【重学C++】04 | 说透C++右值引用(上)
文章首发
引言
大家好,我是只讲技术干货的会玩code,今天是【重学C++】的第四讲,在前面《03 | 手撸C++智能指针实战教程》中,我们或多或少接触了右值引用和移动的一些用法。
右值引用是 C++11 标准中一个很重要的特性。第一次接触时,可能会很乱,不清楚它们的目的是什么或者它们解决了什么问题。接下来两节课,我们详细讲讲右值引用及其相关应用。内容很干,注意收藏!
左值 vs 右值
简单来说,左值是指可以使用&符号获取到内存地址的表达式,一般出现在赋值语句的左边,比如变量、数组元素和指针等。
int i = 42;
i = 43; // ok, i是一个左值
int* p = &i; // ok, i是一个左值,可以通过&符号获取内存地址
int& lfoo() { // 返回了一个引用,所以lfoo()返回值是一个左值
int a = 1;
return a;
};
lfoo() = 42; // ok, lfoo() 是一个左值
int* p1 = &lfoo(); // ok, lfoo()是一个左值
相反,右值是指无法获取到内存地址的表达是,一般出现在赋值语句的右边。常见的有字面值常量、表达式结果、临时对象等。
int rfoo() { // 返回了一个int类型的临时对象,所以rfoo()返回值是一个右值
return 5;
};
int j = 0;
j = 42; // ok, 42是一个右值
j = rfoo(); // ok, rfoo()是右值
int* p2 = &rfoo(); // error, rfoo()是右值,无法获取内存地址
左值引用 vs 右值引用
C++中的引用是一种别名,可以通过一个变量名访问另一个变量的值。
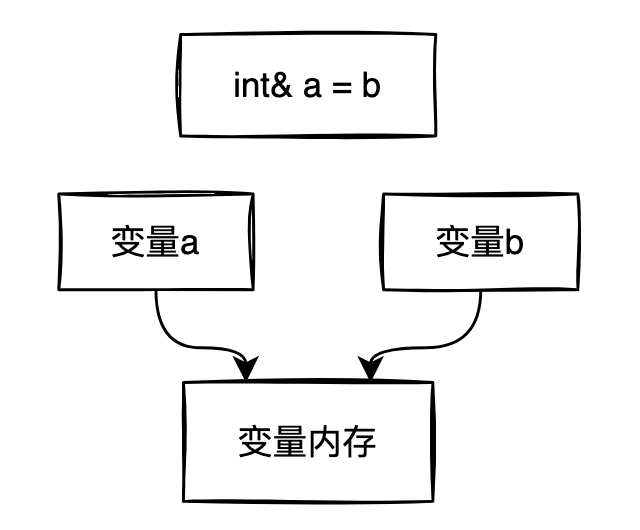
上图中,变量a和变量b指向同一块内存地址,也可以说变量a是变量b的别名。
在C++中,引用分为左值引用和右值引用两种类型。左值引用是指对左值进行引用的引用类型,通常使用&符号定义;右值引用是指对右值进行引用的引用类型,通常使用&&符号定义。
class X {...};
// 接收一个左值引用
void foo(X& x);
// 接收一个右值引用
void foo(X&& x);
X x;
foo(x); // 传入参数为左值,调用foo(X&);
X bar();
foo(bar()); // 传入参数为右值,调用foo(X&&);
所以,通过重载左值引用和右值引用两种函数版本,满足在传入左值和右值时触发不同的函数分支。
值得注意的是,void foo(const X& x);同时接受左值和右值传参。
void foo(const X& x);
X x;
foo(x); // ok, foo(const X& x)能够接收左值传参
X bar();
foo(bar()); // ok, foo(const X& x)能够接收右值传参
// 新增右值引用版本
void foo(X&& x);
foo(bar()); // ok, 精准匹配调用foo(X&& x)
到此,我们先简单对右值和右值引用做个小结:
- 像字面值常量、表达式结果、临时对象等这类无法通过
&符号获取变量内存地址的,称为右值。 - 右值引用是一种引用类型,表示对右值进行引用,通常使用
&&符号定义。
右值引用主要解决一下两个问题:
- 实现移动语义
- 实现完美转发
这一节我们先详细讲讲右值是如何实现移动效果的,以及相关的注意事项。完美转发篇幅有点多,我们留到下节讲。
复制 vs 移动
假设有一个自定义类X,该类包含一个指针成员变量,该指针指向另一个自定义类对象。假设O占用了很大内存,创建/复制O对象需要较大成本。
class O {
public:
O() {
std::cout << "call o constructor" << std::endl;
};
O(const O& rhs) {
std::cout << "call o copy constructor." << std::endl;
}
};
class X {
public:
O* o_p;
X() {
o_p = new O();
}
~X() {
delete o_p;
}
};
X 对应的拷贝赋值函数如下:
X& X::operator=(X const & rhs) {
// 根据rhs.o_p生成的一个新的O对象资源
O* tmp_p = new O(*rhs.o_p);
// 回收x当前的o_p;
delete this->o_p;
// 将tmp_p 赋值给 this.o_p;
this->o_p = tmp_p;
return *this;
}
假设对X有以下使用场景:
X x1;
X x2;
x1 = x2;
上述代码输出:
call o constructor
call o constructor
call o copy constructor
x1和x2初始化时,都会执行new O(), 所以会调用两次O的构造函数;执行x1=x2时,会调用一次O的拷贝构造函数,根据x2.o_p复制一个新的O对象。
由于x2在后续代码中可能还会被使用,所以为了避免影响x2,在赋值时调用O的拷贝构造函数复制一个新的O对象给x1在这种场景下是没问题的。
但在某些场景下,这种拷贝显得比较多余:
X foo() {
return X();
};
X x1;
x1 = foo();
代码输出与之前一样:
call o constructor
call o constructor
call o copy constructor
在这个场景下,foo()创建的那个临时X对象在后续代码是不会被用到的。所以我们不需要担心赋值函数中会不会影响到那个临时X对象,没必要去复制一个新的O对象给x1。
更高效的做法,是直接使用swap交换临时X对象的o_p和x1.o_p。这样做有两个好处:1. 不用调用耗时的O拷贝构造函数,提高效率;2. 交换后,临时X对象拥有之前x1.o_p指向的资源,在析构时能自动回收,避免内存泄漏。
这种避免高昂的复制成本,而直接将资源从一个对象"移动"到另外一个对象的行为,就是C++的移动语义。
哪些场景适用移动操作呢?无法获取内存地址的右值就很合适,我们不需要担心后续的代码会用到该右值。
最后,我们看下移动版本的赋值函数
X& operator=(X&& rhs) noexcept {
std::swap(this->o_p, rhs.o_p);
return *this;
};
看下使用效果:
X x1;
x1 = foo();
输出结果:
call o constructor
call o constructor
右值引用一定是右值吗?
假设我们有以下代码:
class X {
public:
// 复制版本的赋值函数
X& operator=(const X& rhs);
// 移动版本的赋值函数
X& operator=(X&& rhs) noexcept;
};
void foo(X&& x) {
X x1;
x1 = x;
}
类X重载了复制版本和移动版本的赋值函数。现在问题是:x1=x这个赋值操作调用的是X& operator=(const X& rhs)还是 X& operator=(X&& rhs)?
针对这种情况,C++给出了相关的标准:
Things that are declared as rvalue reference can be lvalues or rvalues. The distinguishing criterion is: if it has a name, then it is an lvalue. Otherwise, it is an rvalue.
也就是说,只要一个右值引用有名称,那对应的变量就是一个左值,否则,就是右值。
回到上面的例子,函数foo的入参虽然是右值引用,但有变量名x,所以x是一个左值,所以operator=(const X& rhs)最终会被调用。
再给一个没有名字的右值引用的例子
X bar();
// 调用X& operator=(X&& rhs),因为bar()返回的X对象没有关联到一个变量名上
X x = bar();
这么设计的原因也挺好理解。再改下foo函数的逻辑:
void foo(X&& x) {
X x1;
x1 = x;
...
std::cout << *(x.inner_ptr) << std::endl;
}
我们并不能保证在foo函数的后续逻辑中不会访问到x的资源。所以这种情况下如果调用的是移动版本的赋值函数,x的内部资源在完成赋值后就乱了,无法保证后续的正常访问。
std::move
反过来想,如果我们明确知道在x1=x后,不会再访问到x,那有没有办法强制走移动赋值函数呢?
C++提供了std::move函数,这个函数做的工作很简单: 通过隐藏掉入参的名字,返回对应的右值。
X bar();
X x1
// ok. std::move(x1)返回右值,调用移动赋值函数
X x2 = std::move(x1);
// ok. std::move(bar())与 bar()效果相同,返回右值,调用移动赋值函数
X x3 = std::move(bar());
最后,用一个容易犯错的例子结束这一环节
class Base {
public:
// 拷贝构造函数
Base(const Base& rhs);
// 移动构造函数
Base(Base&& rhs) noexcept;
};
class Derived : Base {
public:
Derived(Derived&& rhs)
// wrong. rhs是左值,会调用到 Base(const Base& rhs).
// 需要修改为Base(std::move(rhs))
: Base(rhs) noexcept {
...
}
}
返回值优化
依照惯例,还是先给出类X的定义
class X {
public:
// 构造函数
X() {
std::cout << "call x constructor" <<std::endl;
};
// 拷贝构造函数
X(const X& rhs) {
std::cout << "call x copy constructor" << std::endl;
};
// 移动构造函数
X(X&& rhs) noexcept {
std::cout << "call x move constructor" << std::endl
};
}
大家先思考下以下两个函数哪个性能比较高?
X foo() {
X x;
return x;
};
X bar() {
X x;
return std::move(x);
}
很多读者可能会觉得foo需要一次复制行为:从x复制到返回值;bar由于使用了std::move,满足移动条件,所以触发的是移动构造函数:从x移动到返回值。复制成本 > 移动成本,所以bar性能更好。
实际效果与上面的推论相反,bar中使用std::move反倒多余了。现代C++编译器会有返回值优化。换句话说,编译器将直接在foo返回值的位置构造x对象,而不是在本地构造x然后将其复制出去。很明显,这比在本地构造后移动效率更快。
以下是foo和bar的输出:
// foo
call x constructor
// bar
call x constructor
call x move constructor
移动需要保证异常安全
细心的读者可能已经发现了,在前面的几个小节中,移动构造/赋值函数我都在函数签名中加了关键字noexcept,这是向调用者表明,我们的移动函数不会抛出异常。
这点对于移动函数很重要,因为移动操作会对右值造成破坏。如果移动函数中发生了异常,可能会对程序造成不可逆的错误。以下面为例
class X {
public:
int* int_p;
O* o_p;
X(X&& rhs) {
std::swap(int_p, rhs.int_p);
...
其他业务操作
...
std::swap(o_p, rhs.o_p);
}
}
如果在「其他业务操作」中发生了异常,不仅会影响到本次构造,rhs内部也已经被破坏了,后续无法重试构造。所以,除非明确标识noexcept,C++在很多场景下会慎用移动构造。
比较经典的场景是std::vector 扩缩容。当vector由于push_back、insert、reserve、resize 等函数导致内存重分配时,如果元素提供了一个noexcept的移动构造函数,vector会调用该移动构造函数将元素移动到新的内存区域;否则,则会调用拷贝构造函数,将元素复制过去。
总结
今天我们主要学了C++中右值引用的相关概念和应用场景,并花了很大篇幅讲解移动语义及其相关实现。
右值引用主要解决实现移动语义和完美转发的问题。我们下节接着讲解右值是如何实现完美转发。欢迎关注,及时收到推送~
【重学C++】04 | 说透C++右值引用(上)的更多相关文章
- Effective Modern C++:05右值引用、移动语义和完美转发
移动语义使得编译器得以使用成本较低的移动操作,来代替成本较高的复制操作:完美转发使得人们可以撰写接收任意实参的函数模板,并将其转发到目标函数,目标函数会接收到与转发函数所接收到的完全相同的实参.右值引 ...
- 右值引用、move与move constructor
http://blog.chinaunix.net/uid-20726254-id-3486721.htm 这个绝对是新增的top特性,篇幅非常多.看着就有点费劲,总结更费劲. 原来的标准当中,参数与 ...
- C++ 11 右值引用
C++11中引入的一个非常重要的概念就是右值引用.理解右值引用是学习“移动语义”(move semantics)的基础.而要理解右值引用,就必须先区分左值与右值. 注意:左值右值翻译可能有些问题 *L ...
- C++标准库之右值引用相关:引用折叠
引用折叠 引用折叠出现的情况在于范型编程时. void f(T&& param); f(10); int x = 10; f(x); 这两者都可运行成功. 由于存在T&& ...
- Item 25: 对右值引用使用std::move,对universal引用则使用std::forward
本文翻译自<effective modern C++>,由于水平有限,故无法保证翻译完全正确,欢迎指出错误.谢谢! 博客已经迁移到这里啦 右值引用只能绑定那些有资格被move的对象上去.如 ...
- (原创)C++11改进我们的程序之右值引用
本次主要讲c++11中的右值引用,后面还会讲到右值引用如何结合std::move优化我们的程序. c++11增加了一个新的类型,称作右值引用(R-value reference),标记为T & ...
- 谈谈 C++ 中的右值引用
转自:https://liam0205.me/2016/12/11/rvalue-reference-in-Cpp/ 最近在改 XGBoost 的代码.XGBoost 在代码中使用了很多来自 C++1 ...
- c++11——右值引用
1. 左值和右值 左值是表达式结束之后仍然存在的持久化对象,而右值是指表达式结束时就不再存在的临时对象. c++11中,右值分为两种类型:将亡值(xvalue, expiring value) ...
- C++11新特性之右值引用(&&)、移动语义(move)、完美转换(forward)
1. 右值引用 个人认为右值引用的目的主要是为了是减少内存拷贝,优化性能. 比如下面的代码: String Fun() { String str = "hello world"; ...
- C++ 右值引用与move
C++ 右值引用与move 右值引用 C++中所有的值都必然属于左值.右值二者之一.左值是指表达式结束后依然存在的持久化对象,右值是指表达式结束时就不再存在的临时对象. 所有的具名变量或者对象都是左值 ...
随机推荐
- kubernetes集成GPU原理
这里以Nvidia GPU设备如何在Kubernetes中管理调度为例研究, 工作流程分为以下两个方面: 如何在容器中使用GPU Kubernetes 如何调度GPU 容器中使用GPU 想要在容器中的 ...
- 在CentOS中安装和使用nginx
概述 本文简单讲述一下,如何快速将一个内网的Web服务通过nginx提供给外网访问,并且启用HTTPS.例如我们部署了一个kubesphere,地址为192.168.202.151:30880,需要通 ...
- ISCTF 2022
Re SigninReverse ida 64 位 打开程序,即可获得flag ISCTF{27413241-9eab-41e2-aca1-88fe8b525956} ezbase # coding= ...
- GO实现Redis:GO实现Redis集群(5)
采用一致性hash算法将key分散到不同的节点,客户端可以连接到集群中任意一个节点 https://github.com/csgopher/go-redis 本文涉及以下文件: consistenth ...
- Go - 高并发抢到红包实现
// utils.gopackage mainimport ( "fmt" "math/rand" "sync" "time&qu ...
- R语言包和中文乱码解决方案
常用R语言包 --数据处理:lubridata ,plyr ,reshape2,stringr,formatR,mcmc: --机器学习:nnet,rpart,tree,party,lars,boos ...
- 手写Mybatis代码实现会出现的问题
实现自定义框架过程中遇到的问题及解决方案: 1.执行 Resources.class.getClassLoader().getResourceAsStream(path) 方法无法获得去字节输入流 解 ...
- [Java EE]缓存技术初探
1 背景 使用场景:计算或检索一个值的代价很高,并且对同样的输入需要不止一次获取值的时候,就应当考虑使用缓存. 高并发下,为提高 频繁 查询 大量 可能常用的 数据库数据的 查询效率. 大部分情况下, ...
- day8:列表相关函数&深浅拷贝&字典相关函数&集合相关操作/函数
字符串/列表/字典/集合 目录 字符串相关操作: 拼接 重复 跨行拼接 索引 切片字符串相关函数:常规11+is系列3+填充去除6+最重要3字符串拓展:字符串的格式化format 列表的相关操作:拼接 ...
- 浅析pcba测试
说起PCB大家都很熟悉,那大家知道什么是PCBA吗?它是指将PCB板进行加工,支撑一个成品线路板.而PCBA测试就是对线路板进行一个功能测试.电路测试.那么为什么一定要对PAB板进行检测呢?它有什 ...