梳理Langchain-Chatchat知识库API接口
一.Langchain-Chatchat 知识库管理
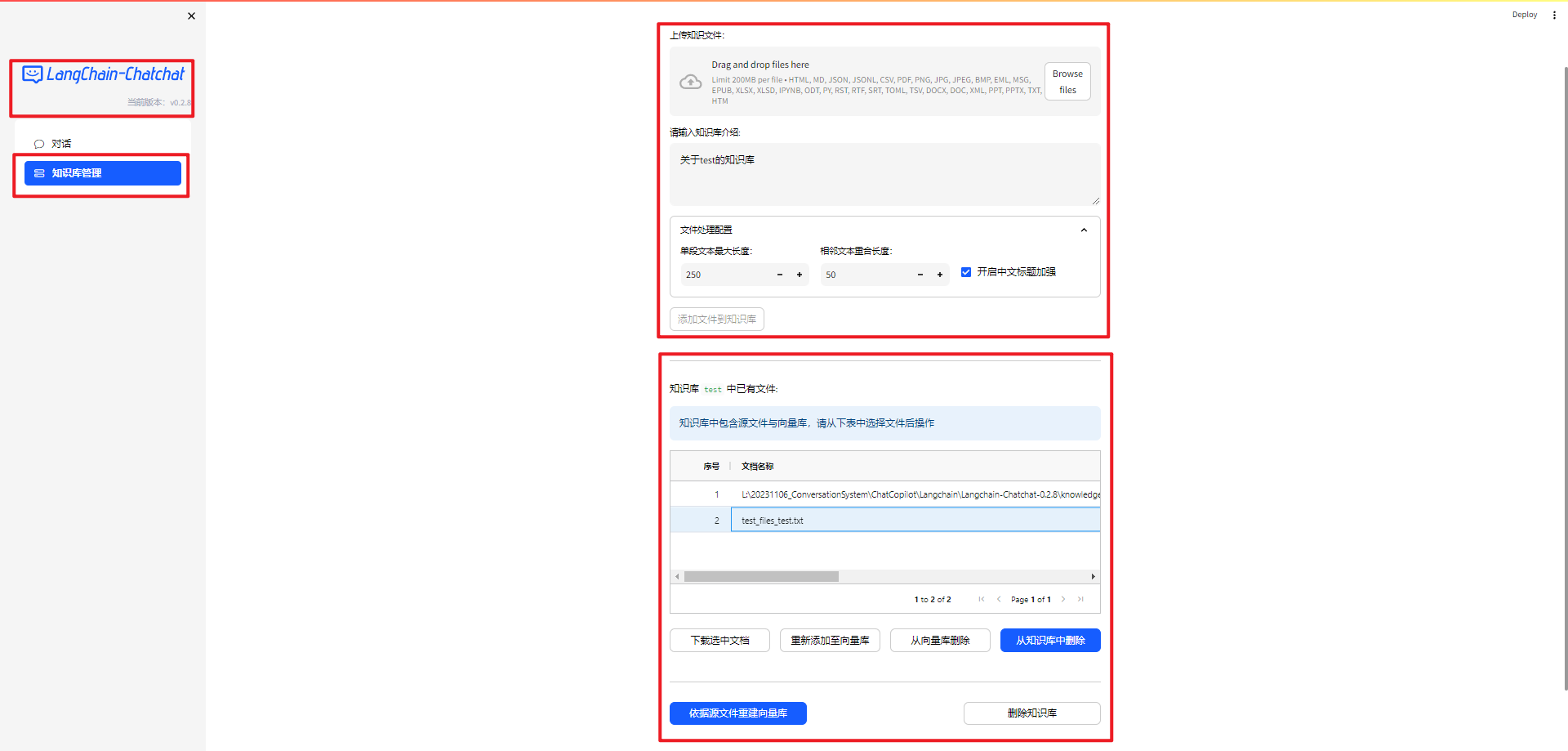
1.Langchain-Chatchat 对话和知识库管理界面
Langchain-Chatchat v0.28 完整的界面截图,如下所示:
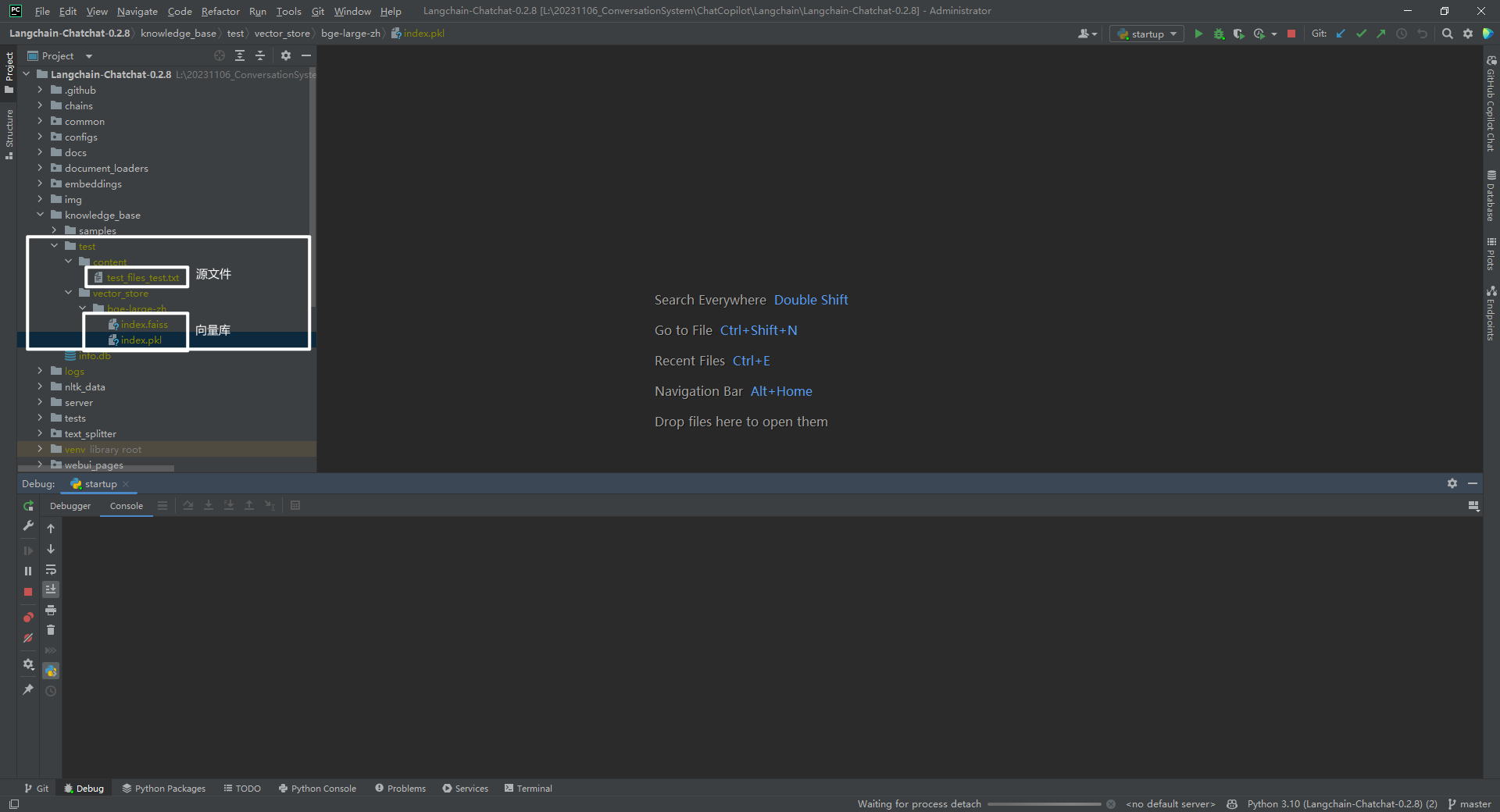
2.知识库中源文件和向量库
知识库 test 中源文件和向量库的位置,如下所示:
3.知识库表结构
knowledge_base 数据表内容,如下所示:

二.知识库操作 1

| 序号 | 操作名字 | 功能解释 | 链接 | 备注 |
|---|---|---|---|---|
| 1 | 获取知识库列表 | 就是上面的 samples(faiss @ bge-large-zh)和 test (faiss @ bge-large-zh)。 | http://127.0.0.1/knowledge_base/list_knowledge_bases | - |
| 2 | 选择知识库 | 选中一个知识库 | 没有对应 API 接口 | - |
| 3 | 新建知识库 | 新建一个知识库 | http://127.0.0.1/knowledge_base/create_knowledge_base,如下所示:{ "knowledge_base_name": "LLM", "vector_store_type": "faiss", "embed_model": "bge-large-zh"} |
创建知识库 |
| 4 | 上传知识文件 | 向知识库上传文件,比如限制每个文件 200MB,类型可为 HTML, MD, JSON, JSONL, CSV, PDF, PNG, JPG, JPEG, BMP, EML, MSG, EPUB, XLSX, XLSD, IPYNB, ODT, PY, RST, RTF, SRT, TOML, TSV, DOCX, DOC, XML, PPT, PPTX, TXT, HTM | 只是上传并显示了一个文件,并没有真的将文件上传到知识库中。 | - |
| 5 | 知识库介绍 | 知识库描述 | http://127.0.0.1/knowledge_base/update_info,如下所示:{ "knowledge_base_name": "samples", "kb_info": "这是一个知识库"} |
- |
| 6 | 单段文本最大长度 | 就是将长文本分割成多个较短的段落,每个段落的长度都不超过这个限制。 | 可通过更新现有文件到知识库接口 update_docs 实现。 | - |
| 7 | 相邻文本重合长度 | 将长文本分割成多个较短的段落时,相邻段落之间重复的文本的长度。这通常是为了确保 LLM 能够理解文本的上下文。 | 可通过更新现有文件到知识库接口 update_docs 实现。 | - |
| 8 | 开启中文标题加强 | 参考 kb_config.py 解释:1.是否开启中文标题加强,以及标题增强的相关配置;2.通过增加标题判断,判断哪些文本为标题,并在 metadata 中进行标记;3.然后将文本与往上一级的标题进行拼合,实现文本信息的增强。 | 可通过更新现有文件到知识库接口 update_docs 实现。 | - |
| 9 | 添加文件到知识库 | 将上传的文件添加到知识库中 | http://127.0.0.1/knowledge_base/upload_docs 说明:接口调用格式 POST -> Body -> form-data。 | - |
1.获取知识库列表
L:\20231106_ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\api.py,如下所示:
app.get("/knowledge_base/list_knowledge_bases",
tags=["Knowledge Base Management"],
response_model=ListResponse,
summary="获取知识库列表")(list_kbs)
L:\20231106_ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\knowledge_base\kb_api.py,如下所示:
def list_kbs():
# Get List of Knowledge Base
return ListResponse(data=list_kbs_from_db())
L:\20231106_ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\db\repository\knowledge_base_repository.py,如下所示:
@with_session
def list_kbs_from_db(session, min_file_count: int = -1):
# 根据文件数量筛选知识库,-1表示不筛选,返回所有知识库
kbs = session.query(KnowledgeBaseModel.kb_name).filter(KnowledgeBaseModel.file_count > min_file_count).all()
# 遍历结果,取出知识库名称
kbs = [kb[0] for kb in kbs]
return kbs
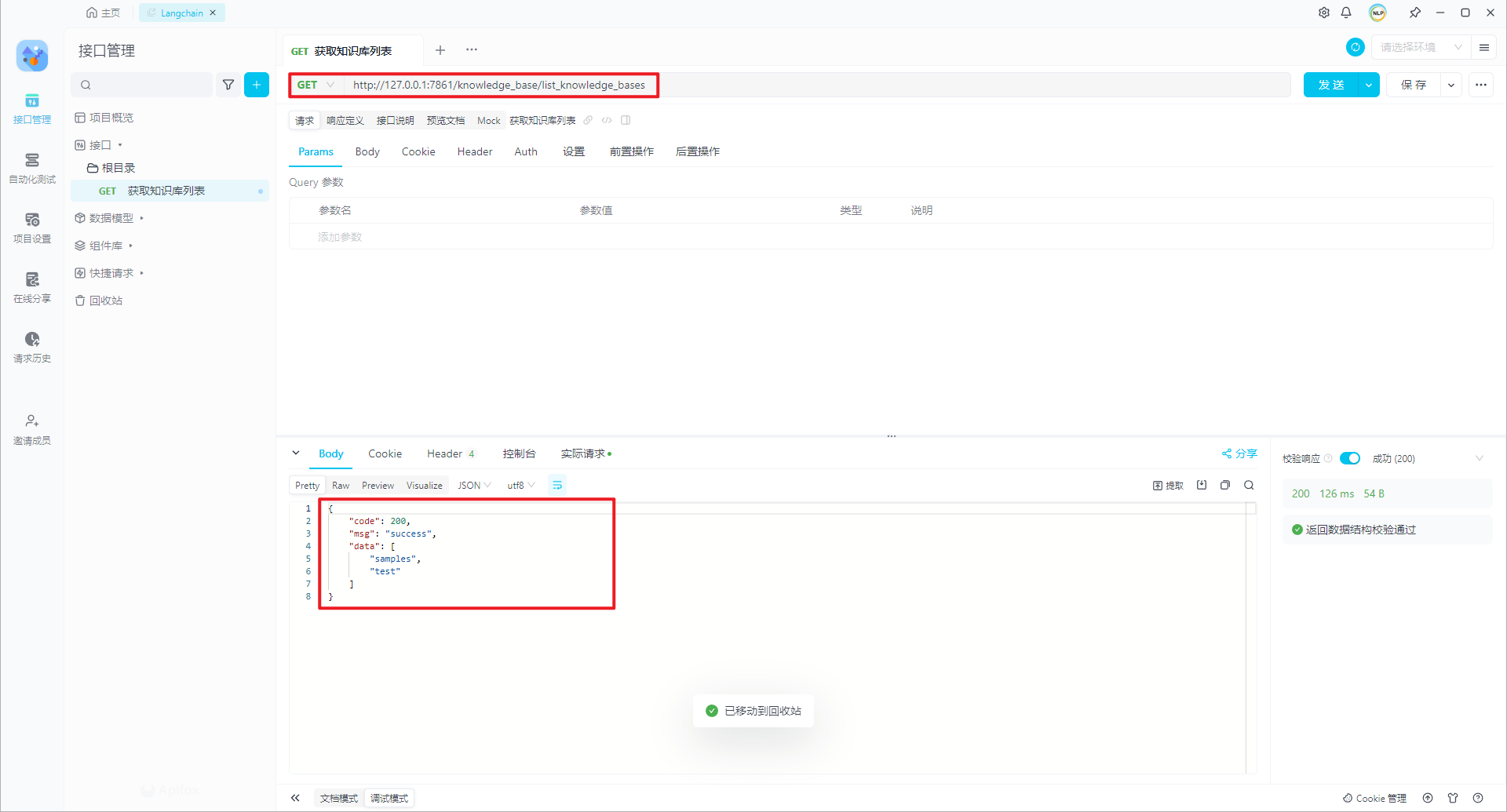
http://127.0.0.1/knowledge_base/list_knowledge_bases,返回结果:
{
"code": 200,
"msg": "success",
"data": [
"samples",
"test"
]
}
2.选中知识库
选中知识库并没有对应的接口,主要是选中知识库后,更新界面的(1)知识库介绍(2)知识库文档信息,包括源文件(遍历文件夹)和向量库(遍历数据库)。
(1)遍历文件夹
比如 test 知识库对应的 L:\20231106_ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\knowledge_base\test 文件夹。
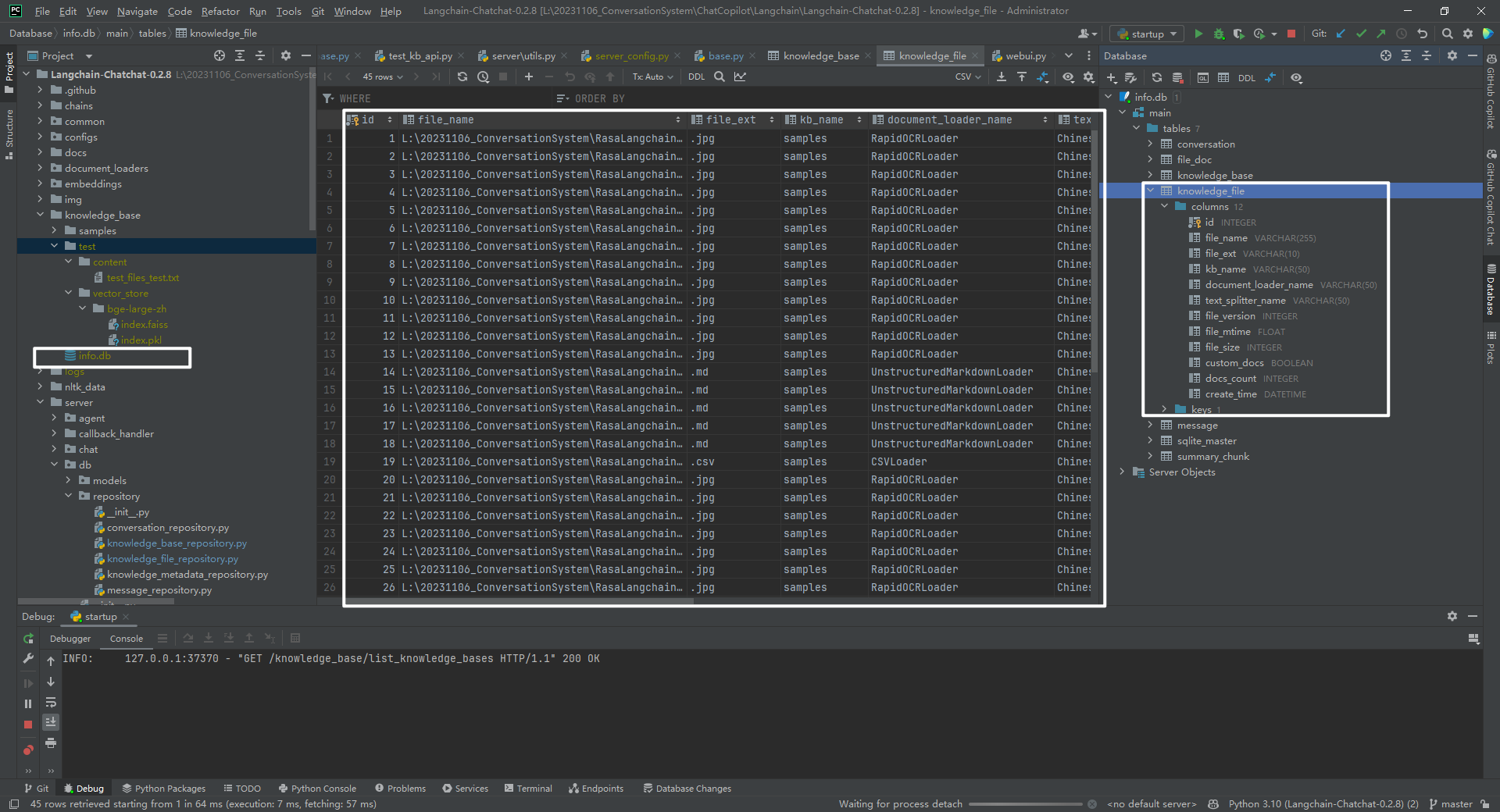
(2)遍历数据库
主要是 knowledge_file 数据表,包括 id、file_name、file_ext、kb_name、document_loader_name、text_splitter_name、file_version、file_mtime(文件修改时间)、file_size(单位)、custom_docs(自定义文档)、docs_count、create_time。
3.新建知识库
L:\20231106_ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\api.py,如下所示:
app.post("/knowledge_base/create_knowledge_base",
tags=["Knowledge Base Management"],
response_model=BaseResponse,
summary="创建知识库"
)(create_kb)
(1)拿到 FaissKBService 实例
L:\20231106_ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\knowledge_base\kb_api.py
def create_kb(knowledge_base_name: str = Body(..., examples=["samples"]),
vector_store_type: str = Body("faiss"),
embed_model: str = Body(EMBEDDING_MODEL),
) -> BaseResponse:
# Create selected knowledge base
if not validate_kb_name(knowledge_base_name): # 验证知识库名称
return BaseResponse(code=403, msg="Don't attack me")
if knowledge_base_name is None or knowledge_base_name.strip() == "": # 知识库名称不能为空
return BaseResponse(code=404, msg="知识库名称不能为空,请重新填写知识库名称")
kb = KBServiceFactory.get_service_by_name(knowledge_base_name) # 验证知识库是否存在
if kb is not None: # 已存在同名知识库
return BaseResponse(code=404, msg=f"已存在同名知识库 {knowledge_base_name}") # 404
kb = KBServiceFactory.get_service(knowledge_base_name, vector_store_type, embed_model) # 返回FaissKBService实例
try:
kb.create_kb() # 创建知识库
except Exception as e:
msg = f"创建知识库出错: {e}"
logger.error(f'{e.__class__.__name__}: {msg}',
exc_info=e if log_verbose else None)
return BaseResponse(code=500, msg=msg)
return BaseResponse(code=200, msg=f"已新增知识库 {knowledge_base_name}")
(2)创建知识库
L:\20231106_ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\knowledge_base\kb_service\base.py,如下所示:
def create_kb(self):
<em>"""</em>
<em> 创建知识库</em>
<em> """</em>
<em> </em>if not os.path.exists(self.doc_path): # 如果文档路径不存在
os.makedirs(self.doc_path) # 创建文档路径
self.do_create_kb() # 创建知识库
status = add_kb_to_db(self.kb_name, self.kb_info, self.vs_type(), self.embed_model) # 添加知识库到数据库
return status # 返回状态
(3)添加知识库到数据库
L:\20231106_ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\db\repository\knowledge_base_repository.py,如下所示:
@with_session
def add_kb_to_db(session, kb_name, kb_info, vs_type, embed_model):
# 创建知识库实例
kb = session.query(KnowledgeBaseModel).filter_by(kb_name=kb_name).first() # 查询知识库是否存在
if not kb: # 如果不存在,创建新的知识库
kb = KnowledgeBaseModel(kb_name=kb_name, kb_info=kb_info, vs_type=vs_type, embed_model=embed_model) # 创建知识库实例
session.add(kb) # 添加到数据库knowledge_base表中
else: # update kb with new vs_type and embed_model
kb.kb_info = kb_info # 更新知识库介绍
kb.vs_type = vs_type # 更新向量存储类型
kb.embed_model = embed_model # 更新嵌入模型
return True
(4)接口调用
http://127.0.0.1/knowledge_base/create_knowledge_base,如下所示:
{
"knowledge_base_name": "LLM",
"vector_store_type": "faiss",
"embed_model": "bge-large-zh"
}
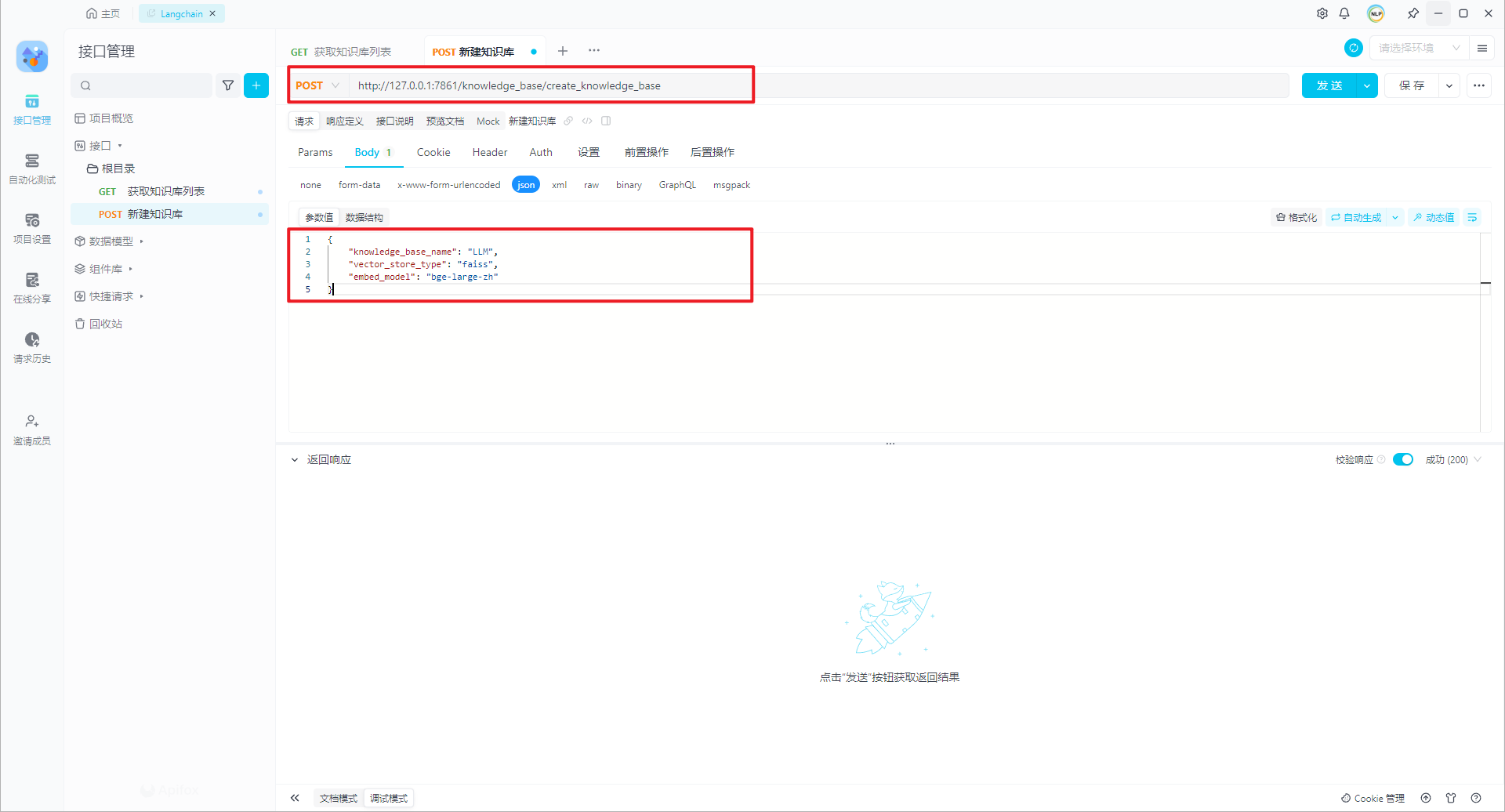
特别说明:没有找到知识库简介字段(确定没有)。参考更新知识库介绍/knowledge_base/update_info。
数据表 knowledge_base 信息,如下所示:
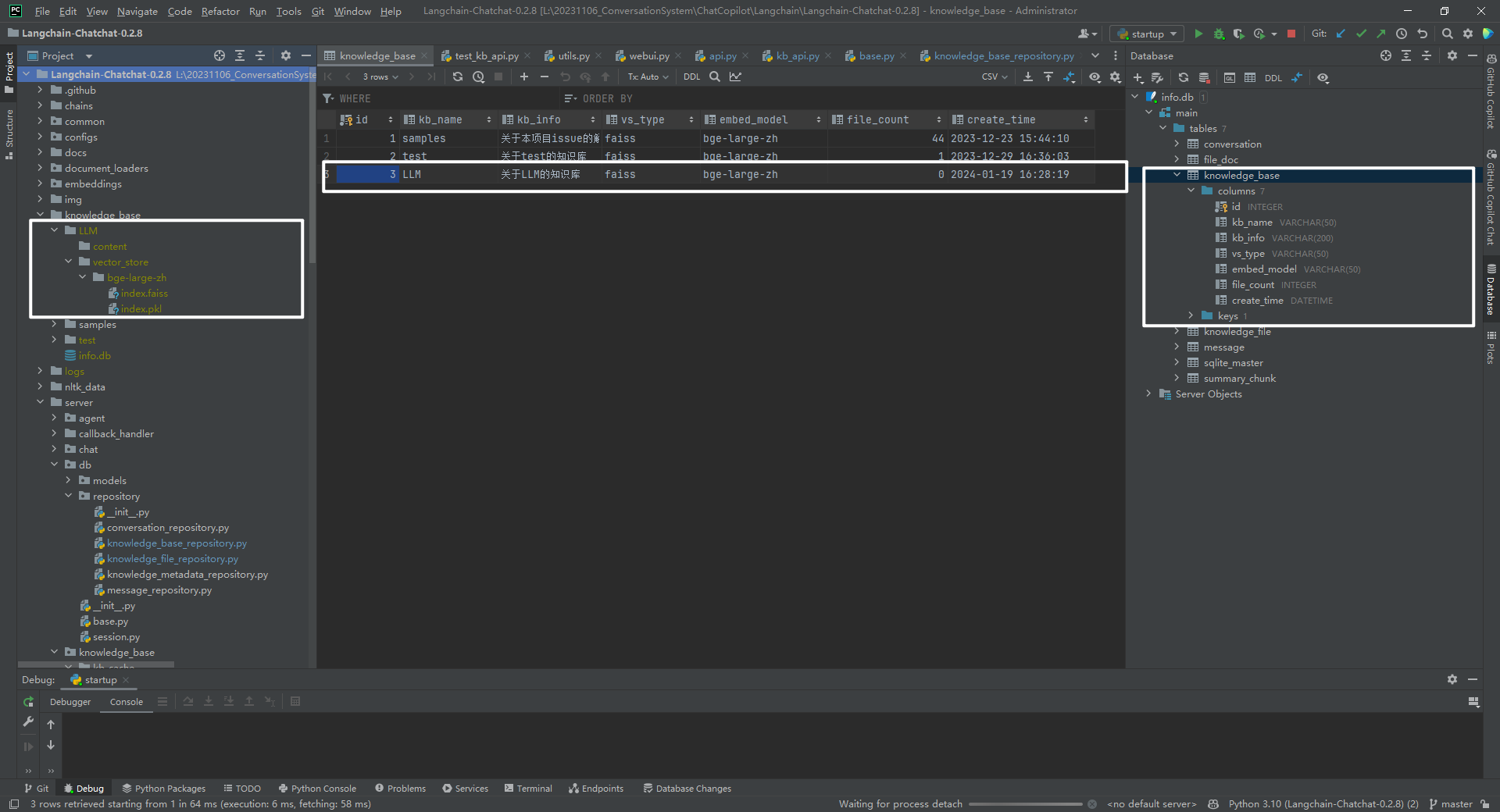
LangChain-Chatchat 知识库管理界面信息,如下所示:
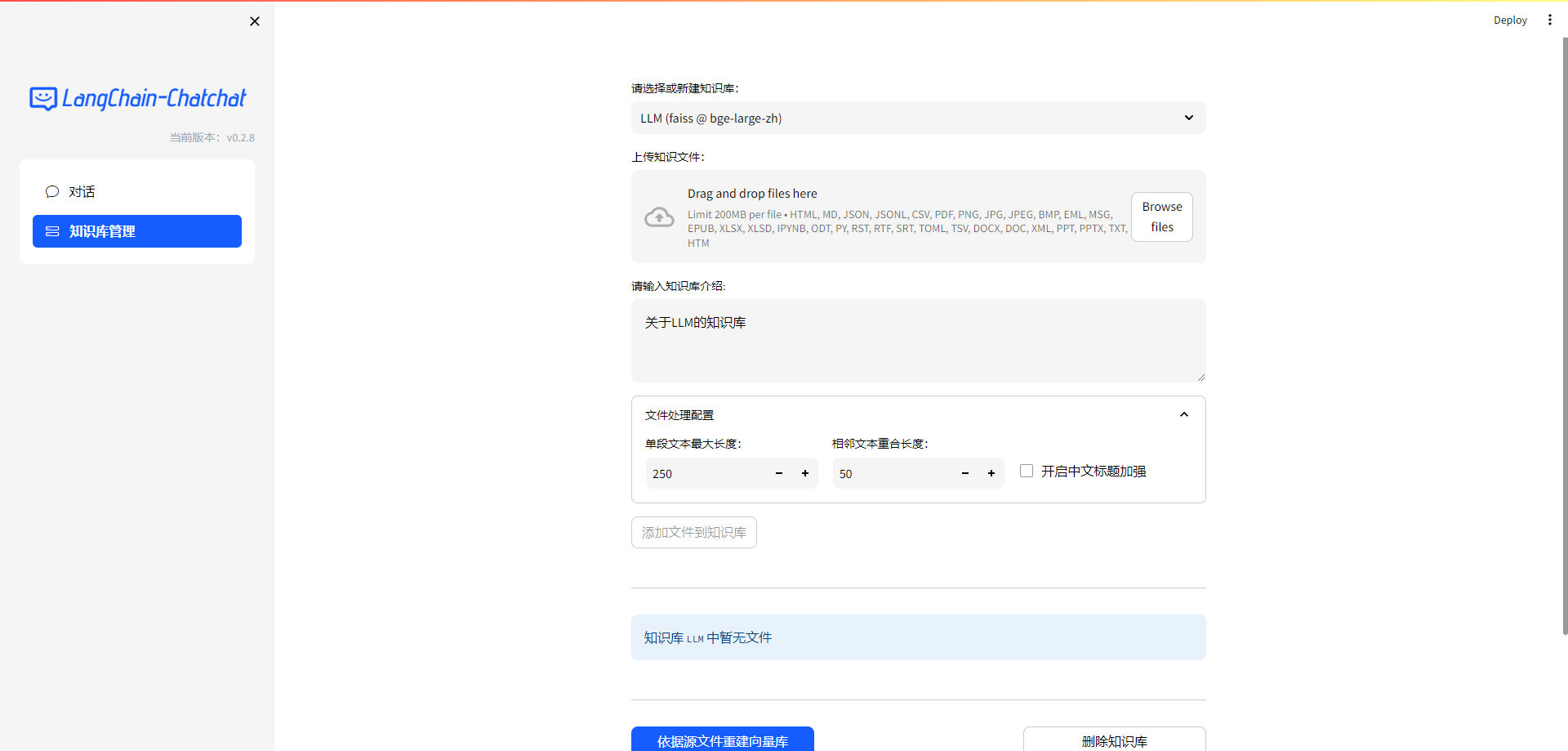
4.上传知识文件
st.file_uploader 创建一个文件上传组件,显示一个选择文件的按钮。如下所示:
files = st.file_uploader("上传知识文件:",
[i for ls in LOADER_DICT.values() for i in ls],
accept_multiple_files=True,
)
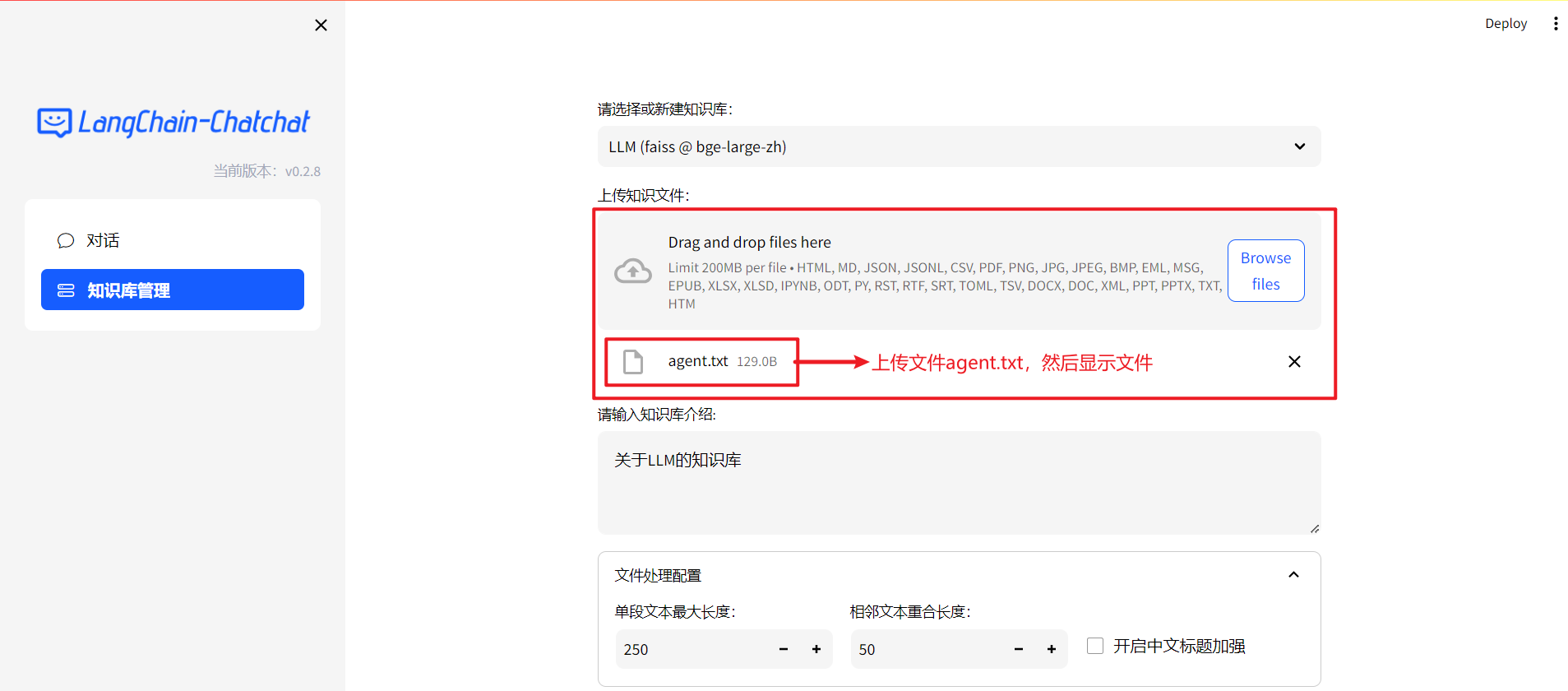
只是显示了一个文件,并没有真的将文件上传到知识库中。
5.知识库介绍
(1)知识库更新实现
F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\api.py,如下所示:
app.post("/knowledge_base/update_info",
tags=["Knowledge Base Management"],
response_model=BaseResponse,
summary="更新知识库介绍"
)(update_info)
对应的接口实现,如下所示:
def update_info(
knowledge_base_name: str = Body(..., description="知识库名称", examples=["samples"]),
kb_info: str = Body(..., description="知识库介绍", examples=["这是一个知识库"]),
):
if not validate_kb_name(knowledge_base_name):
return BaseResponse(code=403, msg="Don't attack me")
kb = KBServiceFactory.get_service_by_name(knowledge_base_name)
if kb is None:
return BaseResponse(code=404, msg=f"未找到知识库 {knowledge_base_name}")
kb.update_info(kb_info)
return BaseResponse(code=200, msg=f"知识库介绍修改完成", data={"kb_info": kb_info})
本质上还是更新数据库 knowledge_base,对知识库介绍字段进行更新。
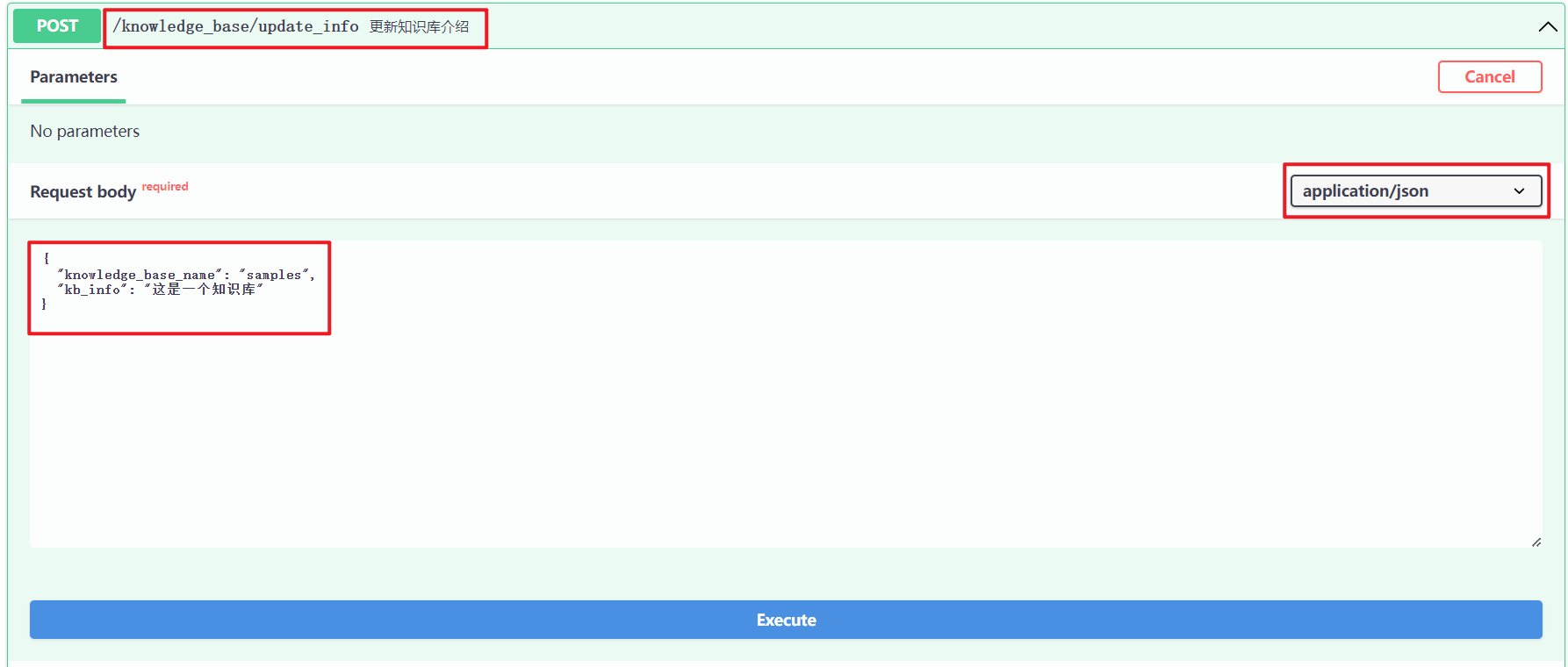
(2)接口调用
http://127.0.0.1/knowledge_base/update_info,如下所示:
6.单段文本最大长度
可通过更新现有文件到知识库接口 update_docs 实现。
7.相邻文本重合长度
可通过更新现有文件到知识库接口 update_docs 实现。
8.开启中文标题加强
可通过更新现有文件到知识库接口 update_docs 实现。
9.添加文件到知识库,并/或向量化
F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\api.py,如下所示:
app.post("/knowledge_base/upload_docs",
tags=["Knowledge Base Management"],
response_model=BaseResponse,
summary="上传文件到知识库,并/或进行向量化"
)(upload_docs)
(1)upload_docs 函数
def upload_docs(
file: List[UploadFile] = File(..., description="上传文件,支持多文件"),
knowledge_base_name: str = Form(..., description="知识库名称", examples=["samples"]),
override: bool = Form(False, description="覆盖已有文件"),
to_vector_store: bool = Form(True, description="上传文件后是否进行向量化"),
chunk_size: int = Form(CHUNK_SIZE, description="知识库中单段文本最大长度"),
chunk_overlap: int = Form(OVERLAP_SIZE, description="知识库中相邻文本重合长度"),
zh_title_enhance: bool = Form(ZH_TITLE_ENHANCE, description="是否开启中文标题加强"),
docs: Json = Form({}, description="自定义的docs,需要转为json字符串",
examples=[{"test.txt": [Document(page_content="custom doc")]}]),
not_refresh_vs_cache: bool = Form(False, description="暂不保存向量库(用于FAISS)"),
) -> BaseResponse:
| 序号 | 字段名 | 类型 | 解释 | 备注 |
|---|---|---|---|---|
| 1 | file | List[UploadFile] | 上传文件,支持多文件 | - |
| 2 | knowledge_base_name | str | 知识库名称 | - |
| 3 | override | bool | 覆盖已有文件 | - |
| 4 | to_vector_store | bool | 上传文件后是否进行向量化 | - |
| 5 | chunk_size | int | 知识库中单段文本最大长度 | 就是将长文本分割成多个较短的段落,每个段落的长度都不超过这个限制。 |
| 6 | chunk_overlap | int | 知识库中相邻文本重合长度 | 将长文本分割成多个较短的段落时,相邻段落之间重复的文本的长度。这通常是为了确保 LLM 能够理解文本的上下文。 |
| 7 | zh_title_enhance | bool | 是否开启中文标题加强 | 参考 kb_config.py 解释:1.是否开启中文标题加强,以及标题增强的相关配置;2.通过增加标题判断,判断哪些文本为标题,并在 metadata 中进行标记;3.然后将文本与往上一级的标题进行拼合,实现文本信息的增强。 |
| 8 | docs | Json | 自定义的 docs,需要转为 json 字符串 | 推测自定义文档主要是为了测试用途(不清楚还有没有其它的用途)。 |
| 9 | not_refresh_vs_cache | bool | 暂不保存向量库(用于 FAISS) | 目前支持 FAISS,是否保存向量库。 |
(2)先将上传的文件保存到磁盘
不再解释,就是将上传的文件保存到知识库本地相应的文件夹中。
(3)对保存的文件进行向量化
当 to_vector_store=True 时,调用更新知识库文档接口 update_docs。具体实现如下所示:
# 对保存的文件进行向量化
if to_vector_store: # 如果需要向量化
result = update_docs( # 调用update_docs接口
knowledge_base_name=knowledge_base_name, # 知识库名称
file_names=file_names, # 文件名称
override_custom_docs=True, # 覆盖之前自定义的docs
chunk_size=chunk_size, # 知识库中单段文本最大长度
chunk_overlap=chunk_overlap, # 知识库中相邻文本重合长度
zh_title_enhance=zh_title_enhance, # 是否开启中文标题加强
docs=docs, # 自定义的docs
not_refresh_vs_cache=True, # 暂不保存向量库(只有FAISS实现了)
)
failed_files.update(result.data["failed_files"]) # 更新上传失败的文件
if not not_refresh_vs_cache: # 如果需要保存向量库
kb.save_vector_store() # 保存向量库
默认 not_refresh_vs_cache=True,即暂不保存向量库。如果 not_refresh_vs_cache=False,那么执行 kb.save_vector_store()。FAISS 保存到磁盘(已实现),milvus 保存到数据库(未实现),PGVector 暂未支持(未实现)。具体实现,如下所示:
def save_vector_store(self):
self.load_vector_store().save(self.vs_path)
(4)接口调用
http://127.0.0.1/knowledge_base/upload_docs,如下所示:

控制台输出,可以看到使用的加载器为 UnstructuredFileLoader,然后将向量库保存到磁盘(FAISS),如下所示:
2024-01-21 19:17:56,650 - utils.py[line:286] - INFO: UnstructuredFileLoader used for F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\knowledge_base\LLM\content\data.txt
文档切分示例:page_content='{"Q": "宪法规定的公民法律义务有"}\n{"Q": "属于专门人民法院的是"}\n{"Q": "无效婚姻的种类包括"}\n{"Q": "刑事案件定义"}' metadata={'source': 'F:\\ConversationSystem\\ChatCopilot\\Langchain\\Langchain-Chatchat-0.2.8\\knowledge_base\\LLM\\content\\data.txt'}
Batches: 100%|██████████| 1/1 [00:00<00:00, 4.44it/s]
2024-01-21 19:18:04,893 - faiss_cache.py[line:24] - INFO: 已将向量库 ('LLM', 'bge-large-zh') 保存到磁盘
INFO: 127.0.0.1:61524 - "POST /knowledge_base/upload_docs HTTP/1.1" 200 OK

(5)可能遇到的问题
通过界面操作时,Browser files 上传一个文件之后,点击按钮"添加文件到知识库",出现如下所示:
INFO: 127.0.0.1:60656 - "POST /knowledge_base/upload_docs HTTP/1.1" 422 Unprocessable Entity
2024-01-21 19:10:25,208 - _client.py[line:1027] - INFO: HTTP Request: POST http://127.0.0.1:7861/knowledge_base/upload_docs "HTTP/1.1 422 Unprocessable Entity"
说明:暂未找到原因。
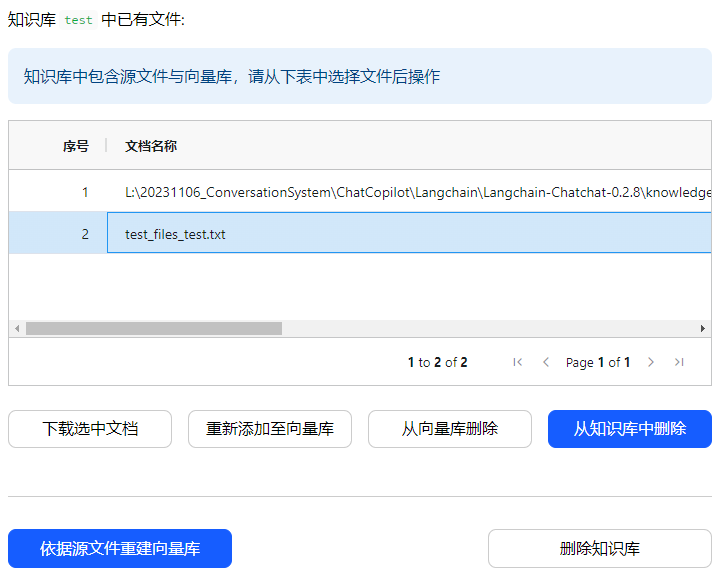
三.知识库操作 2
| 序号 | 操作名字 | 功能解释 | 链接 | 备注 |
|---|---|---|---|---|
| 1 | 下载选中文档 | 选中一个文档,然后下载,可以是源文件,也可以是向量库。 | http://127.0.0.1/knowledge_base/download_doc | - |
| 2 | 重新添加至向量库 | 1.如果是源文件,执行"添加至向量库"操作 2.如果是向量库,执行"重新添加至向量库"操作 | http://127.0.0.1/knowledge_base/upload_docs | - |
| 3 | 从向量库删除 | 1.如果选中的是源文件,那么该按钮为灰色。2.如果选中的是向量库,那么该按钮可操作。 | http://127.0.0.1/knowledge_base/delete_docs | - |
| 4 | 从知识库中删除 | 1.如果是源文件,那么该按钮可操作。2.如果是向量库,那么该按钮可操作。 | http://127.0.0.1/knowledge_base/delete_docs | - |
| 5 | 依据源文件重建向量库 | 该操作针对的是整个知识库,根据源文件重建向量库,并不针对某个具体的源文件或者向量库文件。 | http://127.0.0.1/knowledge_base/recreate_vector_store | - |
| 6 | 删除知识库 | 就是把整个知识库删除掉 |
1.下载选中文档
(1)download_doc 接口
F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\api.py,如下所示:
app.get("/knowledge_base/download_doc",
tags=["Knowledge Base Management"],
summary="下载对应的知识文件")(download_doc)
download_doc 接口主要是根据知识库名字和文件名字拿到文件路径,然后返回 FileResponse 对象。
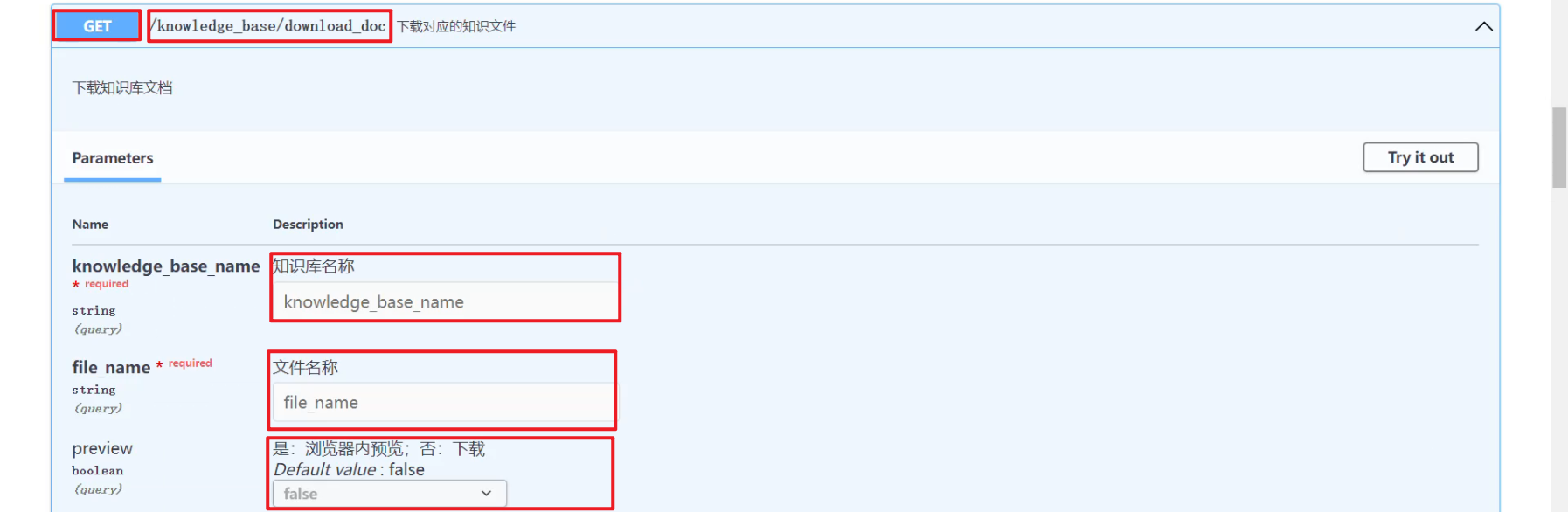
(2)接口调用
http://127.0.0.1/knowledge_base/download_doc,如下所示:
(3)界面操作
无论是下载源文件,还是向量库文件,都是先选中,然后下载。下载的向量库文件,和下载的源文件内容都是一样的,都是源文件的内容,而不是编码后的内容。
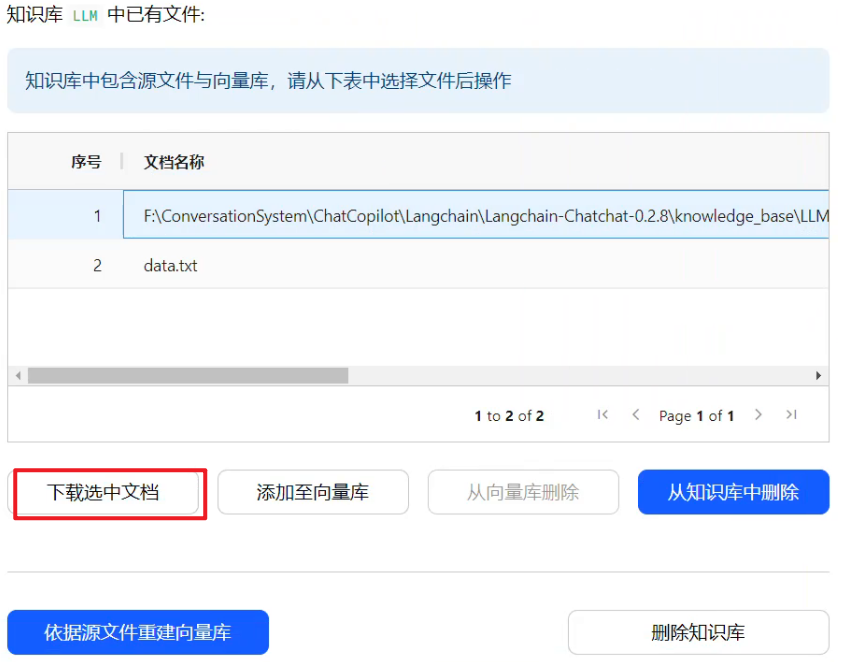
2.添加至向量库/重新添加至向量库
(1)界面操作
当选择源文件时,显示添加至向量库,如下所示:
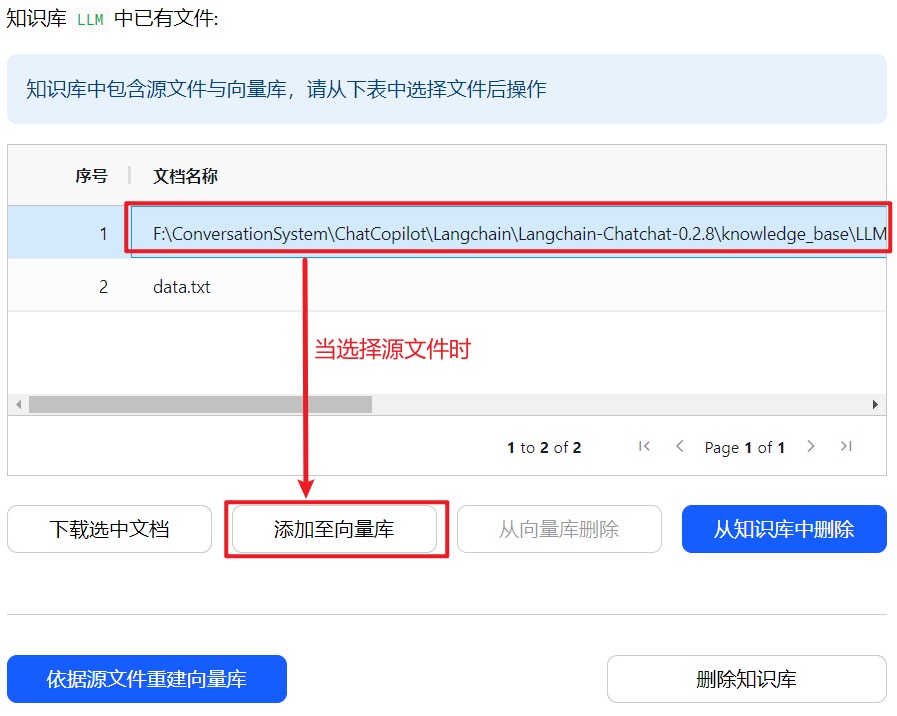
当选择向量库文件时,显示重新添加至向量库,如下所示:

(2)接口调用
无论是"添加至向量库",还是"重新添加至向量库"都是调用的 upload_docs 接口,"添加至向量库"控制台日志如下所示:
2024-01-21 23:59:11,127 - utils.py[line:286] - INFO: UnstructuredFileLoader used for F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\knowledge_base\LLM\content\data.txt
文档切分示例:page_content='{"Q": "宪法规定的公民法律义务有"}\n{"Q": "属于专门人民法院的是"}\n{"Q": "无效婚姻的种类包括"}\n{"Q": "刑事案件定义"}' metadata={'source': 'F:\\ConversationSystem\\ChatCopilot\\Langchain\\Langchain-Chatchat-0.2.8\\knowledge_base\\LLM\\content\\data.txt'}
2024-01-21 23:59:21,557 - faiss_cache.py[line:80] - INFO: loading vector store in 'LLM/vector_store/bge-large-zh' from disk.
2024-01-21 23:59:21,611 - SentenceTransformer.py[line:66] - INFO: Load pretrained SentenceTransformer: F:\HuggingFaceModel\bge-large-zh
2024-01-21 23:59:22,878 - loader.py[line:54] - INFO: Loading faiss with AVX2 support.
2024-01-21 23:59:22,878 - loader.py[line:58] - INFO: Could not load library with AVX2 support due to: ModuleNotFoundError("No module named 'faiss.swigfaiss_avx2'")
2024-01-21 23:59:22,878 - loader.py[line:64] - INFO: Loading faiss.
2024-01-21 23:59:23,050 - loader.py[line:66] - INFO: Successfully loaded faiss.
Batches: 100%|██████████| 1/1 [00:00<00:00, 5.64it/s]
2024-01-21 23:59:23,294 - faiss_cache.py[line:24] - INFO: 已将向量库 ('LLM', 'bge-large-zh') 保存到磁盘
2024-01-21 23:59:23,297 - _client.py[line:1027] - INFO: HTTP Request: POST http://127.0.0.1:7861/knowledge_base/update_docs "HTTP/1.1 200 OK"
INFO: 127.0.0.1:50606 - "POST /knowledge_base/update_docs HTTP/1.1" 200 OK
"重新添加至向量库"控制台日志如下所示:
2024-01-22 00:14:56,917 - utils.py[line:286] - INFO: UnstructuredFileLoader used for F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\knowledge_base\LLM\content\data.txt
文档切分示例:page_content='{"Q": "宪法规定的公民法律义务有"}\n{"Q": "属于专门人民法院的是"}\n{"Q": "无效婚姻的种类包括"}\n{"Q": "刑事案件定义"}' metadata={'source': 'F:\\ConversationSystem\\ChatCopilot\\Langchain\\Langchain-Chatchat-0.2.8\\knowledge_base\\LLM\\content\\data.txt'}
Batches: 100%|██████████| 1/1 [00:00<00:00, 4.71it/s]
2024-01-22 00:14:57,713 - faiss_cache.py[line:24] - INFO: 已将向量库 ('LLM', 'bge-large-zh') 保存到磁盘
2024-01-22 00:14:57,716 - _client.py[line:1027] - INFO: HTTP Request: POST http://127.0.0.1:7861/knowledge_base/update_docs "HTTP/1.1 200 OK"
INFO: 127.0.0.1:51617 - "POST /knowledge_base/update_docs HTTP/1.1" 200 OK
3.从向量库删除
(1)基本删除思路
只能删除向量库文件,不能删除源文件。因为当选中源文件时,这个按钮是禁用状态。基本删除思路为:删除向量库中的内容(比如 faiss),删除数据库中的内容(knowledge_file 数据表)。F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\api.py,如下所示:
app.post("/knowledge_base/delete_docs",
tags=["Knowledge Base Management"],
response_model=BaseResponse,
summary="删除知识库内指定文件"
)(delete_docs)
(2)接口调用
http://127.0.0.1/knowledge_base/delete_docs,如下所示:

4.从知识库中删除
(1)基本思路
无论是向量库文件,还是源文件都是可以删除的。基本删除思路为:删除向量库中的内容(比如 faiss),删除数据库中的内容(knowledge_file 数据表),删除上传文件夹中的文件。
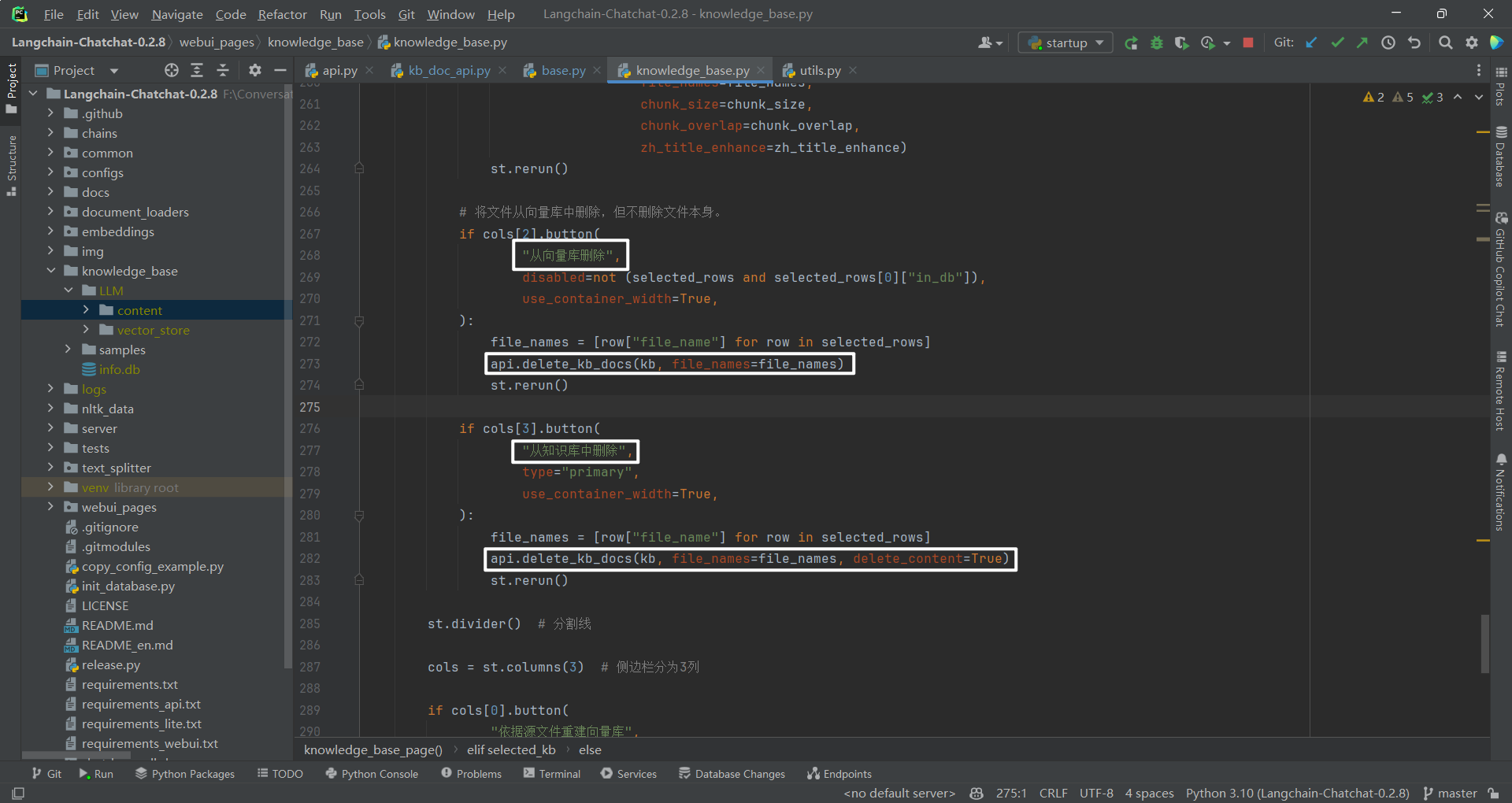
(2)接口调用
查看源码,从向量库删除和从知识库删除区别,前者"delete_content": false,而后者为"delete_content": true。这个字段主要是控制着是否删除文件夹。http://127.0.0.1/knowledge_base/delete_docs,如下所示:
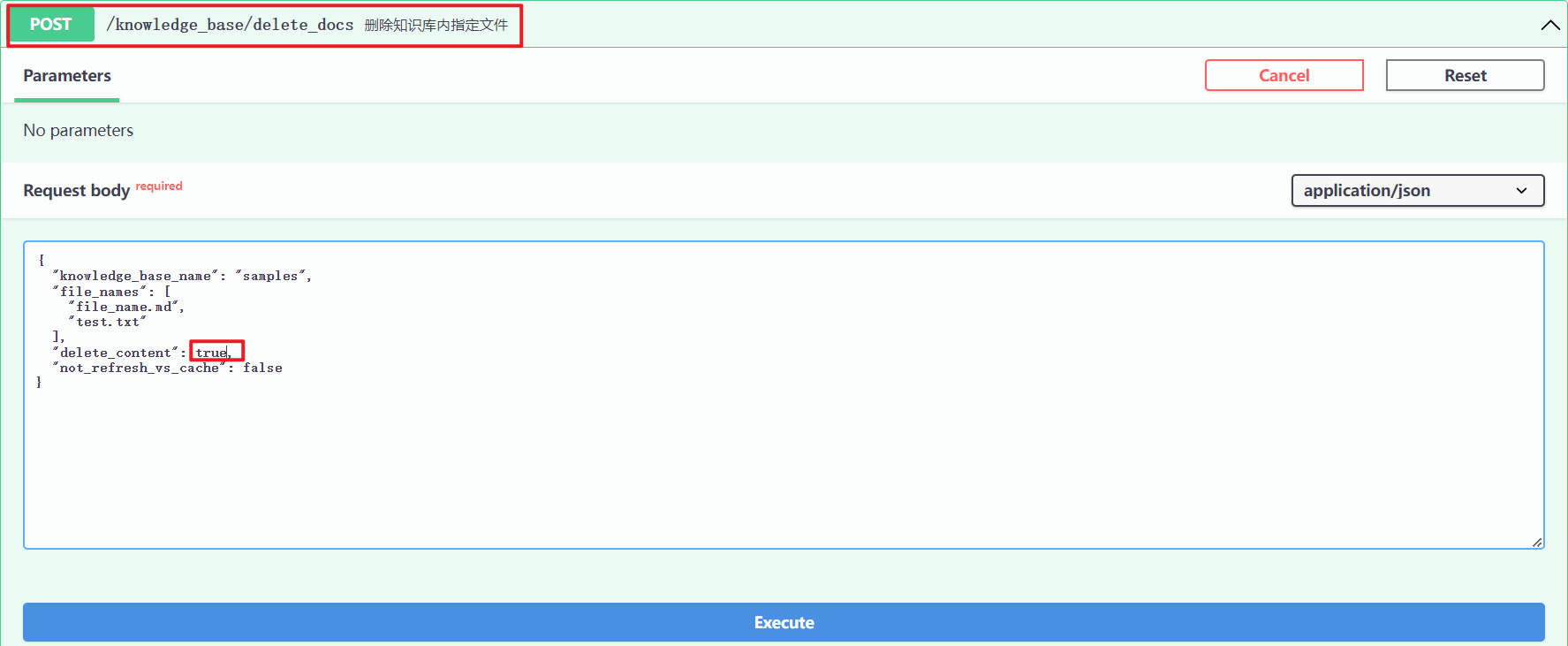
5.依据源文件重建向量库
F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\api.py,如下所示:
app.post("/knowledge_base/recreate_vector_store",
tags=["Knowledge Base Management"],
summary="根据content中文档重建向量库,流式输出处理进度。"
)(recreate_vector_store)
本质上就是将原来的向量库清空,然后重建操作。http://127.0.0.1/knowledge_base/recreate_vector_store 接口调用如下所示:
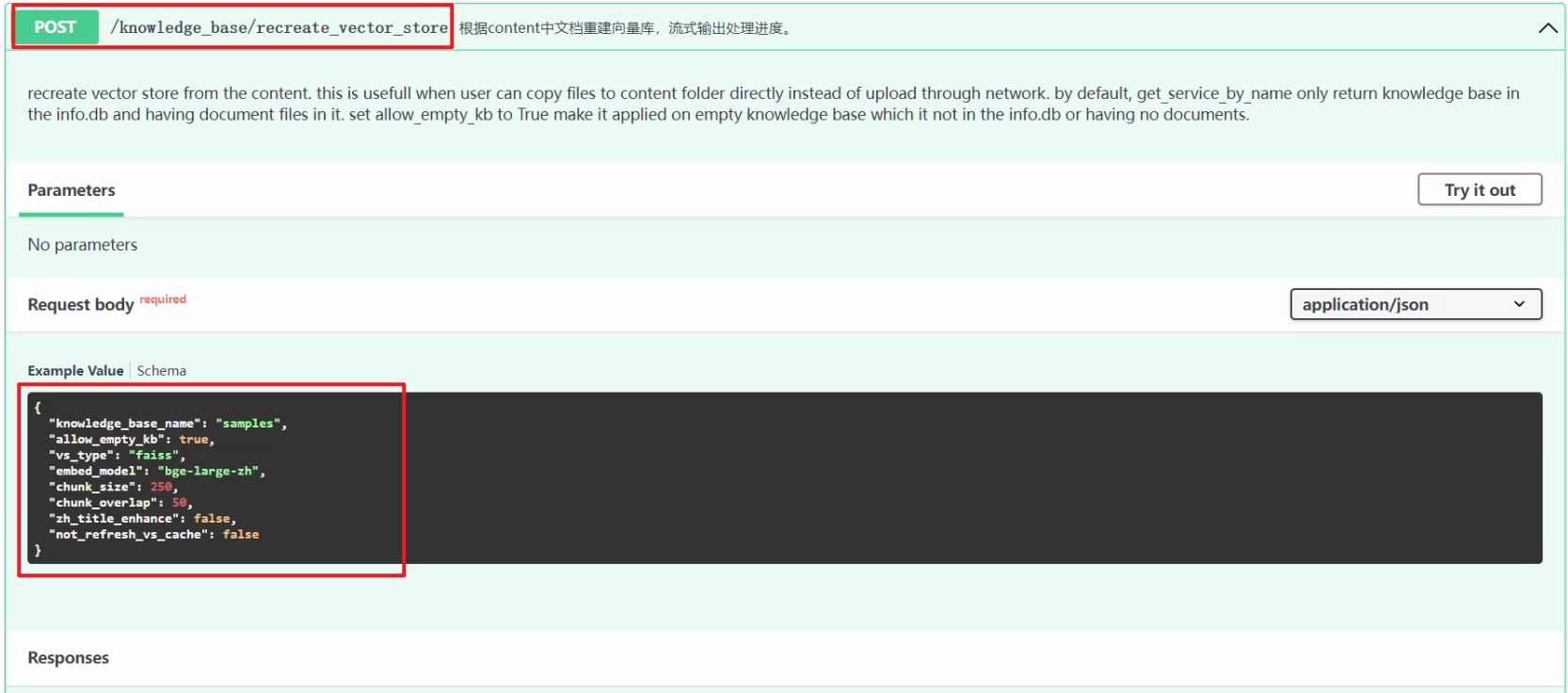
上述英文内容翻译:从内容重新创建矢量存储。当用户可以直接将文件复制到内容文件夹而不是通过网络上传时,这很有用。默认情况下,get_service_by_name 只返回 info.db 中的知识库并在其中包含文档文件。将 allow_empty_kb 设置为 True 使其应用于不在 info.db 中或没有文档的空知识库。
6.删除知识库
本质上是删除向量库、数据库信息和文件夹。F:\ConversationSystem\ChatCopilot\Langchain\Langchain-Chatchat-0.2.8\server\api.py,如下所示:
app.post("/knowledge_base/delete_knowledge_base",
tags=["Knowledge Base Management"],
response_model=BaseResponse,
summary="删除知识库"
)(delete_kb)
http://127.0.0.1/knowledge_base/接口调用如下所示:

除此之外,还有一些接口没有介绍实现逻辑,可参考文献[1]。如果不查看源代码,可能很难较为深入的理解每个操作步骤的具体实现逻辑。
参考文献
[1] Langchain-Chatchat API Server:http://127.0.0.1/docs
[2] https://github.com/chatchat-space/Langchain-Chatchat/releases/tag/v0.2.8
[3] 梳理Langchain-Chatchat知识库API接口(原文链接):https://z0yrmerhgi8.feishu.cn/wiki/XN7AwrH6DiCpMIkaNnAcPd7znZc
NLP工程化
1.本公众号以对话系统为中心,专注于Python/C++/CUDA、ML/DL/RL和NLP/KG/DS/LLM领域的技术分享。
2.本公众号Roadmap可查看飞书文档:https://z0yrmerhgi8.feishu.cn/wiki/Zpewwe2T2iCQfwkSyMOcgwdInhf
NLP工程化(公众号)

NLP工程化(星球号)

梳理Langchain-Chatchat知识库API接口的更多相关文章
- Node教程——API接口开发(MangoDB+Express)
一.大纲 大纲: 关于架构, 首先我们的有一个app.js这个就是根路由起点,用来最初的打入口 它的功能有: 1.1 引入模块创建基础的网站服务器, 1.2 导入bodyPasser,过滤还有处理我们 ...
- [源码分析] 带你梳理 Flink SQL / Table API内部执行流程
[源码分析] 带你梳理 Flink SQL / Table API内部执行流程 目录 [源码分析] 带你梳理 Flink SQL / Table API内部执行流程 0x00 摘要 0x01 Apac ...
- 物流一站式单号查询之快递鸟API接口(附Demo源码)
连载篇提前看 物流一站式单号查询之快递鸟API接口 物流一站式查询之TrackingMore篇 物流一站式查询之顺丰接口篇 物流一站式查询之快递100 前情提要 前三篇中,我们已经从注册.申请接口.调 ...
- 程序员不得不知道的 API 接口常识
说实话,我非常希望两年前刚准备找实习的自己能看到本篇文章,那个时候懵懵懂懂,跟着网上的免费教程做了一个购物商城就屁颠屁颠往简历上写. 至今我仍清晰地记得,那个电商教程是怎么定义接口的: 管它是增加.修 ...
- 干货来袭-整套完整安全的API接口解决方案
在各种手机APP泛滥的现在,背后都有同样泛滥的API接口在支撑,其中鱼龙混杂,直接裸奔的WEB API大量存在,安全性令人堪优 在以前WEB API概念没有很普及的时候,都采用自已定义的接口和结构,对 ...
- 12306官方火车票Api接口
2017,现在已进入春运期间,真的是一票难求,深有体会.各种购票抢票软件应运而生,也有购买加速包提高抢票几率,可以理解为变相的黄牛.对于技术人员,虽然写一个抢票软件还是比较难的,但是还是简单看看123 ...
- 快递Api接口 & 微信公众号开发流程
之前的文章,已经分析过快递Api接口可能被使用的需求及场景:今天呢,简单给大家介绍一下微信公众号中怎么来使用快递Api接口,来完成我们的需求和业务场景. 开发语言:Nodejs,其中用到了Neo4j图 ...
- web api接口同步和异步的问题
一般来说,如果一个api 接口带上Task和 async 一般就算得上是异步api接口了. 如果我想使用异步api接口,一般的动机是我在我的方法里面可能使用Task.Run 进行异步的去处理一个耗时的 ...
- HTTP API接口安全设计
HTTP API接口安全设计 API接口调用方式 HTTP + 请求签名机制 HTTP + 参数签名机制 HTTPS + 访问令牌机制 有没有更好的方案? OAuth授权机制 OAuth2.0服务 ...
- Postman - 功能强大的 API 接口请求调试和管理工具
Postman 是一款功能强大的的 Chrome 应用,可以便捷的调试接口.前端开发人员在开发或者调试 Web 程序的时候是需要一些方法来跟踪网页请求的,用户可以使用一些网络的监视工具比如著名的 Fi ...
随机推荐
- GitHub OAuth2的授权指南
一.OAuth2简介 OAuth 2.0(开放授权 2.0)是一种用于授权的开放标准,旨在允许用户在不提供他们的用户名和密码的情况下,授权第三方应用访问其在另一网站上的信息.它是在网络服务之间安全地共 ...
- ElasticSearch-1
原文链接:https://gaoyubo.cn/blogs/52ef5bf7.html 一.Elasticsearch 架构设计 Elasticsearch 架构层: Elasticsearch 五层 ...
- 最基本的SpringCloud的搭建
对于springcloud而言,模块是按业务进行区分的: 父工程 依赖 <parent> <groupId>org.springframework.boot</group ...
- C语言编程需要掌握的核心要点有哪些? 编程大神为你总结了这20个
摘要:C语言作为编程的入门语言,学习者如何快速掌握其核心知识点,面对茫茫书海,似乎有点迷茫.为了让各位快速地掌握C语言的知识内容,在这里对相关的知识点进行了归纳. 引言 笔者有十余年的C++开发经验, ...
- 华为AppCube通过中国信通院“低代码开发平台通用能力要求”评估!
摘要:华为AppCube应用魔方顺利通过信通院评估,被认证为具备 "低代码开发平台通用能力"的企业服务平台. 本文分享自华为云社区<华为AppCube通过中国信通院" ...
- 不会使用Spring的配置文件,赶紧把这个甩给他
摘要:文章从Spring程序的快速使用.Bean标签的使用和其属性的具体使用,每个属性都用代码来解释,运行结果和案例也写的都很明白. 本文分享自华为云社区<怎样使用Spring的配置文件?带大家 ...
- vmware14安装centos8
vmware14 推荐,直接选取centos8镜像,然后安装,发现是无法安装的. 然后选择自定义安装,然后,选择客户机操作系统,只有centos7 64位,没有centos8 64位的. 搜了一下,看 ...
- 火山引擎 DataTester:A/B 测试,让企业摆脱广告投放“乱烧钱”
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 在广告投放的场景下,一线广告优化师通常会创建多个计划,去测试不同的广告素材效果.这套方法看似科学,实际上却存在诸多 ...
- Windows 2016 2019 显示桌面图标
运行cmd窗口 输入命令 rundll32.exe shell32.dll,Control_RunDLL desk.cpl,,0 弹出桌面图标设置窗口
- Java 模拟数据库连接池的实现
前面学习过等待 - 通知机制,现在我们在其基础上添加一个超时机制,模拟从连接池中获取.使用和释放连接的过程.客户端获取连接的过程被设定为等待超时模式,即如果在 1000 毫秒内无法获取到可用连接,将会 ...