异源数据同步 → DataX 为什么要支持 kafka?
开心一刻
昨天发了一条朋友圈:酒吧有什么好去的,上个月在酒吧当服务员兼职,一位大姐看上了我,说一个月给我 10 万,要我陪她去上海,我没同意
朋友评论道:你没同意,为什么在上海?
我回复到:上个月没同意

前情回顾
关于 DataX,官网有很详细的介绍,鄙人不才,也写过几篇文章
不了解的小伙伴可以按需去查看,所以了,DataX 就不做过多介绍了;官方提供了非常多的插件,囊括了绝大部分的数据源,基本可以满足我们日常需要,但数据源种类太多,DataX 插件不可能包含全部,比如 kafka,DataX 官方是没有提供读写插件的,大家知道为什么吗?你们如果对数据同步了解的比较多的话,一看到 kafka,第一反应往往想到的是 实时同步,而 DataX 针对的是 离线同步,所以 DataX 官方没提供 kafka 插件是不是也就能理解了?因为不合适嘛!
但如果客户非要离线同步也支持 kafka

你能怎么办?直接怼过去:实现不了?
所以没得选,那就只能给 DataX 开发一套 kafka 插件了;基于 DataX插件开发宝典,插件开发起来还是非常简单的
kafkawriter
编程接口
自定义
Kafkawriter继承 DataX 的Writer,实现 job、task 对应的接口即可/**
* @author 青石路
*/
public class KafkaWriter extends Writer { public static class Job extends Writer.Job { private Configuration conf = null; @Override
public List<Configuration> split(int mandatoryNumber) {
List<Configuration> configurations = new ArrayList<Configuration>(mandatoryNumber);
for (int i = 0; i < mandatoryNumber; i++) {
configurations.add(this.conf.clone());
}
return configurations;
} private void validateParameter() {
this.conf.getNecessaryValue(Key.BOOTSTRAP_SERVERS, KafkaWriterErrorCode.REQUIRED_VALUE);
this.conf.getNecessaryValue(Key.TOPIC, KafkaWriterErrorCode.REQUIRED_VALUE);
} @Override
public void init() {
this.conf = super.getPluginJobConf();
this.validateParameter();
} @Override
public void destroy() { }
} public static class Task extends Writer.Task {
private static final Logger logger = LoggerFactory.getLogger(Task.class);
private static final String NEWLINE_FLAG = System.getProperty("line.separator", "\n"); private Producer<String, String> producer;
private Configuration conf;
private Properties props;
private String fieldDelimiter;
private List<String> columns;
private String writeType; @Override
public void init() {
this.conf = super.getPluginJobConf();
fieldDelimiter = conf.getUnnecessaryValue(Key.FIELD_DELIMITER, "\t", null);
columns = conf.getList(Key.COLUMN, String.class);
writeType = conf.getUnnecessaryValue(Key.WRITE_TYPE, WriteType.TEXT.name(), null);
if (CollUtil.isEmpty(columns)) {
throw DataXException.asDataXException(KafkaWriterErrorCode.REQUIRED_VALUE,
String.format("您提供配置文件有误,[%s]是必填参数,不允许为空或者留白 .", Key.COLUMN));
} props = new Properties();
props.put(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, conf.getString(Key.BOOTSTRAP_SERVERS));
//这意味着leader需要等待所有备份都成功写入日志,这种策略会保证只要有一个备份存活就不会丢失数据。这是最强的保证。
props.put(ProducerConfig.ACKS_CONFIG, conf.getUnnecessaryValue(Key.ACK, "0", null));
props.put(CommonClientConfigs.RETRIES_CONFIG, conf.getUnnecessaryValue(Key.RETRIES, "0", null));
props.put(ProducerConfig.BATCH_SIZE_CONFIG, conf.getUnnecessaryValue(Key.BATCH_SIZE, "16384", null));
props.put(ProducerConfig.LINGER_MS_CONFIG, 1);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, conf.getUnnecessaryValue(Key.KEY_SERIALIZER, "org.apache.kafka.common.serialization.StringSerializer", null));
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, conf.getUnnecessaryValue(Key.VALUE_SERIALIZER, "org.apache.kafka.common.serialization.StringSerializer", null)); Configuration saslConf = conf.getConfiguration(Key.SASL);
if (ObjUtil.isNotNull(saslConf)) {
logger.info("配置启用了SASL认证");
props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, saslConf.getNecessaryValue(Key.SASL_SECURITY_PROTOCOL, KafkaWriterErrorCode.REQUIRED_VALUE));
props.put(SaslConfigs.SASL_MECHANISM, saslConf.getNecessaryValue(Key.SASL_MECHANISM, KafkaWriterErrorCode.REQUIRED_VALUE));
String userName = saslConf.getNecessaryValue(Key.SASL_USERNAME, KafkaWriterErrorCode.REQUIRED_VALUE);
String password = saslConf.getNecessaryValue(Key.SASL_PASSWORD, KafkaWriterErrorCode.REQUIRED_VALUE);
props.put(SaslConfigs.SASL_JAAS_CONFIG, String.format("org.apache.kafka.common.security.plain.PlainLoginModule required username=\"%s\" password=\"%s\";", userName, password));
} producer = new KafkaProducer<String, String>(props);
} @Override
public void prepare() {
if (Boolean.parseBoolean(conf.getUnnecessaryValue(Key.NO_TOPIC_CREATE, "false", null))) { ListTopicsResult topicsResult = AdminClient.create(props).listTopics();
String topic = conf.getNecessaryValue(Key.TOPIC, KafkaWriterErrorCode.REQUIRED_VALUE); try {
if (!topicsResult.names().get().contains(topic)) {
new NewTopic(
topic,
Integer.parseInt(conf.getUnnecessaryValue(Key.TOPIC_NUM_PARTITION, "1", null)),
Short.parseShort(conf.getUnnecessaryValue(Key.TOPIC_REPLICATION_FACTOR, "1", null))
);
List<NewTopic> newTopics = new ArrayList<NewTopic>();
AdminClient.create(props).createTopics(newTopics);
}
} catch (Exception e) {
throw new DataXException(KafkaWriterErrorCode.CREATE_TOPIC, KafkaWriterErrorCode.REQUIRED_VALUE.getDescription());
}
}
} @Override
public void startWrite(RecordReceiver lineReceiver) {
logger.info("start to writer kafka");
Record record = null;
while ((record = lineReceiver.getFromReader()) != null) {//说明还在读取数据,或者读取的数据没处理完
//获取一行数据,按照指定分隔符 拼成字符串 发送出去
if (writeType.equalsIgnoreCase(WriteType.TEXT.name())) {
producer.send(new ProducerRecord<String, String>(this.conf.getString(Key.TOPIC),
recordToString(record),
recordToString(record))
);
} else if (writeType.equalsIgnoreCase(WriteType.JSON.name())) {
producer.send(new ProducerRecord<String, String>(this.conf.getString(Key.TOPIC),
recordToString(record),
recordToKafkaJson(record))
);
}
producer.flush();
}
} @Override
public void destroy() {
logger.info("producer close");
if (producer != null) {
producer.close();
}
} /**
* 数据格式化
*
* @param record
* @return
*/
private String recordToString(Record record) {
int recordLength = record.getColumnNumber();
if (0 == recordLength) {
return NEWLINE_FLAG;
}
Column column;
StringBuilder sb = new StringBuilder();
for (int i = 0; i < recordLength; i++) {
column = record.getColumn(i);
sb.append(column.asString()).append(fieldDelimiter);
} sb.setLength(sb.length() - 1);
sb.append(NEWLINE_FLAG); return sb.toString();
} private String recordToKafkaJson(Record record) {
int recordLength = record.getColumnNumber();
if (recordLength != columns.size()) {
throw DataXException.asDataXException(KafkaWriterErrorCode.ILLEGAL_PARAM,
String.format("您提供配置文件有误,列数不匹配[record columns=%d, writer columns=%d]", recordLength, columns.size()));
}
List<KafkaColumn> kafkaColumns = new ArrayList<>();
for (int i = 0; i < recordLength; i++) {
KafkaColumn column = new KafkaColumn(record.getColumn(i), columns.get(i));
kafkaColumns.add(column);
}
return JSONUtil.toJsonStr(kafkaColumns);
}
}
}
DataX 框架按照如下的顺序执行 Job 和 Task 的接口
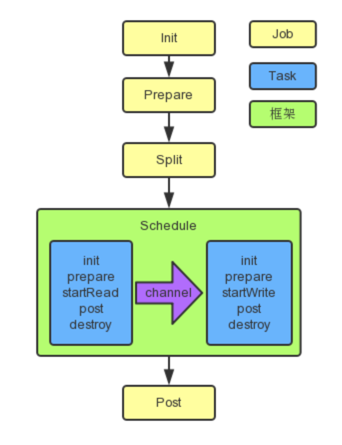
重点看 Task 的接口实现
init:读取配置项,然后创建 Producer 实例
prepare:判断 Topic 是否存在,不存在则创建
startWrite:通过 RecordReceiver 从 Channel 获取 Record,然后写入 Topic
支持两种写入格式:
text、json,细节请看下文中的kafkawriter.mddestroy:关闭 Producer 实例
实现不难,相信大家都能看懂
插件定义
在
resources下新增plugin.json{
"name": "kafkawriter",
"class": "com.qsl.datax.plugin.writer.kafkawriter.KafkaWriter",
"description": "write data to kafka",
"developer": "qsl"
}
强调下
class,是KafkaWriter的全限定类名,如果你们没有完全拷贝我的,那么要改成你们自己的配置文件
在
resources下新增plugin_job_template.json{
"name": "kafkawriter",
"parameter": {
"bootstrapServers": "",
"topic": "",
"ack": "all",
"batchSize": 1000,
"retries": 0,
"fieldDelimiter": ",",
"writeType": "json",
"column": [
"const_id",
"const_field",
"const_field_value"
],
"sasl": {
"securityProtocol": "SASL_PLAINTEXT",
"mechanism": "PLAIN",
"username": "",
"password": ""
}
}
}
配置项说明:kafkawriter.md
打包发布
可以参考官方的
assembly配置,利用 assembly 来打包
至此,kafkawriter 就算完成了
kafkareader
编程接口
自定义
Kafkareader继承 DataX 的Reader,实现 job、task 对应的接口即可/**
* @author 青石路
*/
public class KafkaReader extends Reader { public static class Job extends Reader.Job { private Configuration originalConfig = null; @Override
public void init() {
this.originalConfig = super.getPluginJobConf();
this.validateParameter();
} @Override
public void destroy() { } @Override
public List<Configuration> split(int adviceNumber) {
List<Configuration> configurations = new ArrayList<>(adviceNumber);
for (int i=0; i<adviceNumber; i++) {
configurations.add(this.originalConfig.clone());
}
return configurations;
} private void validateParameter() {
this.originalConfig.getNecessaryValue(Key.BOOTSTRAP_SERVERS, KafkaReaderErrorCode.REQUIRED_VALUE);
this.originalConfig.getNecessaryValue(Key.TOPIC, KafkaReaderErrorCode.REQUIRED_VALUE);
}
} public static class Task extends Reader.Task { private static final Logger logger = LoggerFactory.getLogger(Task.class); private Consumer<String, String> consumer;
private String topic;
private Configuration conf;
private int maxPollRecords;
private String fieldDelimiter;
private String readType;
private List<Column.Type> columnTypes; @Override
public void destroy() {
logger.info("consumer close");
if (Objects.nonNull(consumer)) {
consumer.close();
}
} @Override
public void init() {
this.conf = super.getPluginJobConf();
this.topic = conf.getString(Key.TOPIC);
this.maxPollRecords = conf.getInt(Key.MAX_POLL_RECORDS, 500);
fieldDelimiter = conf.getUnnecessaryValue(Key.FIELD_DELIMITER, "\t", null);
readType = conf.getUnnecessaryValue(Key.READ_TYPE, ReadType.JSON.name(), null);
if (!ReadType.JSON.name().equalsIgnoreCase(readType)
&& !ReadType.TEXT.name().equalsIgnoreCase(readType)) {
throw DataXException.asDataXException(KafkaReaderErrorCode.REQUIRED_VALUE,
String.format("您提供配置文件有误,不支持的readType[%s]", readType));
}
if (ReadType.JSON.name().equalsIgnoreCase(readType)) {
List<String> columnTypeList = conf.getList(Key.COLUMN_TYPE, String.class);
if (CollUtil.isEmpty(columnTypeList)) {
throw DataXException.asDataXException(KafkaReaderErrorCode.REQUIRED_VALUE,
String.format("您提供配置文件有误,readType是JSON时[%s]是必填参数,不允许为空或者留白 .", Key.COLUMN_TYPE));
}
convertColumnType(columnTypeList);
}
Properties props = new Properties();
props.put(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, conf.getString(Key.BOOTSTRAP_SERVERS));
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, conf.getUnnecessaryValue(Key.KEY_DESERIALIZER, "org.apache.kafka.common.serialization.StringDeserializer", null));
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, conf.getUnnecessaryValue(Key.VALUE_DESERIALIZER, "org.apache.kafka.common.serialization.StringDeserializer", null));
props.put(ConsumerConfig.GROUP_ID_CONFIG, conf.getNecessaryValue(Key.GROUP_ID, KafkaReaderErrorCode.REQUIRED_VALUE));
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, maxPollRecords);
Configuration saslConf = conf.getConfiguration(Key.SASL);
if (ObjUtil.isNotNull(saslConf)) {
logger.info("配置启用了SASL认证");
props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, saslConf.getNecessaryValue(Key.SASL_SECURITY_PROTOCOL, KafkaReaderErrorCode.REQUIRED_VALUE));
props.put(SaslConfigs.SASL_MECHANISM, saslConf.getNecessaryValue(Key.SASL_MECHANISM, KafkaReaderErrorCode.REQUIRED_VALUE));
String userName = saslConf.getNecessaryValue(Key.SASL_USERNAME, KafkaReaderErrorCode.REQUIRED_VALUE);
String password = saslConf.getNecessaryValue(Key.SASL_PASSWORD, KafkaReaderErrorCode.REQUIRED_VALUE);
props.put(SaslConfigs.SASL_JAAS_CONFIG, String.format("org.apache.kafka.common.security.plain.PlainLoginModule required username=\"%s\" password=\"%s\";", userName, password));
}
consumer = new KafkaConsumer<>(props);
} @Override
public void startRead(RecordSender recordSender) {
consumer.subscribe(CollUtil.newArrayList(topic));
int pollTimeoutMs = conf.getInt(Key.POLL_TIMEOUT_MS, 1000);
int retries = conf.getInt(Key.RETRIES, 5);
if (retries < 0) {
logger.info("joinGroupSuccessRetries 配置有误[{}], 重置成默认值[5]", retries);
retries = 5;
}
/**
* consumer 每次都是新创建,第一次poll时会重新加入消费者组,加入过程会进行Rebalance,而 Rebalance 会导致同一 Group 内的所有消费者都不能工作
* 所以 poll 拉取的过程中,即使topic中有数据也不一定能拉到,因为 consumer 正在加入消费者组中
* kafka-clients 没有对应的API、事件机制来知道 consumer 成功加入消费者组的确切时间
* 故增加重试
*/
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(pollTimeoutMs));
int i = 0;
if (CollUtil.isEmpty(records)) {
for (; i < retries; i++) {
records = consumer.poll(Duration.ofMillis(pollTimeoutMs));
logger.info("第 {} 次重试,获取消息记录数[{}]", i + 1, records.count());
if (!CollUtil.isEmpty(records)) {
break;
}
}
}
if (i >= retries) {
logger.info("重试 {} 次后,仍未获取到消息,请确认是否有数据、配置是否正确", retries);
return;
}
transferRecord(recordSender, records);
do {
records = consumer.poll(Duration.ofMillis(pollTimeoutMs));
transferRecord(recordSender, records);
} while (!CollUtil.isEmpty(records) && records.count() >= maxPollRecords);
} private void transferRecord(RecordSender recordSender, ConsumerRecords<String, String> records) {
if (CollUtil.isEmpty(records)) {
return;
}
for (ConsumerRecord<String, String> record : records) {
Record sendRecord = recordSender.createRecord();
String msgValue = record.value();
if (ReadType.JSON.name().equalsIgnoreCase(readType)) {
transportJsonToRecord(sendRecord, msgValue);
} else if (ReadType.TEXT.name().equalsIgnoreCase(readType)) {
// readType = text,全当字符串类型处理
String[] columnValues = msgValue.split(fieldDelimiter);
for (String columnValue : columnValues) {
sendRecord.addColumn(new StringColumn(columnValue));
}
}
recordSender.sendToWriter(sendRecord);
}
consumer.commitAsync();
} private void convertColumnType(List<String> columnTypeList) {
columnTypes = new ArrayList<>();
for (String columnType : columnTypeList) {
switch (columnType.toUpperCase()) {
case "STRING":
columnTypes.add(Column.Type.STRING);
break;
case "LONG":
columnTypes.add(Column.Type.LONG);
break;
case "DOUBLE":
columnTypes.add(Column.Type.DOUBLE);
case "DATE":
columnTypes.add(Column.Type.DATE);
break;
case "BOOLEAN":
columnTypes.add(Column.Type.BOOL);
break;
case "BYTES":
columnTypes.add(Column.Type.BYTES);
break;
default:
throw DataXException.asDataXException(KafkaReaderErrorCode.ILLEGAL_PARAM,
String.format("您提供的配置文件有误,datax不支持数据类型[%s]", columnType));
}
}
} private void transportJsonToRecord(Record sendRecord, String msgValue) {
List<KafkaColumn> kafkaColumns = JSONUtil.toList(msgValue, KafkaColumn.class);
if (columnTypes.size() != kafkaColumns.size()) {
throw DataXException.asDataXException(KafkaReaderErrorCode.ILLEGAL_PARAM,
String.format("您提供的配置文件有误,readType是JSON时[%s列数=%d]与[json列数=%d]的数量不匹配", Key.COLUMN_TYPE, columnTypes.size(), kafkaColumns.size()));
}
for (int i=0; i<columnTypes.size(); i++) {
KafkaColumn kafkaColumn = kafkaColumns.get(i);
switch (columnTypes.get(i)) {
case STRING:
sendRecord.setColumn(i, new StringColumn(kafkaColumn.getColumnValue()));
break;
case LONG:
sendRecord.setColumn(i, new LongColumn(kafkaColumn.getColumnValue()));
break;
case DOUBLE:
sendRecord.setColumn(i, new DoubleColumn(kafkaColumn.getColumnValue()));
break;
case DATE:
// 暂只支持时间戳
sendRecord.setColumn(i, new DateColumn(Long.parseLong(kafkaColumn.getColumnValue())));
break;
case BOOL:
sendRecord.setColumn(i, new BoolColumn(kafkaColumn.getColumnValue()));
break;
case BYTES:
sendRecord.setColumn(i, new BytesColumn(kafkaColumn.getColumnValue().getBytes(StandardCharsets.UTF_8)));
break;
default:
throw DataXException.asDataXException(KafkaReaderErrorCode.ILLEGAL_PARAM,
String.format("您提供的配置文件有误,datax不支持数据类型[%s]", columnTypes.get(i)));
}
}
}
}
}
重点看 Task 的接口实现
init:读取配置项,然后创建 Consumer 实例
startWrite:从 Topic 拉取数据,通过 RecordSender 写入到 Channel 中
这里有几个细节需要注意下
- Consumer 每次都是新创建的,拉取数据的时候,如果消费者还未加入到指定的消费者组中,那么它会先加入到消费者组中,加入过程会进行 Rebalance,而 Rebalance 会导致同一消费者组内的所有消费者都不能工作,此时即使 Topic 中有可拉取的消息,也拉取不到消息,所以引入了重试机制来尽量保证那一次同步任务拉取的时候,消费者能正常拉取消息
- 一旦 Consumer 拉取到消息,则会循环拉取消息,如果某一次的拉取数据量小于最大拉取量(maxPollRecords),说明 Topic 中的消息已经被拉取完了,那么循环终止;这与常规使用(Consumer 会一直主动拉取或被动接收)是有差别的
- 支持两种读取格式:
text、json,细节请看下文的配置文件说明 - 为了保证写入 Channel 数据的完整,需要配置列的数据类型(DataX 的数据类型)
destroy:
关闭 Consumer 实例
插件定义
在
resources下新增plugin.json{
"name": "kafkareader",
"class": "com.qsl.datax.plugin.reader.kafkareader.KafkaReader",
"description": "read data from kafka",
"developer": "qsl"
}
class是KafkaReader的全限定类名配置文件
在
resources下新增plugin_job_template.json{
"name": "kafkareader",
"parameter": {
"bootstrapServers": "",
"topic": "test-kafka",
"groupId": "test1",
"writeType": "json",
"pollTimeoutMs": 2000,
"columnType": [
"LONG",
"STRING",
"STRING"
],
"sasl": {
"securityProtocol": "SASL_PLAINTEXT",
"mechanism": "PLAIN",
"username": "",
"password": "2"
}
}
}
配置项说明:kafkareader.md
打包发布
可以参考官方的
assembly配置,利用 assembly 来打包
至此,kafkareader 也完成了
总结
- 完整代码:qsl-datax
- kafkareader 重试机制只能降低拉取不到数据的概率,并不能杜绝;另外,如果上游一直往 Topic 中发消息,kafkareader 每次拉取的数据量都等于最大拉取量,那么同步任务会一直进行而不会停止,这还是离线同步吗?
- 离线同步,不推荐走 kafka,因为用 kafka 走实时同步更香
异源数据同步 → DataX 为什么要支持 kafka?的更多相关文章
- 数据同步DataX
数据同步那些事儿(优化过程分享) 简介 很久之前就想写这篇文章了,主要是介绍一下我做数据同步的过程中遇到的一些有意思的内容,和提升效率的过程. 当前在数据处理的过程中,数据同步如同血液一般充满全过 ...
- 数据同步Datax与Datax_web的部署以及使用说明
一.DataX3.0概述 DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).HDFS.Hive.ODPS.HBase.FTP等各种异构数据源之间稳定高 ...
- 总结:基于Oracle Logminer数据同步
第 1 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan LogMiner 配置使用手册 1 Logminer 简介 1.1 LogMin ...
- 数据同步工具Sqoop和DataX
在日常大数据生产环境中,经常会有集群数据集和关系型数据库互相转换的需求,在需求选择的初期解决问题的方法----数据同步工具就应运而生了.此次我们选择两款生产环境常用的数据同步工具进行讨论 Sqoop ...
- Spark记录-阿里巴巴开源工具DataX数据同步工具使用
1.官网下载 下载地址:https://github.com/alibaba/DataX DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL.Oracle.SqlSe ...
- 基于datax的数据同步平台
一.需求 由于公司各个部门对业务数据的需求,比如进行数据分析.报表展示等等,且公司没有相应的系统.数据仓库满足这些需求,最原始的办法就是把数据提取出来生成excel表发给各个部门,这个功能已经由脚本转 ...
- 环境篇:数据同步工具DataX
环境篇:数据同步工具DataX 1 概述 https://github.com/alibaba/DataX DataX是什么? DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 ...
- canal+mysql+kafka实时数据同步安装、配置
canal+mysql+kafka安装配置 概述 简介 canal译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费. 基于日志增量订阅和消费的业务包括 数 ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第三篇:logstash_output_kafka:Mysql同步Kafka深入详解
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484411&idx=1&sn=1f5a371 ...
- 比Sqoop功能更加强大开源数据同步工具DataX实战
@ 目录 概述 定义 与Sqoop对比 框架设计 支持插件 核心架构 核心优势 部署 基础环境 安装 从stream读取数据并打印到控制台 读取MySQL写入HDFS 读取HDFS写入MySQL 执行 ...
随机推荐
- 3568F-Linux应用开发手册
- 全志A40i+Logos FPGA开发板(4核ARM Cortex-A7)硬件说明书(下)
前 言 本文档主要介绍板卡硬件接口资源以及设计注意事项等内容,测试板卡为创龙科技旗下的全志A40i+Logos FPGA开发板. 核心板的ARM端和FPGA端的IO电平标准一般为3.3V,上拉电源一般 ...
- vba--将excel单元格格式改为常规格式
Sub 改格式() ActiveWorkbook.activesheet.Select For Each Rng In ActiveSheet.UsedRange With Rng .NumberFo ...
- MerkleTree in BTC
Merkle 树是一种用于高效且安全地验证大数据结构完整性和一致性的哈希树.它在比特币网络中起到至关重要的作用.Merkle 树是一种二叉树结构,其中每个叶子节点包含数据块的哈希值,每个非叶子节点包含 ...
- Ubuntu 查看用户历史记录
Ubuntu 查看用户历史记录 1. 查看用户命令行历史记录 1. 查看当前登录账号所属用户的历史命令行记录 打开命令行,输入 history 就会看到当前登录账号所属用户的历史记录 2. 查看系统所 ...
- hive、hbase、clickhouse
hive相当于贝利,是计算处理数据的鼻祖,hbase相当于梅西,继承了hive(贝利)的意志,但是因为现代足球的发展,梅西整体水平要强于贝利的远古踢法(mapreduce),然后clickhouse相 ...
- Linux服务器从头配置
安装配置jdk 下载 jdk jdk-8u171-linux-x64.tar.gz 将该压缩包放到/usr/local/jdk目录下然后解压(jdk目录需要自己手动创建) tar zxvf jdk-8 ...
- PixiJS源码分析系列: 第一章 从最简单的例子入手
从最简单的例子入手分析 PixiJS 源码 我一般是以使用角度作为切入点查看分析源码,例子中用到什么类,什么方法,再入源码. 高屋建瓴的角度咱也做不到啊,毕竟水平有限 pixijs 的源码之前折腾了半 ...
- TIER 0: Fawn
FTP FTP(File Transfer Protocol)是一种用于在网络上进行文件传输的协议和相应的工具 RFC 959 文档:是定义了 FTP 协议的规范 FTP 使用两个不同的端口 TCP/ ...
- Prometheus 基于Python Django实现Prometheus Exporter
基于Python Django实现Prometheus Exporter 需求描述 运行监控需求,需要采集Nginx 每个URL请求的相关信息,涉及两个指标:一分钟内平均响应时间,调用次数,并且为每个 ...