A Novel Cascade Binary Tagging Framework for Relational Triple Extraction(论文研读与复现)
A Novel Cascade Binary Tagging Framework for Relational Triple Extraction
Zhepei Wei,Jianlin Su, Yue Wang, Yuan Tian, Yi Chang
(ACL 2020)
研究背景:
以往的方法大多将关系建模为实体対上的一个离散的标签,这也是一种非常符合直觉的做法:首先通过命名实体识别(Named Entity Recognition, NER)确定出句子中所有的实体,然后学习一个关系分类器在所有的实体对上做RC,最终得到我们所需的关系三元组。然而这种Formulation在多个关系三元组有重叠的情况下会使得关系分类成为一个极其困难的不平衡多分类问题,导致最终抽取出的关系三元组不够全面和准确。
本文的解决思路:
在本文中我们提出了一个新的Formulation,以一种新的视角来重新审视经典的关系三元组抽取问题,
并在此基础上实现了一个不受重叠三元组问题困扰的CasRel标注框架(Cascade Binary Tagging Framework)来解决RTE任务。
CasRel框架最核心思想:把关系(Relation)建模为将头实体(Subject)映射到尾实体(Object)的函数,而不是将其视为实体对上的标签。
具体来说,我们不学习关系分类器: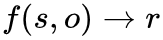
而是学习关系特定的尾实体标注器: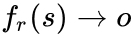
每个标注器都将在给定关系和头实体的条件下识别出所有可能的尾实体。
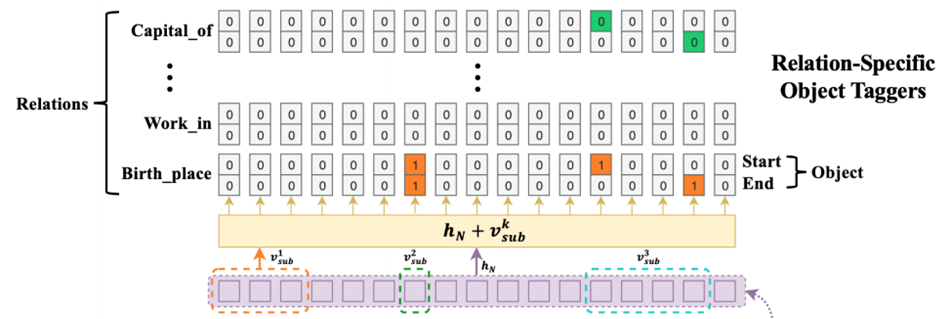
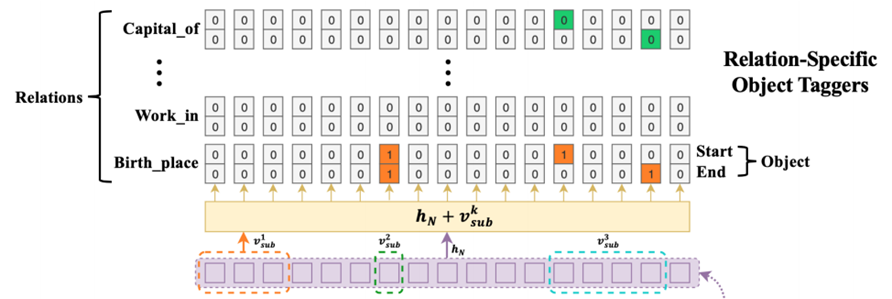
在这种框架下,关系三元组抽取问题就被分解为如下的两步过程:首先,我们确定出句子中所有可能的头实体; 然后针对每个头实体,我们使用关系特定的标注器来同时识别出所有可能的关系和对应的尾实体。
CASREL框架:
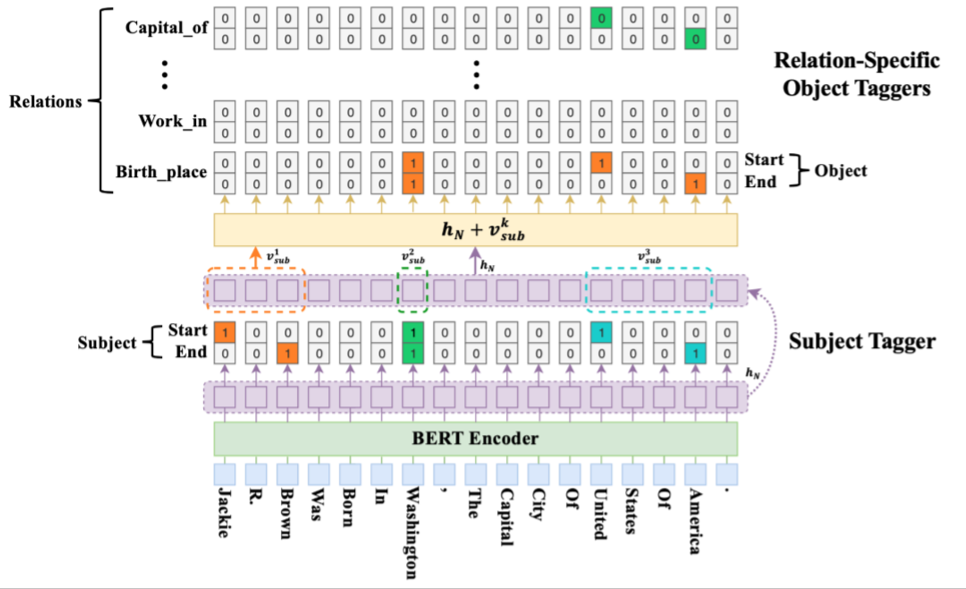
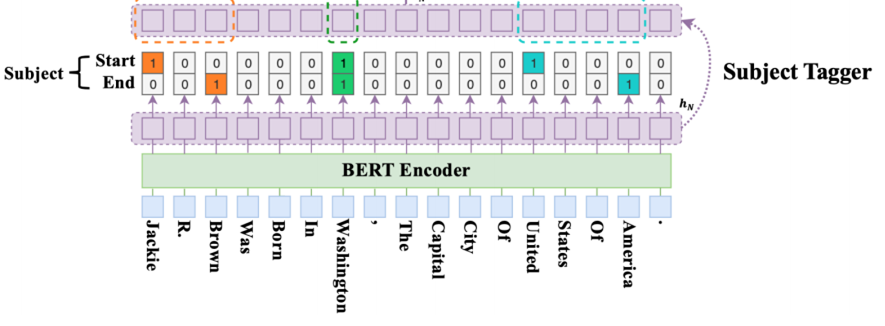
CASREL模型由BERT编码层模块、主体标记模块、特定关系下客体的标记模块三个模块构成。
新的目标函数:训练目标,就是尽可能使公式(1)的值最大。
D:训练的句子集合
_j:可能的三元组
s∈ _j:表示在三元组Tj中的主体;
_j | s :表示主体是s的三元组Tj;
(r,o)∈ _j | s:表示主体是s的三元组_j中的(r,o)对;
R:表示所有可能的关系;
R\ _j | s: 表示除了主体是s的三元组外的所有关系;
o∅:表示一个空的客体;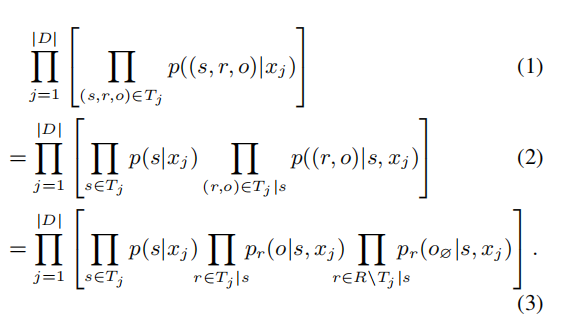
这样表示的优点:
1、直接从三元组的级别进行优化。
2、不做任何重叠实体的假设,通过精心设计来解决重贴三元组的问题。
3、公式(3)提供了一种新的思路,就是使用s和r的映射函数来预测o是什么,而不是传统的s和o来进行分类。
BERT encoder:
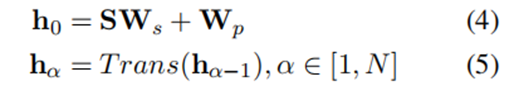
S:输入词的独热编码
_:表示embedding表
_p:表示句子中p位置的位置向量
Trans:表示一个transformer的encoder层
Cascade Decoder:
在经过BERT encoder之后,需要decoder提取三元组。
通过两个级联步获取三元组:
1、先标记处句子中所有的主体
2、对于每个标记的主体,检查所有关系是否存在与主体相关的客体。
因此,级联解码层包含了两个模块:
1、主体标记模块
2、给定一组特定于关系的客体标记模块
Cascade Decoder——Subject Tagger:
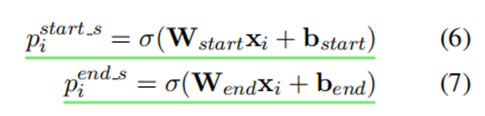
_^(_):表示第i个token是subject起始位置的概率
_^(_):表示第i个token是subject的结束位置的概率
σ 为函数
这一步优化的目标是给出一个句子表示x: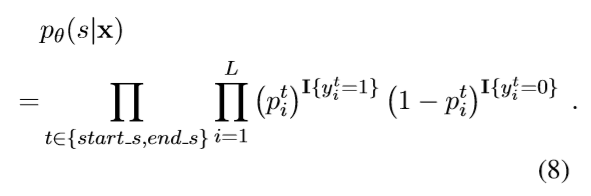
I{z}=1 if z为真,否则I{z}=0;
_^:表示第i个token的t标记的值;
t只有两种情况:start_s和end_s;
这个公式的意思就是说优化的目标是:如果实际_^为真,
那么说明我们应使得_^的概率尽可能大,否则,使得_^尽可能小。
对于句子中多个subject的检测,采用最近的start-end对来进行主体检测。
Cascade Decoder —— Relation-specific Object Taggers:
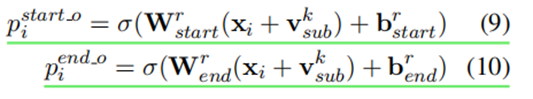
_^:表示subject tagger模块下的第k个主体的编码表示向量。
_^ :由多个token组成的情况:如果subject是多个token构成的,那么取它们的平均值作为新的_^
优化目标:
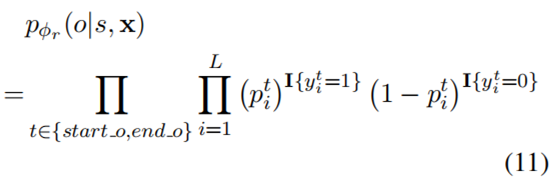
I{z}=1 if z为真,否则I{z}=0;
_^:表示第i个token的t标记的值;
t只有两种情况:start_s和end_s;
如果当前的映射函数r下不存在object,
那么对于所有的_^都设置为0。
整体的目标函数:
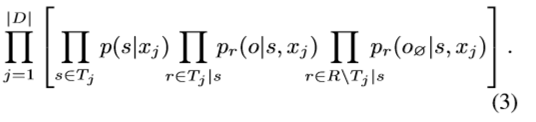
对公式(3)计算log可知,目标函数J(Θ)为:
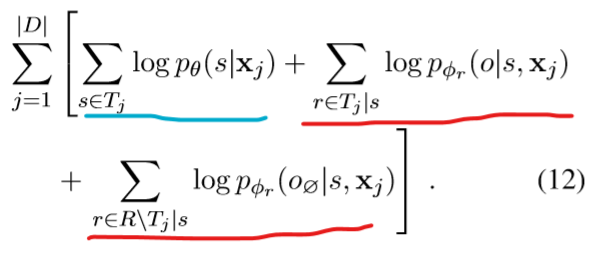
实验结果:
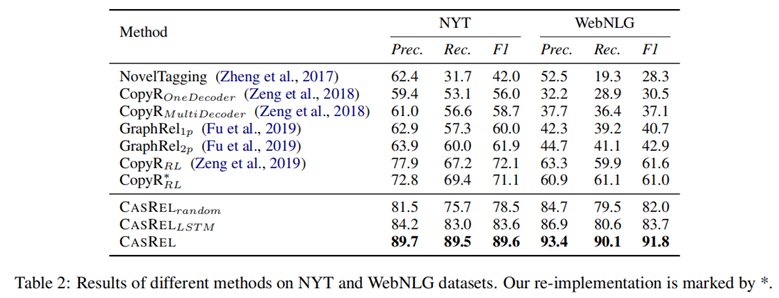
CASREL框架在公开数据集上效果提升很大。
论文复现:
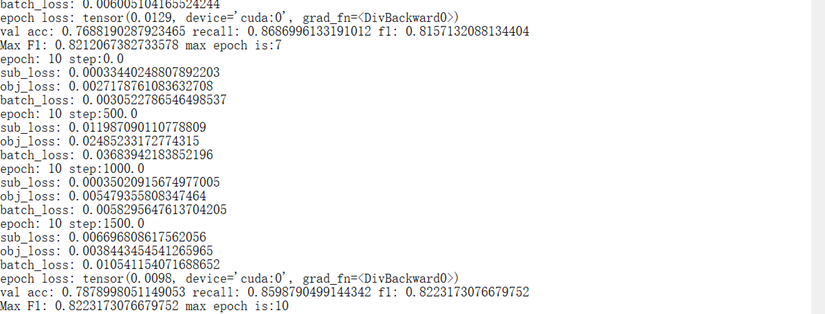
作者在GitHub开源了模型的keras源码。
本人用pytorch重新复现了该模型,在NYT数据集上10个epoch之后F1就达到了82%,效果很不错。
A Novel Cascade Binary Tagging Framework for Relational Triple Extraction(论文研读与复现)的更多相关文章
- Adding Cues (线索、提示) to Binary Feature Descriptors for Visual Place Recognition 论文阅读
对于有想法改良描述子却无从下手的同学还是比较有帮助的. Abstract 在这个文章中我们提出了一种嵌入continues and selector(感觉就是analogue和digital的区别)线 ...
- 《Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases》论文总结
Aurora总结 说明:本文为论文 <Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relation ...
- 人工智能论文解读精选 | PRGC:一种新的联合关系抽取模型
NLP论文解读 原创•作者 | 小欣 论文标题:PRGC: Potential Relation and Global Correspondence Based Joint Relational ...
- 目标检测 | 经典算法 Cascade R-CNN: Delving into High Quality Object Detection
作者从detector的overfitting at training/quality mismatch at inference问题入手,提出了基于multi-stage的Cascade R-CNN ...
- NeurIPS 2019 Spotlight | Cascade RPN,结构的艺术带来极致的提升
论文提出Cascade RPN算法来提升RPN模块的性能,该算法重点解决了RPN在迭代时anchor和feature不对齐的问题,论文创新点足,效果也很惊艳,相对于原始的RPN提升13.4%AR 论文 ...
- 使用valgrind检查内存
Valgrind是运行在Linux上一套基于仿真技术的程序调试和分析工具,是公认的最接近Purify的产品,它包含一个内核——一个软件合成的CPU,和一系列的小工具,每个工具都可以完成一项任务——调试 ...
- EF级联删除
引言 在主表中指定Key,子表中指定Required后,并不会在数据库中生成级联删除的外键.那怎么才能使EF在数据中生成级联删除的外键? SQLServer数据库中级联删除功能配置界面: 上图 ...
- iOS安全相关学习资料
https://github.com/zhengmin1989/iOS_ICE_AND_FIRE (冰与火代码) http://weibo.com/zhengmin1989?is_hot=1 (蒸米 ...
- linux下内存泄露检测工具Valgrind介绍
目前在linux开发一个分析实时路况的应用程序,在联合测试中发现程序存在内存泄露的情况. 这下着急了,马上就要上线了,还好发现了一款Valgrind工具,完美的解决了内存泄露的问题. 推荐大家可以使用 ...
- [转贴] C++内存管理检测工具 Valgrind
用C/C++开发其中最令人头疼的一个问题就是内存管理,有时候为了查找一个内存泄漏或者一个内存访问越界,需要要花上好几天时间,如果有一款工具能够帮助我们做这件事情就好了,valgrind正好就是这样的一 ...
随机推荐
- doris建表报错 errCode = 2, detailMessage = Scale of decimal must between 0 and 9. Scale was set to: 10
doris建表报错 问题背景 当我从Mpp库向doris库中导数据时,需要先创建对应的数据表,将Mpp库中表的建表语句略作修改后,在doris服务器上运行 CREATE TABLE opt_conne ...
- Llama2-Chinese项目:3.1-全量参数微调
提供LoRA微调和全量参数微调代码,训练数据为data/train_sft.csv,验证数据为data/dev_sft.csv,数据格式如下所示: "<s>Human: &q ...
- 万字长文 | 泰康人寿基于 Apache Hudi 构建湖仓一体平台的应用实践
文章贡献者 Authors 技术指导: 泰康人寿 数据架构资深专家工程师 王可 文章作者: 泰康人寿 数据研发工程师 田昕峣 摘要 Abstract 本文详细介绍了泰康人寿基于 Apache Hudi ...
- CefSharp自定义滚动条样式
在WinForm/WPF中使用CefSharp混合开发时,通常需要自定义滚动条样式,以保证应用的整体风格统一.本文将给出一个简单的示例介绍如何自定义CefSharp中滚动条的样式. 基本思路 在前端开 ...
- 爽。。。一键导出 MySQL 表结构,告别手动梳理表结构文档了。。。
背景 系统需要交付,客户要求提供交维材料,包括系统的表结构,安排开发人员进行梳理,效率比较慢,遂自己花点时间捣鼓一下,发现有此插件,记录一下方便与同事分享 前提条件 必须有 go语言环境,有的话直接看 ...
- 《流畅的Python》 读书笔记 第二章数据结构(2) 231011
2.5 对序列使用+和* 通常 + 号两侧的序列由相同类型的数据所构成,在拼接的过程中,两个被操作的序列都不会被修改,Python 会新建一个包含同样类型数据的序列来作为拼接的结果 +和*都遵循这个规 ...
- 【算法】游戏中的学习,使用c#面向对象特性控制游戏角色移动
最近,小悦的生活像是一首繁忙的交响曲,每天忙得团团转,虽然她的日程安排得满满当当,但她并未感到充实.相反,她很少有时间陪伴家人,这让她感到有些遗憾.在周五的午后,小悦的哥哥突然打来电话,他的声音里充满 ...
- Oracle 11g数据库详解(2017-01-23更新)
Oracle 11g数据库详解 整理者:赤勇玄心行天道 QQ:280604597 Email:280604597@qq.com 大家有什么不明白的地方,或者想要详细了解的地方可以联系我,我会认真回复的 ...
- QT Recursive repaint detected 检测到递归重绘
1.打印绘图时的线程号,如果与主线程号不一致,则需要使用信号传递数据,在主线程窗体中绘图 如下: qDebug() << "当前线程:" <<QThread ...
- 如何使用SHC对Shell脚本进行封装和源码隐藏
在许多情况下,我们需要保护我们的shell脚本源码不被别人轻易查看.这时,使用shc工具将shell脚本编译成二进制文件是一个有效的方法.本文将详细介绍如何在线和离线条件下安装shc,并将其用于编译你 ...