【算法】priority_queue在力扣题中的应用 | 力扣692 | 力扣347 | 力扣295 【超详细的注释和算法解释】
说在前面的话
博主也好长一段时间没有更新力扣的刷题系列了,今天给大家带来一些优先队列的经典题目,今天博主还是用C++给大家讲解,希望大家可以从中学到一些东西。
前言
那么这里博主先安利一下一些干货满满的专栏啦!
手撕数据结构![]() https://blog.csdn.net/yu_cblog/category_11490888.html?spm=1001.2014.3001.5482
https://blog.csdn.net/yu_cblog/category_11490888.html?spm=1001.2014.3001.5482算法专栏![]() https://blog.csdn.net/yu_cblog/category_11464817.html
https://blog.csdn.net/yu_cblog/category_11464817.html
STL源码剖析![]() https://blog.csdn.net/yu_cblog/category_11983210.html?spm=1001.2014.3001.5482
https://blog.csdn.net/yu_cblog/category_11983210.html?spm=1001.2014.3001.5482
priority_queue 优先队列
优先队列的底层实现就是数据结构的堆。其中,小顶堆可以不断更新数组里的最小值,大顶堆可以不断更新数组里的最大值,push和pop自带排序功能,经常用来解决TopK问题。
如果大家有需要数据结构堆的实现可以通过博主的传送门食用噢~
【堆】数据结构-堆的实现【超详细的数据结构教学】![]() https://blog.csdn.net/Yu_Cblog/article/details/124944614
https://blog.csdn.net/Yu_Cblog/article/details/124944614
692.前K个高频单词

看到频率,我们很自然可以想到哈希表,我们可以用哈希表记录每个单词出现的次数。看到前K个,可以断定这是一个topK问题,我们需要用到优先队列。但是,哈希表是单向的映射,因此我们还需要用到数据结构pair,这里博主自己实现了一个pair,整体代码如下:
class Pair {
public:
Pair(string e1, int e2)
:_e1(e1), _e2(e2) {}
string _e1;
int _e2;
bool operator<(const Pair& p) const
{
if (_e2 != p._e2)
return this->_e2 < p._e2;
//此时两个出现次数相等
return this->_e1 > p._e1;
}
};
struct cmp
{
bool operator()(const Pair& f1, const Pair& f2)
{
return f1 < f2;
}
};
class Solution {
private:
bool is_inArr(string s, vector<Pair>arr) {
for (int i = 0; i < arr.size(); i++) {
if (arr[i]._e1 == s)return true;
}
return false;
}
public:
vector<string> topKFrequent(vector<string>& words, int k) {
vector<string>ret;
unordered_map<string, int>hash;
for (int i = 0; i < words.size(); i++) {
++hash[words[i]];
}
vector<Pair>arr;
for (int i = 0; i < words.size(); i++) {
Pair tmp(words[i], hash[words[i]]);
if (!is_inArr(words[i], arr))
arr.push_back(tmp);
}
priority_queue<Pair, vector<Pair>, cmp>pq;
//初始化优先队列
for (int i = 0; i < arr.size(); i++) {
pq.push(arr[i]);
}
while (k--) {
Pair tmp = pq.top();
pq.pop();
ret.push_back(tmp._e1);
}
return ret;
}
};347.前K个高频元素
这题和上一题思路完全一样,这里直接给出代码:
class Pair {
public:
Pair(int e1, int e2)
:_e1(e1), _e2(e2) {}
int _e1;
int _e2;
bool operator<(const Pair& p) const
{
if (_e2 != p._e2)
return this->_e2 < p._e2;
//此时两个出现次数相等
return this->_e1 > p._e1;
}
};
struct cmp
{
bool operator()(const Pair& f1, const Pair& f2)
{
return f1 < f2;
}
};
class Solution {
private:
bool is_inArr(int s, vector<Pair>arr) {
for (int i = 0; i < arr.size(); i++) {
if (arr[i]._e1 == s)return true;
}
return false;
}
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
vector<int>ret;
unordered_map<int, int>hash;
for (int i = 0; i < nums.size(); i++) {
++hash[nums[i]];
}
vector<Pair>arr;
for (int i = 0; i < nums.size(); i++) {
Pair tmp(nums[i], hash[nums[i]]);
if (!is_inArr(nums[i], arr))
arr.push_back(tmp);
}
priority_queue<Pair, vector<Pair>, cmp>pq;
for (int i = 0; i < arr.size(); i++) {
pq.push(arr[i]);
}
while (k--) {
Pair tmp = pq.top();
pq.pop();
ret.push_back(tmp._e1);
}
return ret;
}
};295.数据流的中位数

比较容易想到的思路,用一个堆,取出中间的数:
class MedianFinder {
private:
priority_queue<int>pq;
public:
MedianFinder() {
}
void addNum(int num) {
pq.push(num);
}
double findMedian() {
priority_queue<int>pq_tmp = pq;
if (pq.size() % 2 == 0) {
for (int i = 0; i < pq.size() / 2 - 1; i++) {
pq_tmp.pop();
}
//现在接下来的两个就是要用的了
int num1 = pq_tmp.top();
pq_tmp.pop();
int num2 = pq_tmp.top();
pq_tmp.pop();
return (num1 + num2) / 2.0;
}
else {
for (int i = 0; i < pq.size() / 2; i++) {
pq_tmp.pop();
}
return pq_tmp.top();
}
}
};这个版本是无法通过的,虽然用了优先队列很大程度降低了时间复杂度,但是因为中间有拷贝过程,开销还是很大的,这样提交会超时。
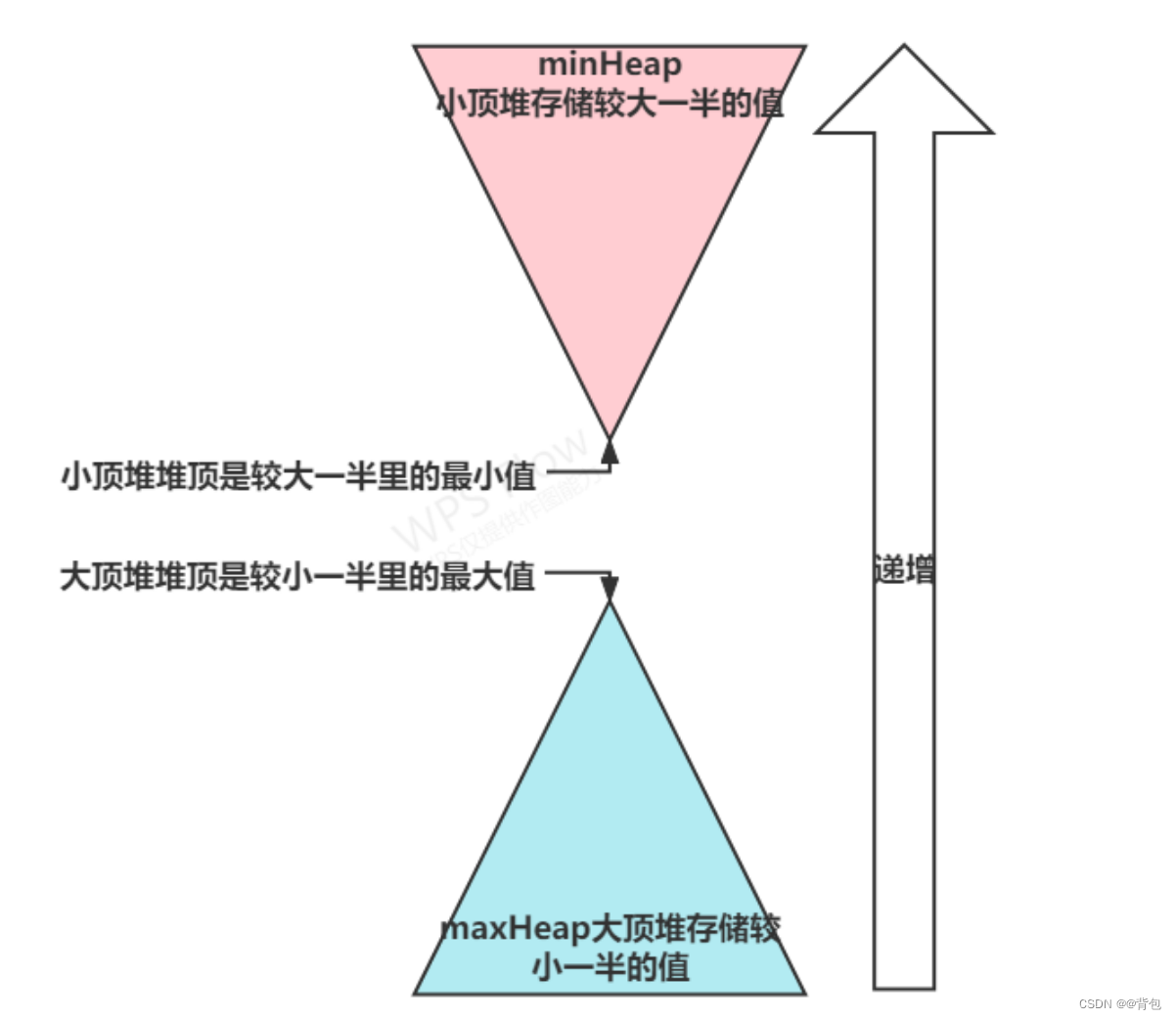
用两个优先队列实现:
直接开两个堆
queMax记录比中位数大的 -- 是个小堆 -- 可以得到queMax的最小值
queMin记录比中位数小的 -- 是个大堆 -- 可以得到queMin的最大值
插入过程中保证 -- queMin的大小和queMax一样 或者queMin大小比queMax大小大1
如果queMin过大, 把其中最大的那个数插入到queMax中去
queMax过大同理
如果最后queMin.size()==queMax.size() 则中位数就是两个堆顶的平均
如果queMin.size()==queMax.size()+1 则中位数是queMin.top()
class MedianFinder {
public:
priority_queue<int, vector<int>, less<int>> queMin;
priority_queue<int, vector<int>, greater<int>> queMax;
MedianFinder() {}
void addNum(int num) {
if (queMin.empty() || num <= queMin.top()) {
queMin.push(num);
if (queMax.size() + 1 < queMin.size()) {
queMax.push(queMin.top());
queMin.pop();
}
}
else {
queMax.push(num);
if (queMax.size() > queMin.size()) {
queMin.push(queMax.top());
queMax.pop();
}
}
}
double findMedian() {
if (queMin.size() > queMax.size()) {
return queMin.top();
}
return (queMin.top() + queMax.top()) / 2.0;
}
};总结
看到这里 相信大家对这几道题的解题方法已经有了一定的理解了吧?如果你感觉这篇文章对你有帮助的话,希望你可以持续关注,订阅专栏,点赞收藏都是我创作的最大动力!
( 转载时请注明作者和出处。未经许可,请勿用于商业用途 )
更多文章请访问我的主页
@背包![]() https://blog.csdn.net/Yu_Cblog?type=blog
https://blog.csdn.net/Yu_Cblog?type=blog
【算法】priority_queue在力扣题中的应用 | 力扣692 | 力扣347 | 力扣295 【超详细的注释和算法解释】的更多相关文章
- 【Java面试题】15 String s="Hello"; s=s+“world!”;这两行代码执行后,原始的String对象中的内容到底变了没有?String与StringBuffer的超详细讲解!!!!!
1.Java中哪些类是不能被继承的? 不能被继承的是那些用final关键字修饰的类.一般比较基本的类型或防止扩展类无意间破坏原来方法的实现的类型都应该是final的,在java中,System,Str ...
- 在eclipse中使用git创建本地库,以及托管项目到GitHub超详细教程
关于安装git的教程,由于比较简单,并且网上教程特别多,而且即使不按照网上教程,下载好的windows版本git,安装时候一路默认设置就行. 安装好之后,在桌面上有git图标:右键菜单中有Git Ba ...
- 【经验】 Java BigInteger类以及其在算法题中的应用
[经验] Java BigInteger类以及其在算法题中的应用 标签(空格分隔): 经验 本来在刷九度的数学类型题,有进制转换和大数运算,故而用到了java BigInteger类,使用了之后才发现 ...
- Java在算法题中的输入问题
Java在算法题中的输入问题 在写算法题的时候,经常因为数据的输入问题而导致卡壳,其中最常见的就是数据输入无法结束. 1.给定范围,确定输入几个数据 直接使用普通的Scanner输入数据范围,然后使用 ...
- 前端与算法 leetcode 26. 删除排序数组中的重复项
目录 # 前端与算法 leetcode 26. 删除排序数组中的重复项 题目描述 概要 提示 解析 算法 # 前端与算法 leetcode 26. 删除排序数组中的重复项 题目描述 26. 删除排序数 ...
- 动手实现 LRU 算法,以及 Caffeine 和 Redis 中的缓存淘汰策略
我是风筝,公众号「古时的风筝」. 文章会收录在 JavaNewBee 中,更有 Java 后端知识图谱,从小白到大牛要走的路都在里面. 那天我在 LeetCode 上刷到一道 LRU 缓存机制的问题, ...
- 算法训练 Hankson的趣味题
算法训练 Hankson的趣味题 时间限制:1.0s 内存限制:64.0MB 问题描述 Hanks 博士是BT (Bio-Tech,生物技术) 领域的知名专家,他的儿子名叫Han ...
- Expm 10_2 实现Ford-Fulkerson算法,求出给定图中从源点s到汇点t的最大流,并输出最小割。
package org.xiu68.exp.exp10; import java.util.ArrayDeque; import java.util.ArrayList; import java.ut ...
- 算法笔记(c++)--c++中碰到的一些用法
算法笔记(c++)--c++中碰到的一些用法 toupper(xxx)可以变成大写; tolower(xx)小写 isalpha(xxx)判断是不是字母 isalnum(xx)判断是不是数字 abs( ...
- 在洛谷3369 Treap模板题 中发现的Splay详解
本题的Splay写法(无指针Splay超详细) 前言 首先来讲...终于调出来了55555...调了整整3天..... 看到大部分大佬都是用指针来实现的Splay.小的只是按照Splay的核心思想和原 ...
随机推荐
- 基于阿里云 Serverless 快速部署 function 的极致体验
1.Serverless 前世今生 1.1 Serverless 背景介绍 云计算的不断发展,涌现出很多改变传统IT架构和运维方式的新技术,而以虚拟机.容器.微服务为代表的技术更是在各个层面不断提升云 ...
- vue双向定位导航效果
需求:实现双向定位导航效果,点击左侧菜单,右侧滚动到相应的位置.滚动右边,左侧相应菜单高亮. html代码: 1 <ul class="EntTake_main_left" ...
- 我发现明显产品bug啦
1. 百度云在下载时,如果选中的文件过多,在点击下载后,不能即时取消所有的下载项! 如下图,点击""全部取消" 出现在列表中项全部消失,但后续新的项继续出现,仍在下载, ...
- KVM 管理工具:libvirt
libvirt 简介 libvirt 是目前使用最为广泛的对 KVM 虚拟机进行管理的工具和应用程序接口.
- 如何让golang的web服务热重载
有很多方法可以热重载 golang Web 应用程序或 golang 程序. 我选择gin(不是web gin框架)来进行热重载. 首先在 GOPATH/bin下安装gin,命令如下所示: go ge ...
- 【VSCode】秒下vscode
有时从vscode官网下载速度奇慢甚至失败,介绍一种方法可以秒下 进入官网选择要下载的版本 像我的电脑,下载网址根本打不开 修改下载网址,替换下载地址中红框字符串:vscode.cdn.azure.c ...
- Laravel - Eloquent 删除数据
public function ormDelete() { # 1.通过模型删除 // $student = Student::where('id',5 ...
- [转帖]Linux字符截取命令-cut
概述 cut是一个选取命令,.一般来说,选取信息通常是针对"行"来进行分析的,并不是整篇信息分析的. 语法 cut [-bn] [file] 1 或 cut [-c] [file] ...
- [转帖]Linux学习14-ab报错apr_pollset_poll: The timeout specified has expired (70007)
https://www.cnblogs.com/yoyoketang/p/10255100.html 前言 使用ab压力测试时候出现报错apr_pollset_poll: The timeout sp ...
- [专题]测试发现部分NVMe SSD的掉电数据保护功能让人失望
https://www.cnbeta.com/articles/tech/1240441.htm 这个有点过分了. 苹果开发者 Russ Bishop 在一份测试报告中指出:即使掉电保护已经是个绕不开 ...