能;
通过负载,评估 CPU 任务执行的排队情况;
通过 vmstat,看 CPU 的繁忙程度。
1.1 top命令--CPU性能
如下图,当进入 top 命令后,按 1 键即可看到每核 CPU 的运行指标和详细性能。
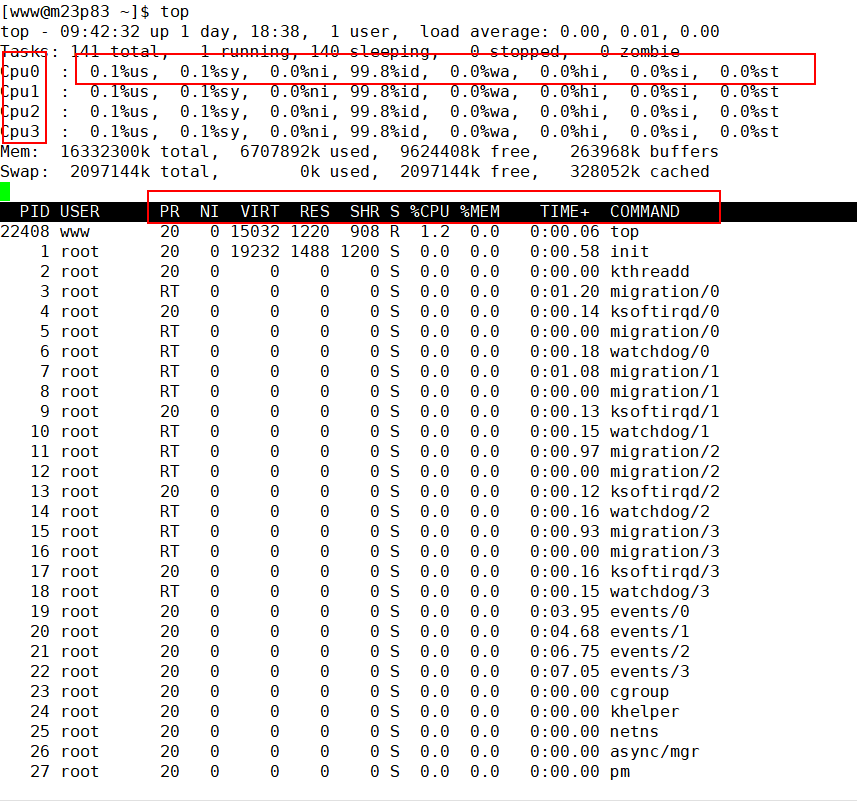
CPU 的使用有多个维度的指标,下面分别说明:
us 用户态所占用的 CPU 百分比,即引用程序所耗费的 CPU;
sy 内核态所占用的 CPU 百分比,需要配合 vmstat 命令,查看上下文切换是否频繁;
ni 高优先级应用所占用的 CPU 百分比;
wa 等待 I/O 设备所占用的 CPU 百分比,经常使用它来判断 I/O 问题,过高输入输出设备可能存在非常明显的瓶颈;
hi 硬中断所占用的 CPU 百分比;
si 软中断所占用的 CPU 百分比;
st 在平常的服务器上这个值很少发生变动,因为它测量的是宿主机对虚拟机的影响,即虚拟机等待宿主机 CPU 的时间占比,这在一些超卖的云服务器上,经常发生;
id 空闲 CPU 百分比。
一般地,我们比较关注空闲 CPU 的百分比,它可以从整体上体现 CPU 的利用情况。
那 load 为 1 代表的是啥?针对这个问题,误解还是比较多的。
1.2 负载 —— CPU 任务排队情况
如果我们评估 CPU 任务执行的排队情况,那么需要通过负载(load)来完成。除了 top 命令,使用 uptime 命令也能够查看负载情况,load 的效果是一样的,分别显示了最近 1min、5min、15min 的数值。

很多人看到 load 的值达到 1,就认为系统负载已经到了极限。这在单核的硬件上没有问题,但在多核硬件上,这种描述就不完全正确,它还与 CPU 的个数有关。例如: 单核的负载达到 1,总 load 的值约为 1; 双核的每核负载都达到 1,总 load 约为 2; 四核的每核负载都达到 1,总 load 约为 4。 所以,对于一个 load 到了 10,却是 16 核的机器,你的系统还远没有达到负载极限。
1.3 vmstat —— CPU 繁忙程度
要看 CPU 的繁忙程度,可以通过 vmstat 命令,下图是 vmstat 命令的一些输出信息。

比较关注的有下面几列: b 如果系统有负载问题,就可以看一下 b 列(Uninterruptible Sleep),它的意思是等待 I/O,可能是读盘或者写盘动作比较多; si/so 显示了交换分区的一些使用情况,交换分区对性能的影响比较大,需要格外关注; cs 每秒钟上下文切换(Context Switch)的数量,如果上下文切换过于频繁,就需要考虑是否是进程或者线程数开的过多。 每个进程上下文切换的具体数量,可以通过查看内存映射文件获取,如下代码所示(voluntary_ctxt_switchesh和nonvoluntary_ctxt_switches):
[www@m23p83 ~]$ cat /proc/1306/sta
stack stat statm status
[www@m23p83 ~]$ cat /proc/1306/status
Name: java
State: S (sleeping)
Tgid: 1306
Pid: 1306
PPid: 1
TracerPid: 0
Uid: 507 507 507 507
Gid: 507 507 507 507
Utrace: 0
FDSize: 256
Groups: 507
VmPeak: 5814736 kB
VmSize: 5812064 kB
VmLck: 0 kB
VmHWM: 1699552 kB
VmRSS: 1698872 kB
VmData: 5661480 kB
VmStk: 88 kB
VmExe: 4 kB
VmLib: 16464 kB
VmPTE: 3732 kB
VmSwap: 0 kB
Threads: 75
SigQ: 0/127436
SigPnd: 0000000000000000
ShdPnd: 0000000000000000
SigBlk: 0000000000000000
SigIgn: 0000000000000002
SigCgt: 2000000181005ccd
CapInh: 0000000000000000
CapPrm: 0000000000000000
CapEff: 0000000000000000
CapBnd: ffffffffffffffff
Cpus_allowed: f
Cpus_allowed_list: 0-3
Mems_allowed: 00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000001
Mems_allowed_list: 0
voluntary_ctxt_switches: 87
nonvoluntary_ctxt_switches: 4
二、内存
逻辑地址可以映射到两个内存段上:物理内存和虚拟内存,那么整个系统可用的内存就是两者之和。比如你的物理内存是 4GB,分配了 8GB 的 SWAP 分区,那么应用可用的总内存就是 12GB。
2.1 top命令
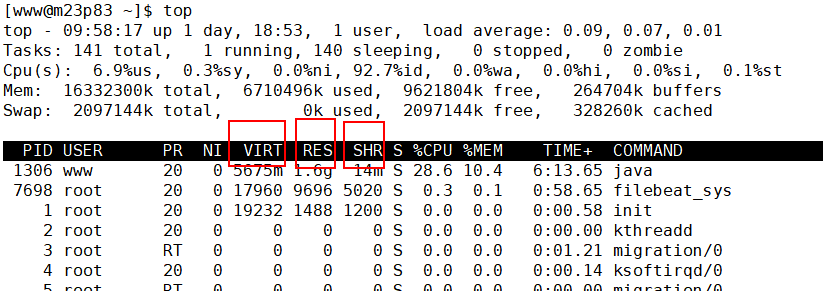
VIRT(virtual memory usage) 这里是指虚拟内存,一般比较大,不用做过多关注;
RES(resident memory usage) 我们平常关注的是这一列的数值,它代表了进程实际占用的内存,平常在做监控时,主要监控的也是这个数值;
SHR(shared memory) 指的是共享内存,比如可以复用的一些 so 文件等。
top命令打开后,按f键如下所示,按Enter退出:
Current Fields: AEHIOQTWKNMbcdfgjplrsuvyzX for window 1:Def
Toggle fields via field letter, type any other key to return
* A: PID = Process Id 0x00100000 PF_USEDFPU (thru 2.4)
* E: USER = User Name
* H: PR = Priority
* I: NI = Nice value
* O: VIRT = Virtual Image (kb)
* Q: RES = Resident size (kb)
* T: SHR = Shared Mem size (kb)
* W: S = Process Status
* K: %CPU = CPU usage
* N: %MEM = Memory usage (RES)
* M: TIME+ = CPU Time, hundredths
b: PPID = Parent Process Pid
c: RUSER = Real user name
d: UID = User Id
f: GROUP = Group Name
g: TTY = Controlling Tty
j: P = Last used cpu (SMP)
p: SWAP = Swapped size (kb)
l: TIME = CPU Time
r: CODE = Code size (kb)
s: DATA = Data+Stack size (kb)
u: nFLT = Page Fault count
v: nDRT = Dirty Pages count
y: WCHAN = Sleeping in Function
z: Flags = Task Flags <sched.h>
* X: COMMAND = Command name/line
Flags field:
0x00000001 PF_ALIGNWARN
0x00000002 PF_STARTING
0x00000004 PF_EXITING
0x00000040 PF_FORKNOEXEC
0x00000100 PF_SUPERPRIV
0x00000200 PF_DUMPCORE
0x00000400 PF_SIGNALED
0x00000800 PF_MEMALLOC
0x00002000 PF_FREE_PAGES (2.5)
0x00008000 debug flag (2.5)
0x00024000 special threads (2.5)
0x001D0000 special states (2.5)
默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。可以通过下面的快捷键来更改显示内容。
通过 f 键可以选择显示的内容。按 f 键之后会显示列的列表,按 a-z 即可显示或隐藏对应的列,最后按回车键确定。
按 o 键可以改变列的显示顺序。按小写的 a-z 可以将相应的列向右移动,而大写的 A-Z 可以将相应的列向左移动。最后按回车键确定。
按大写的 F 或 O 键,然后按 a-z 可以将进程按照相应的列进行排序。而大写的 R 键可以将当前的排序倒转。
top 运行中可以通过 top 的内部命令对进程的显示方式进行控制。内部命令如下: s – 改变画面更新频率 l – 关闭或开启第一部分第一行 top 信息的表示 t – 关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示 m – 关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示 N – 以 PID 的大小的顺序排列表示进程列表 P – 以 CPU 占用率大小的顺序排列进程列表 M – 以内存占用率大小的顺序排列进程列表 h – 显示帮助 n – 设置在进程列表所显示进程的数量 q – 退出 top s – 改变画面更新周期
三、IO
I/O 设备可能是计算机里速度最慢的组件了,它指的不仅仅是硬盘,还包括外围的所有设备。那硬盘有多慢呢?我们不去探究不同设备的实现细节,直接看它的写入速度(数据未经过严格测试,来自网络,仅作参考,在此只为了说明问题)。

如上图所示,可以看到普通磁盘的随机写与顺序写相差非常大,但顺序写与 CPU 内存依旧不在一个数量级上。
缓冲区依然是解决速度差异的唯一工具,但在极端情况下,比如断电时,就产生了太多的不确定性,这时这些缓冲区,都容易丢。
3.1 iostat
最能体现 I/O 繁忙程度的,就是 top 命令和 vmstat 命令中的 wa%。如果你的应用写了大量的日志,I/O wait 就可能非常高。

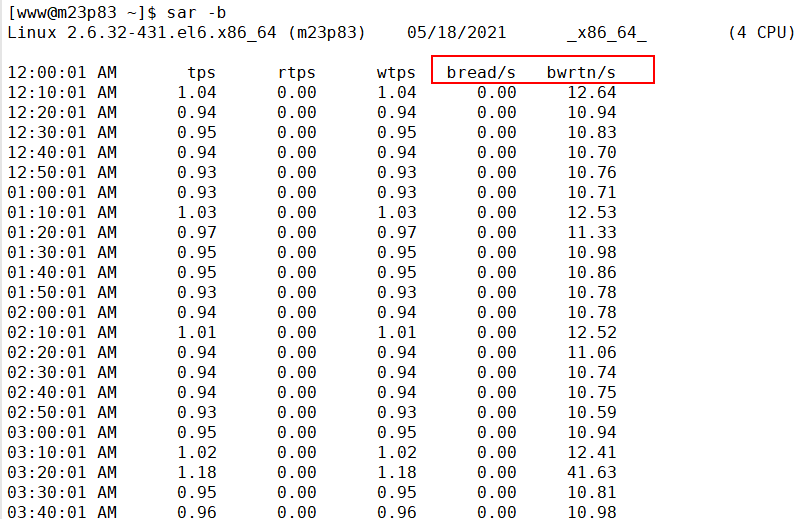
查看磁盘 I/O 的工具(iostat), 如下所示:
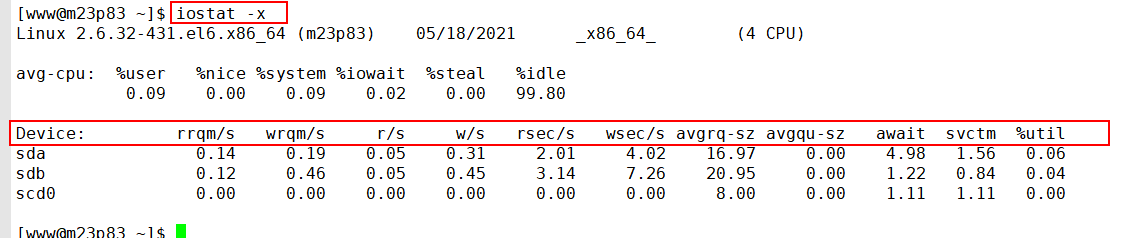
图中的指标详细介绍如下所示。 %util:我们非常关注这个数值,通常情况下,这个数字超过 80%,就证明 I/O 的负荷已经非常严重了。 Device:表示是哪块硬盘,如果你有多块磁盘,则会显示多行。 avgqu-sz:平均请求队列的长度,这和十字路口排队的汽车也非常类似。显然,这个值越小越好。 awai:响应时间包含了队列时间和服务时间,它有一个经验值。通常情况下应该是小于 5ms 的,如果这个值超过了 10ms,则证明等待的时间过长了。 svctm:表示操作 I/O 的平均服务时间,这里就是 AVG 的意思。svctm 和 await 是强相关的,如果它们比较接近,则表示 I/O 几乎没有等待,设备的性能很好;但如果 await 比 svctm 的值高出很多,则证明 I/O 的队列等待时间太长,进而系统上运行的应用程序将变慢。
3.2 零拷贝
硬盘上的数据,在发往网络之前,需要经过多次缓冲区的拷贝,以及用户空间和内核空间的多次切换。如果能减少一些拷贝的过程,效率就能提升,所以零拷贝应运而生。 零拷贝是一种非常重要的性能优化手段,比如常见的 Kafka、Nginx 等,就使用了这种技术。我们来看一下有无零拷贝之间的区别。 (1)没有采取零拷贝手段 如下图所示,传统方式中要想将一个文件的内容通过 Socket 发送出去,则需要经过以下步骤: 将文件内容拷贝到内核空间; 将内核空间内存的内容,拷贝到用户空间内存,比如 Java 应用读取 zip 文件; 用户空间将内容写入到内核空间的缓存中; Socket 读取内核缓存中的内容,发送出去。

(2)采取了零拷贝手段 零拷贝有多种模式,我们用 sendfile 来举例。如下图所示,在内核的支持下,零拷贝少了一个步骤,那就 是内核缓存向用户空间的拷贝,这样既节省了内存,也节省了 CPU 的调度时间,让效率更高。

1. 常用的一些系统性能排查linux命令的更多相关文章
- 故障排查-linux命令测试端口连通性
方法一:telnet法 预置条件:安装telnet step 1.rpm -qa telnet-server(无输出表示telnet-server未安装,则执行step2:否则执行step3) ste ...
- linux常用查看系统操作的linux命令
系统# uname -a # 查看内核/操作系统/CPU信息# head -n 1 /etc/issue # 查看操作系统版本# cat /proc/cpuinfo # 查看CPU信息# hostna ...
- 学习linux命令,看这篇2w多字的linux命令详解
用心分享,共同成长 没有什么比每天进步一点点更重要了 本文已收录到我的github:https://github.com/midou-tech/articles/tree/master/docs/li ...
- 实用的linux 命令(上)
今天介绍几个我常用的Linux 命令,每个命令这里只介绍其常用参数. 对于每个Linux 命令都可以使用man + 命令名称,查看其完整使用方法. 0,man man 命令是一个非常有用的命令,当你不 ...
- Linux命令排查线上问题常用的几个
排查线上问题常用的几个Linux命令 https://www.cnblogs.com/cjsblog/p/9562380.html top 相当于Windows任务管理器 可以看到,输出结果分两部分, ...
- Linux系统性能10条命令监控
Linux系统性能10条命令监控 概述 通过执行以下命令,可以在1分钟内对系统资源使用情况有个大致的了解. uptime dmesg | tail vmstat 1 mpstat -P ALL 1 p ...
- 排查问题所用到的一些Linux命令实践(不定期更新。。)
一.前言 线上问题排查可能是每个程序员都会经历的.在排查的过程中,往往会用到很多Linux命令,也会产生一些很实用的技巧.本博文通过分析一次线上问题排查的过程,把所有用到的命令串起来.每个Linux命 ...
- 工作中常用的 Linux 命令
awk 示例: env变量值如下,需要获得pkg_url的链接值: {"name": "michael", "sex": "mal ...
- 我常用的一些linux命令
之前做过两年的运维,用过很多命令,深切体会到某些linux命令熟练掌握后对效率提升有多大.举个简单的例子,在做了研发后经常会有跑一些数据,对于结果数据的处理,我们的产品同学一般都习惯于用excel做统 ...
- Linux性能分析——分析系统性能相关的命令
Linux性能分析——分析系统性能相关的命令 摘要:本文主要学习了Linux系统中分析性能相关的命令. ps命令 ps命令用来显示系统中进程的运行情况,显示的是当前系统的快照. 基本语法 ps [选项 ...
随机推荐
- bash shell笔记整理——cd命令、目录路径
cd---change directory 改变目录的意思 语法: cd [选项] <目录> 选项: -L 会自动进入符号连接目录(默认) -P 进入符号连接目录的真实目录下. 常用: 命 ...
- 传统GIS与数字孪生结合带来的改变
传统的地理信息系统(GIS)在地理数据的收集.存储和分析方面发挥着重要作用,而数字孪生技术则通过虚拟模型的构建与真实世界进行交互和模拟.将传统GIS与数字孪生技术相结合,不仅增强了地理数据的可视化和分 ...
- 数字孪生与GIS的结合:创新灾害预防管理的未来
近年来,全球频发的自然灾害给人们的生命和财产安全带来了巨大威胁,灾害预防管理成为当务之急.然而,随着数字孪生技术和GIS的迅猛发展,一种全新的解决方案正在崭露头角.数字孪生与GIS的结合,为灾害预防管 ...
- 递归产生StackOverflowError
package com.guoba.digui; public class Demo01 { public void A(){ A();//自己调用自己,递归没用好,产生错误java.lang.Sta ...
- Config:Spring Cloud分布式配置组件
Config:Spring Cloud分布式配置组件 问题总结 Config? Config工作原理? Config 的特点? Config+Bus 实现配置的动态刷新? 问题答案 Config Co ...
- JVM优化:如何进行JVM调优,JVM调优参数有哪些
Java虚拟机(JVM)是Java应用运行的核心环境.JVM的性能优化对于提高应用性能.减少资源消耗和提升系统稳定性至关重要.本文将深入探讨JVM的调优方法和相关参数,以帮助开发者和系统管理员有效地优 ...
- 华为云GaussDB坚持技术引领,以数字化转型激活金融科技新动能
摘要:"银行业数字化转型实践交流会"杭州站顺利收官. 由华为与北京先进数通联合主办的"银行业数字化转型实践交流会"杭州站顺利收官,会议邀请了金融科技先锋企业.机 ...
- Volcano 监控设计解读,一看就懂
摘要:Volcano 方便AI,大数据,基因,渲染等诸多行业通用计算框架介入,提供高性能任务调度引擎,高性能异构芯片管理,高性能任务运行管理等能力. Volcano 是一个 Kubernetes 云原 ...
- 云小课 | SA基线检查—给云服务的一次全面“体检”
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要: 华为云态势感知( ...
- Chrome浏览器导出HTTPS证书
点证书小锁 进入证书界面 到详情中,导出证书