suffix array后缀数组
倍增算法
基本定义子串:字符串 S 的子串 r[i..j],i≤j,表示 r 串中从 i 到 j 这一段
也就是顺次排列 r[i],r[i+1],...,r[j]形成的字符串。
后缀:后缀是指从某个位置 i 开始到整个串末尾结束的一个特殊子串。
字串 r 的 从 第 i 个 字 符 开 始 的 后 缀 表 示 为 Suffix(i) , 也 就 是
Suffix(i)=r[i..len(r)]。
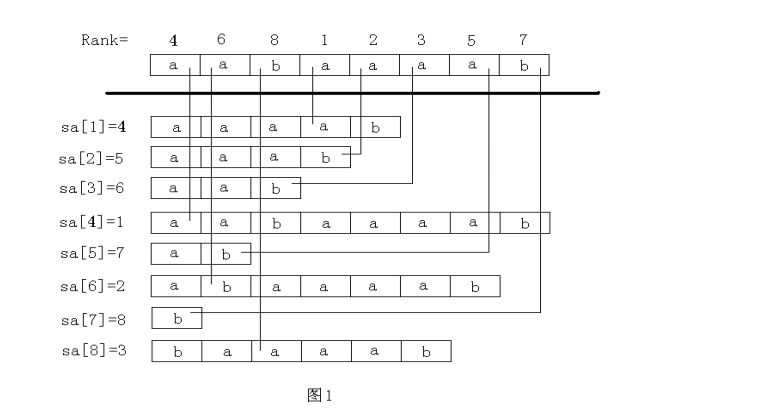
后缀数组:后缀数组 SA 是一个一维数组,它保存 1..n 的某个排列 SA[1],
SA[2],……,SA[n],并且保证 Suffix(SA[i]) < Suffix(SA[i+1]),1≤i<n。
也就是将 S 的 n 个后缀从小到大进行排序之后把排好序的后缀的开头位置顺
次放入 SA 中。
名次数组:名次数组 Rank[i]保存的是 Suffix(i)在所有后缀中从小到大排
列的“名次”。
简单的说,后缀数组是“排第几的是谁?”,名次数组是“你排第几?”。容
易看出,后缀数组和名次数组为互逆运算。如图 1 所示。
设字符串的长度为 n。为了方便比较大小,可以在字符串后面添加一个字符,
这个字符没有在前面的字符中出现过,而且比前面的字符都要小。在求出名次数
组后,可以仅用 O(1)的时间比较任意两个后缀的大小。在求出后缀数组或名次
数组中的其中一个以后,便可以用 O(n)的时间求出另外一个。任意两个后缀如
果直接比较大小,最多需要比较字符 n 次,也就是说最迟在比较第 n 个字符时一
定能分出“胜负”。
1.2 倍增算法
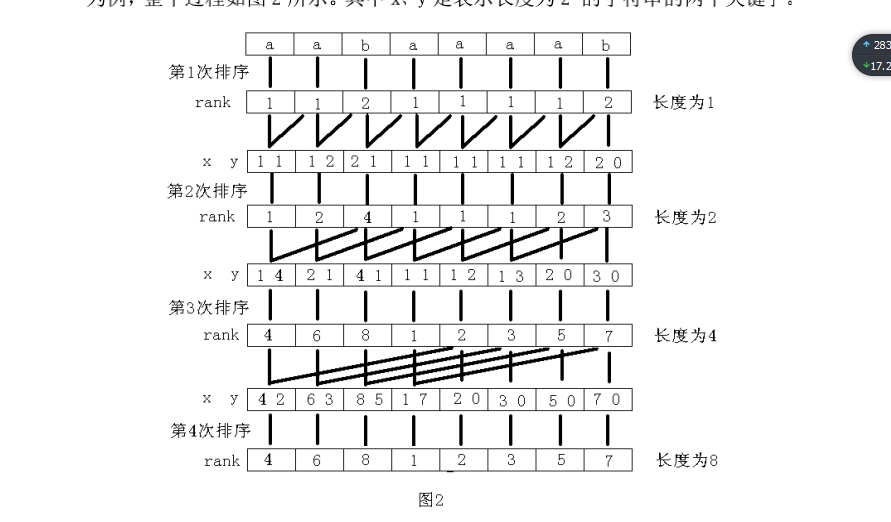
倍增算法的主要思路是:用倍增的方法对每个字符开始的长度为 2k 的子字
符串进行排序,求出排名,即 rank 值。k 从 0 开始,每次加 1,当 2k 大于 n 以
后,每个字符开始的长度为 2k 的子字符串便相当于所有的后缀。并且这些子字
符串都一定已经比较出大小,即 rank 值中没有相同的值,那么此时的 rank 值就
是最后的结果。每一次排序都利用上次长度为 2k-1的字符串的 rank 值,那么长
度为 2k 的字符串就可以用两个长度为 2k-1的字符串的排名作为关键字表示,然
后进行基数排序,便得出了长度为 2k的字符串的 rank 值。以字符串“aabaaaab”
为例,整个过程如图 2 所示。其中 x、y 是表示长度为 2k的字符串的两个关键字
模板
#include <iostream>
#include <string.h>
#include <stdio.h>
#include <algorithm>
#include <queue>
#include <vector>
using namespace std;
#define rep(i,n) for(int i = 0;i < n; i++)
const int maxn = 200000+66;
int rk[maxn],sa[maxn],height[maxn],w[maxn],wa[maxn],res[maxn];
void getSa (int len,int up) {
int *k = rk,*id = height,*r = res, *cnt = wa;
rep(i,up) cnt[i] = 0;
rep(i,len) cnt[k[i] = w[i]]++;
rep(i,up) cnt[i+1] += cnt[i];
for(int i = len - 1; i >= 0; i--) {
sa[--cnt[k[i]]] = i;
}
int d = 1,p = 0;
while(p < len){
for(int i = len - d; i < len; i++)
id[p++] = i;
rep(i,len)
if(sa[i] >= d)
id[p++] = sa[i] - d;
rep(i,len) r[i] = k[id[i]];
rep(i,up) cnt[i] = 0;
rep(i,len) cnt[r[i]]++;
rep(i,up) cnt[i+1] += cnt[i];
for(int i = len - 1; i >= 0; i--) {
sa[--cnt[r[i]]] = id[i];
}
swap(k,r);
p = 0;
k[sa[0]] = p++;
rep(i,len-1) {
if(sa[i]+d < len && sa[i+1]+d <len &&r[sa[i]] == r[sa[i+1]]&& r[sa[i]+d] == r[sa[i+1]+d])
k[sa[i+1]] = p - 1;
else k[sa[i+1]] = p++;
}
if(p >= len) return ;
d *= 2,up = p, p = 0;
}
}
int ans=0;
void getHeight(int len) {
rep(i,len) rk[sa[i]] = i;
height[0] = 0;
for(int i = 0,p = 0; i < len - 1; i++) {
int j = sa[rk[i]-1];
while(i+p < len&& j+p < len&& w[i+p] == w[j+p]) {
p++;
}
height[rk[i]] = p;
p = max(0,p - 1);
}
}
int getSuffix(char s[]) {
int len = strlen(s),up = 0;
for(int i = 0; i < len; i++) {
w[i] = s[i];
up = max(up,w[i]);
}
w[len++] = 0;
getSa(len,up+1);
getHeight(len);
return len;
} int main()
{
char s1[maxn];
scanf("%s",s1); getSuffix(s1);
return 0;
}
suffix array后缀数组的更多相关文章
- Suffix Array 后缀数组
后缀数组 顾名思义.SuffixArray(下面有时简称SA) 和字符串的后缀有关. 后缀:字符串中某个位置一直到结尾的子串.(SA中讨论包含了原串和空串).所以共同拥有len+1个后缀. 后缀数组: ...
- bzoj 4319: Suffix reconstruction 后缀数组+构造
题目大意 给定后缀数组sa,要求构造出满足sa数组的字符串.或输出无解\(n\leq 5*10^5\) 题解 我们按照字典序来考虑每个后缀 对于\(Suffix(sa[i])\)和\(Suffix(s ...
- BZOJ 4319: cerc2008 Suffix reconstruction(后缀数组)
题面 Description 话说练习后缀数组时,小C 刷遍 poj 后缀数组题, 各类字符串题闻之丧胆.就在准备对敌方武将发出连环杀时,对方一记无中生有,又一招顺 手牵羊,小C 程序中的原字符数组就 ...
- BZOJ.4319.[cerc2008]Suffix reconstruction(后缀数组 构造 贪心)
题目链接 \(Description\) 给定SA数组,求满足SA[]的一个原字符串(每个字符为小写字母),无解输出-1. \(Solution\) 假设我们现在有suf(SA[j]),要构造suf( ...
- 后缀数组(suffix array)
参考: Suffix array - Wiki 后缀数组(suffix array)详解 6.3 Suffix Arrays - 算法红宝书 Suffix Array 后缀数组 基本概念 应用:字 ...
- 后缀数组(suffix array)详解
写在前面 在字符串处理当中,后缀树和后缀数组都是非常有力的工具. 其中后缀树大家了解得比较多,关于后缀数组则很少见于国内的资料. 其实后缀数组是后缀树的一个非常精巧的替代品,它比后缀树容易编程实现, ...
- 利用后缀数组(suffix array)求最长公共子串(longest common substring)
摘要:本文讨论了最长公共子串的的相关算法的时间复杂度,然后在后缀数组的基础上提出了一个时间复杂度为o(n^2*logn),空间复杂度为o(n)的算法.该算法虽然不及动态规划和后缀树算法的复杂度低,但其 ...
- 笔试算法题(40):后缀数组 & 后缀树(Suffix Array & Suffix Tree)
议题:后缀数组(Suffix Array) 分析: 后缀树和后缀数组都是处理字符串的有效工具,前者较为常见,但后者更容易编程实现,空间耗用更少:后缀数组可用于解决最长公共子串问题,多模式匹配问题,最长 ...
- 数据结构之后缀数组suffix array
在字符串处理当中,后缀树和后缀数组都是非常有力的工具,其中后缀树大家了解得比较多,关于后缀数组则很少见于国内的资料.其实后缀是后缀树的一个非常精巧的替代品,它比后缀树容易编程实现,能够实现后缀树的很多 ...
随机推荐
- 网页title左边显示网页的logo图标
打开某一个网页会在浏览器的标签栏处显示该网页的标题和图标,当网页被添加到收藏夹或者书签中时也会出现网页的图标,怎么在网页title左边显示网页的logo图标呢? 方法1: 找一个或者作一个ico文件, ...
- ones测试用例管理平台
https://ones.ai 团队信息: 公司信息,公司logo付费信息:绑定第三方账户: 成员信息: userid,user_email,激活状态,所属部门组织架构:所属部门: 新建组 团队权钱: ...
- django会话session
因为因特网HTTP协议的特性,每一次来自于用户浏览器的请求(request)都是无状态的.独立的.通俗地说,就是无法保存用户状态,后台服务器根本就不知道当前请求和以前及以后请求是否来自同一用户.对于静 ...
- C++.可变参数_ZC测试
ZC:环境: Win7 x64(旗舰版),Microsoft Visual Studio 2010(版本 10.0.30319.1 RTMRel, Microsoft .NET Framework(版 ...
- idea环境下建立maven工程并运行scala程序
idea中scala编程环境及建立maven工程 1.下载idea软件并破解:http://blog.csdn.net/nn_jbrs/article/details/70139178 2.安装sca ...
- leecode第八十八题(合并两个有序数组)
class Solution { public: void merge(vector<int>& nums1, int m, vector<int>& nums ...
- HDU - 1400 Mondriaan's Dream
HDU - 1400 思路: 轮廓线dp入门题 #include<bits/stdc++.h> using namespace std; #define fi first #define ...
- vue-循环标记列表元素
<el-col :lg="4" class="list" v-for="(item,index) in picList"> &l ...
- Asp.net core 学习笔记 ( Area and Feature folder structure 文件结构 )
2017-09-22 refer : https://msdn.microsoft.com/en-us/magazine/mt763233.aspx?f=255&MSPPError=-2147 ...
- python中的静态方法、类方法、属性方法(福利:关于几种方法更好的解释)
该部分的三个属性都是高级方法,平时用的地方不是很多 一.静态方法 静态方法的使用不是很多,可以理解的就看一下,用的地方不是很多 class Dog(object): def __init__(self ...