LLM面面观之RLHF平替算法DPO
1. 背景
最近本qiang~老看到一些关于大语言模型的DPO、RLHF算法,但都有些云里雾里,因此静下心来收集资料、研读论文,并执行了下开源代码,以便加深印象。
此文是本qiang~针对大语言模型的DPO算法的整理,包括原理、流程及部分源码。
2. DPO vs RLHF

上图左边是RLHF算法,右边为DPO算法,两图的差异对比即可体现出DPO的改进之处。
1. RLHF算法包含奖励模型(reward model)和策略模型(policy model,也称为演员模型,actor model),基于偏好数据以及强化学习不断迭代优化策略模型的过程。
2. DPO算法不包含奖励模型和强化学习过程,直接通过偏好数据进行微调,将强化学习过程直接转换为SFT过程,因此整个训练过程简单、高效,主要的改进之处体现在于损失函数。
PS:
1. 偏好数据,可以表示为三元组(提示语prompt, 良好回答chosen, 一般回答rejected)。论文中的chosen表示为下标w(即win),rejected表示为下标l(即lose)
2. RLHF常使用PPO作为基础算法,整体流程包含了4个模型,且通常训练过程中需要针对训练的actor model进行采样,因此训练起来,稳定性、效率、效果不易控制。
1) actor model/policy model: 待训练的模型,通常是SFT训练后的模型作为初始化
2) reference model: 参考模型,也是经SFT训练后的模型进行初始化,且通常与actor model是同一个模型,且模型冻结,不参与训练,其作用是在强化学习过程中,保障actor model与reference model的分布差异不宜过大。
3) reward model: 奖励模型,用于提供每个状态或状态动作对的即时奖励信号。
4) Critic model: 作用是估计状态或状态动作对的长期价值,也称为状态值函数或动作值函数。
3. DPO算法仅包含RLHF中的两个模型,即演员模型(actor model)以及参考(reference model),且训练过程中不需要进行数据采样。
4. RLHF可以参考附件中的引文
3. DPO的损失函数

如何将RLHF的Reward model过程简化为上式,作者花了大量篇幅进行了推导,感兴趣的读者可以参考附件DPO的论文。
DPO算法的目的是最大化奖励模型(此处的奖励模型即为训练的策略),使得奖励模型对chosen和rejected数据的差值最大,进而学到人类偏好。
上式的后半部分通过对数函数运算规则,可以进行如下转化。

转化后的公式和源代码中的计算函数中的公式是一致的。
其中左半部分是训练的policy模型选择chosen优先于rejected,右半部分是冻结的reference模型选择chosen优先于rejected,二者的差值可类似于KL散度,保障actor模型的分布与reference模型的分布不会有较大的差异。
4. 微调流程
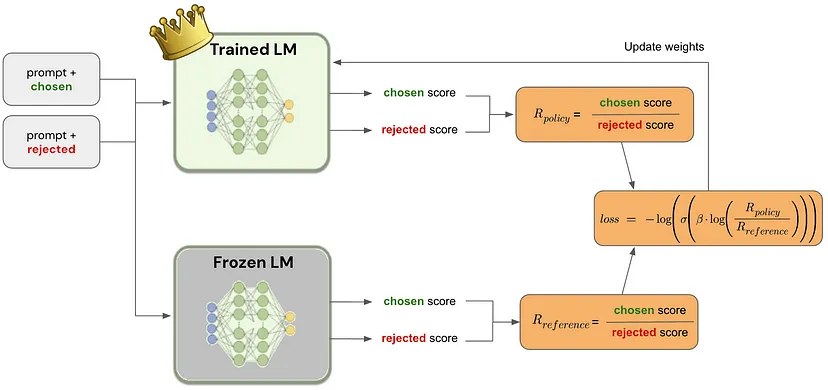
上图展示了DPO微调的大致流程,其中Trained LM即为策略模型,Frozen LM即为参考模型,二者均是先进行SFT微调得到的模型进行初始化,其中Trained LM需要进行训练,Frozen LM不参与训练。
两个模型分别针对chosen和rejected进行预测获取对应的得分,再通过DPO的损失函数进行损失计算,进而不断的迭代优化。
5. 源码
源码参考代码:https://github.com/eric-mitchell/direct-preference-optimization
5.1 DPO损失函数
1 def preference_loss(policy_chosen_logps: torch.FloatTensor,
2 policy_rejected_logps: torch.FloatTensor,
3 reference_chosen_logps: torch.FloatTensor,
4 reference_rejected_logps: torch.FloatTensor,
5 beta: float,
6 label_smoothing: float = 0.0,
7 ipo: bool = False,
8 reference_free: bool = False) -> Tuple[torch.FloatTensor, torch.FloatTensor, torch.FloatTensor]:
9 # policy_chosen_logps: 训练模型对于chosen经过log后logits
10 # policy_rejected_logps: 训练模型对于rejected经过log后logits
11 # reference_chosen_logps: 训练模型对于chosen经过log后logits
12 # reference_rejected_logps: 训练模型对于rejected经过log后logits
13 # beta: policy和reference的差异性控制参数
14
15 # actor模型选择chosen优先于rejected
16 pi_logratios = policy_chosen_logps - policy_rejected_logps
17 # reference模型选择chosen优先于rejected
18 ref_logratios = reference_chosen_logps - reference_rejected_logps
19
20 if reference_free:
21 ref_logratios = 0
22
23 # 差值可类似于KL散度,保障actor模型的分布与reference模型的分布不会有较大的差异
24 logits = pi_logratios - ref_logratios # also known as h_{\pi_\theta}^{y_w,y_l}
25
26 if ipo:
27 losses = (logits - 1/(2 * beta)) ** 2 # Eq. 17 of https://arxiv.org/pdf/2310.12036v2.pdf
28 else:
29 # Eq. 3 https://ericmitchell.ai/cdpo.pdf; label_smoothing=0 gives original DPO (Eq. 7 of https://arxiv.org/pdf/2305.18290.pdf)
30 # label_smoothing为0,对应的DPO论文的算法
31 losses = -F.logsigmoid(beta * logits) * (1 - label_smoothing) - F.logsigmoid(-beta * logits) * label_smoothing
32
33 # chosen和rejected的奖励
34 chosen_rewards = beta * (policy_chosen_logps - reference_chosen_logps).detach()
35 rejected_rewards = beta * (policy_rejected_logps - reference_rejected_logps).detach()
36
37 return losses, chosen_rewards, rejected_rewards
5.2 批次训练过程
1 def get_batch_metrics(self, batch: Dict[str, Union[List, torch.LongTensor]], loss_config: DictConfig, train=True):
2 """Compute the SFT or DPO loss and other metrics for the given batch of inputs."""
3
4 if loss_config.name in {'dpo', 'ipo'}:
5 # policy模型针对chosen和rejected进行预测
6 policy_chosen_logps, policy_rejected_logps = self.concatenated_forward(self.policy, batch)
7 with torch.no_grad():
8 # reference模型针对chosen和rejected进行预测
9 reference_chosen_logps, reference_rejected_logps = self.concatenated_forward(self.reference_model, batch)
10
11 if loss_config.name == 'dpo':
12 loss_kwargs = {'beta': loss_config.beta, 'reference_free': loss_config.reference_free, 'label_smoothing': loss_config.label_smoothing, 'ipo': False}
13 elif loss_config.name == 'ipo':
14 loss_kwargs = {'beta': loss_config.beta, 'ipo': True}
15 else:
16 raise ValueError(f'unknown loss {loss_config.name}')
17 # 损失计算
18 losses, chosen_rewards, rejected_rewards = preference_loss(
19 policy_chosen_logps, policy_rejected_logps, reference_chosen_logps, reference_rejected_logps, **loss_kwargs)
20
21 reward_accuracies = (chosen_rewards > rejected_rewards).float()
22
23 elif loss_config.name == 'sft':
24 policy_chosen_logits = self.policy(batch['chosen_input_ids'], attention_mask=batch['chosen_attention_mask']).logits.to(torch.float32)
25 policy_chosen_logps = _get_batch_logps(policy_chosen_logits, batch['chosen_labels'], average_log_prob=False)
26
27 losses = -policy_chosen_logps
28
29 return losses.mean()
5.3 LM的交叉熵计算
1 def _get_batch_logps(logits: torch.FloatTensor, labels: torch.LongTensor, average_log_prob: bool = False) -> torch.FloatTensor:
2 # 经模型后的logits进行批量计算logps
3
4 assert logits.shape[:-1] == labels.shape
5
6 # 基于先前的token预测下一个token
7 labels = labels[:, 1:].clone()
8 logits = logits[:, :-1, :]
9 loss_mask = (labels != -100)
10
11 # dummy token; we'll ignore the losses on these tokens later
12 labels[labels == -100] = 0
13
14 # 交叉熵函数
15 per_token_logps = torch.gather(logits.log_softmax(-1), dim=2, index=labels.unsqueeze(2)).squeeze(2)
16
17 if average_log_prob:
18 return (per_token_logps * loss_mask).sum(-1) / loss_mask.sum(-1)
19 else:
20 return (per_token_logps * loss_mask).sum(-1)
5.4 其他注意
1. hugging face设置代理
源码会从hugging face中下载英文语料和模型,由于网络限制,因此设置代理映射,将HF_ENDPOINT设置为https://hf-mirror.com,即设置: os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
2. 如果仅想要熟悉DPO整体流程,可以下载较小的生成式模型,如BLOOM 560M,GPT2等
6. 总结
一句话足矣~
本文主要针对大语言模型的DPO算法的整理,包括原理、流程及部分源码。
此外,建议大家可以针对源码进行运行,源码的欢迎大家一块交流。
7. 参考
(1) RLHF:https://blog.csdn.net/v_JULY_v/article/details/128579457
(2) DPO论文: https://arxiv.org/pdf/2305.18290v2.pdf
(3) DPO代码: https://github.com/eric-mitchell/direct-preference-optimization
(4) DPO理解1:https://medium.com/@joaolages/direct-preference-optimization-dpo-622fc1f18707
(5) DPO理解2: https://zhuanlan.zhihu.com/p/669825918

LLM面面观之RLHF平替算法DPO的更多相关文章
- [C++] 配平化学方程式算法的封装
有人已经实现了配平的方法,在此不再重复介绍. https://www.cnblogs.com/Elfish/p/7631603.html 但是,上述的方法所提供的代码还是存在着问题,需要进一步修改. ...
- 自制-随机生成不重复的数组 --算法,egret平台下的TS code
感觉这个算法经常会用到,前段时间写过一次,现在push出来.原理是有两个数组,一个数组存放随机数,然后从另一个数组提取相关的数,然后把另一个数组的大小-1,remove掉这个数,unity里也是这个原 ...
- 南洋理工 OJ 115 城市平乱 dijstra算法
城市平乱 时间限制:1000 ms | 内存限制:65535 KB 难度:4 描述 南将军统领着N个部队,这N个部队分别驻扎在N个不同的城市. 他在用这N个部队维护着M个城市的治安,这M个城市 ...
- nyoj-115-城市平乱(dijkstra算法)
题目链接 /* Name:nyoj-115-城市平乱 Copyright: Author: Date: 2018/4/25 17:28:06 Description: dijkstra模板题 枚举从 ...
- ChatGPT 背后的“功臣”——RLHF 技术详解
OpenAI 推出的 ChatGPT 对话模型掀起了新的 AI 热潮,它面对多种多样的问题对答如流,似乎已经打破了机器和人的边界.这一工作的背后是大型语言模型 (Large Language Mode ...
- 在一张 24 GB 的消费级显卡上用 RLHF 微调 20B LLMs
我们很高兴正式发布 trl 与 peft 的集成,使任何人都可以更轻松地使用强化学习进行大型语言模型 (LLM) 微调!在这篇文章中,我们解释了为什么这是现有微调方法的有竞争力的替代方案. 请注意, ...
- 【Machine Learning】KNN算法虹膜图片识别
K-近邻算法虹膜图片识别实战 作者:白宁超 2017年1月3日18:26:33 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- 高频交易算法研发心得--MACD指标算法及应用
凤鸾宝帐景非常,尽是泥金巧样妆. 曲曲远山飞翠色:翩翩舞袖映霞裳. 梨花带雨争娇艳:芍药笼烟骋媚妆. 但得妖娆能举动,取回长乐侍君王. [摘自<封神演义>纣王在女娲宫上香时题的诗] 一首定 ...
- 【原创】机器学习之PageRank算法应用与C#实现(2)球队排名应用与C#代码
在上一篇文章:机器学习之PageRank算法应用与C#实现(1)算法介绍 中,对PageRank算法的原理和过程进行了详细的介绍,并通过一个很简单的例子对过程进行了讲解.从上一篇文章可以很快的了解Pa ...
- 【原创】机器学习之PageRank算法应用与C#实现(1)算法介绍
考虑到知识的复杂性,连续性,将本算法及应用分为3篇文章,请关注,将在本月逐步发表. 1.机器学习之PageRank算法应用与C#实现(1)算法介绍 2.机器学习之PageRank算法应用与C#实现(2 ...
随机推荐
- C++17 更通用的 union:variant
References 现代C++学习--实现多类型存储std::variant 如何优雅的使用 std::variant 与 std::optional std::variant 是 C++17 中, ...
- Codeforces Round #738 (Div. 2) (A~E)
比赛链接:Here 1559A. Mocha and Math 题意: 给定一个区间,选择区间内的值执行 & 操作使得区间最大值最小化 观察样例发现:令 x = (1 << 30) ...
- SCA 技术进阶系列(二):代码同源检测技术在供应链安全治理中的应用
直击痛点:为什么需要同源检测 随着 "数字中国" 建设的不断提速,企业在数字化转型的创新实践中不断加大对开源技术的应用,引入开源组件完成应用需求开发已经成为了大多数研发工程师开发软 ...
- vue <a>标签 href 是参数的情况下如何使用
想在页面中使用a标签打开一个新页面进行跳转 例如:msgZi.blogAddress 的值是 https://www.baidu.com 正确的写法: <a :href="goBlog ...
- 2020年了,再不会webpack敲得代码就不香了(近万字实战)
https://zhuanlan.zhihu.com/p/99959392?utm_source=wechat_session&utm_medium=social&utm_oi=619 ...
- C++大整数类
用法 把头文件和源代码文件放在同一目录下,然后#include"INT"即可使用.你能对int类的变量进行a=2,a+=3,a%8,a--等等操作,那你就也能对INT进行.INT基 ...
- JVM 内存模型及特点总结
本文为博主原创,未经允许不得转载: JVM 内存区域主要分为线程私有区域[程序计数器.虚拟机栈.本地方法区].线程共享区域[JAVA 堆.方法区].直接内存. 线程私有数据区域生命周期与线程相同, 依 ...
- css - 伪元素清除浮动
.clearfix:after{ content:""; /*设置内容为空*/ height:0; /*高度为0*/ line-height:0; /*行高为0*/ display ...
- SpringBoot02:运行原理初探
@EnableAutoConfiguration @EnableAutoConfiguration:开启自动配置功能 以前我们需要自己配置的东西,而现在SpringBoot可以自动帮我们配置 @Ena ...
- [转帖]【终端使用】"usermod"命令 和 组(包括:主组、附加组)
"usermod"命令,可以用来设置用户账户的 主组.附加组.登录使用的Shell. 命令 作用 usermod -g 组名 用户名 修改用户的主组(gid) usermod ...