[hadoop] hadoop 运行 wordcount
讲准备好的文本文件放到hdfs中

执行 hadoop 安装包中的例子
[root@hadoop01 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.8.0.jar wordcount /input/ /output/wordcount
17/05/14 02:01:17 INFO client.RMProxy: Connecting to ResourceManager at hadoop01/172.16.253.128:8032
17/05/14 02:01:19 INFO input.FileInputFormat: Total input files to process : 2
17/05/14 02:01:19 INFO mapreduce.JobSubmitter: number of splits:2
17/05/14 02:01:19 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1494742494825_0002
17/05/14 02:01:20 INFO impl.YarnClientImpl: Submitted application application_1494742494825_0002
17/05/14 02:01:20 INFO mapreduce.Job: The url to track the job: http://hadoop01:8088/proxy/application_1494742494825_0002/
17/05/14 02:01:20 INFO mapreduce.Job: Running job: job_1494742494825_0002
17/05/14 02:01:35 INFO mapreduce.Job: Job job_1494742494825_0002 running in uber mode : false
17/05/14 02:01:35 INFO mapreduce.Job: map 0% reduce 0%
17/05/14 02:02:48 INFO mapreduce.Job: map 100% reduce 0%
17/05/14 02:03:22 INFO mapreduce.Job: map 100% reduce 100%
17/05/14 02:03:25 INFO mapreduce.Job: Job job_1494742494825_0002 completed successfully
17/05/14 02:03:28 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=350
FILE: Number of bytes written=408885
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=584
HDFS: Number of bytes written=145
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=145615
Total time spent by all reduces in occupied slots (ms)=17369
Total time spent by all map tasks (ms)=145615
Total time spent by all reduce tasks (ms)=17369
Total vcore-milliseconds taken by all map tasks=145615
Total vcore-milliseconds taken by all reduce tasks=17369
Total megabyte-milliseconds taken by all map tasks=149109760
Total megabyte-milliseconds taken by all reduce tasks=17785856
Map-Reduce Framework
Map input records=14
Map output records=70
Map output bytes=666
Map output materialized bytes=356
Input split bytes=196
Combine input records=70
Combine output records=30
Reduce input groups=19
Reduce shuffle bytes=356
Reduce input records=30
Reduce output records=19
Spilled Records=60
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=9667
CPU time spent (ms)=3210
Physical memory (bytes) snapshot=330969088
Virtual memory (bytes) snapshot=6192197632
Total committed heap usage (bytes)=259284992
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=388
File Output Format Counters
Bytes Written=145
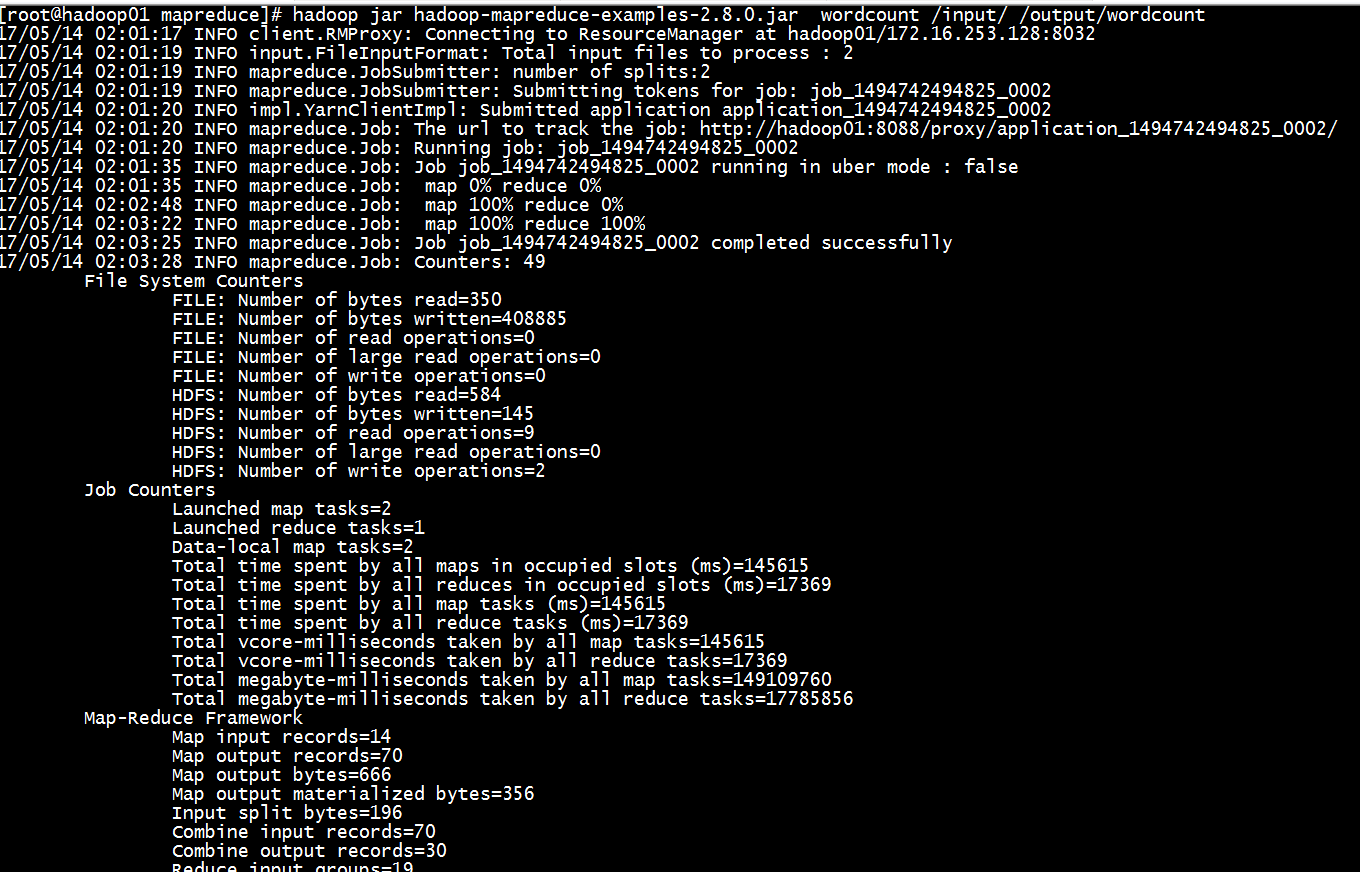
查看执行结果:
自定义wordcount :
package com.xwolf.hadoop.mapreduce; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException;
import java.util.Arrays; /**
* @author xwolf
* @date 2017-05-14 10:42
* @since 1.8
*/
public class WordCount { static class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> { /**
* map方法的生命周期: 框架每传一行数据就被调用一次
* @param key 这一行的起始点在文件中的偏移量
* @param value 这一行的内容
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//读取当前行数据
String line = value.toString();
//将这一行切分出各个单词
String[] words = line.split(" ");
//遍历数组,输出格式<单词,1>
Arrays.stream(words).forEach(e -> {
try {
context.write(new Text(e), new IntWritable(1));
} catch (Exception e1) {
e1.printStackTrace();
}
}); }
} static class WordCountReduce extends Reducer<Text,IntWritable,Text,IntWritable>{
/**
* 生命周期:框架每传递进来一个kv 组,reduce方法被调用一次
* @param key
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//定义一个计数器
int count = 0;
//遍历这一组<k,v>的所有v,累加到count中
for(IntWritable value:values){
count += value.get();
}
context.write(key, new IntWritable(count)); }
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//指定job 的jar
job.setJarByClass(WordCount.class);
//指定map 类
job.setMapperClass(WordCountMapper.class);
//指定reduce 类
job.setReducerClass(WordCountReduce.class);
//设置Mapper类的输出key和value的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置Reducer类的输出key和value的数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定要处理的数据所在的位置
FileInputFormat.addInputPath(job, new Path(args[0]));
//指定处理完成后的数据存放位置
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
打包上传至hadoop 集群。
运行出错

出错
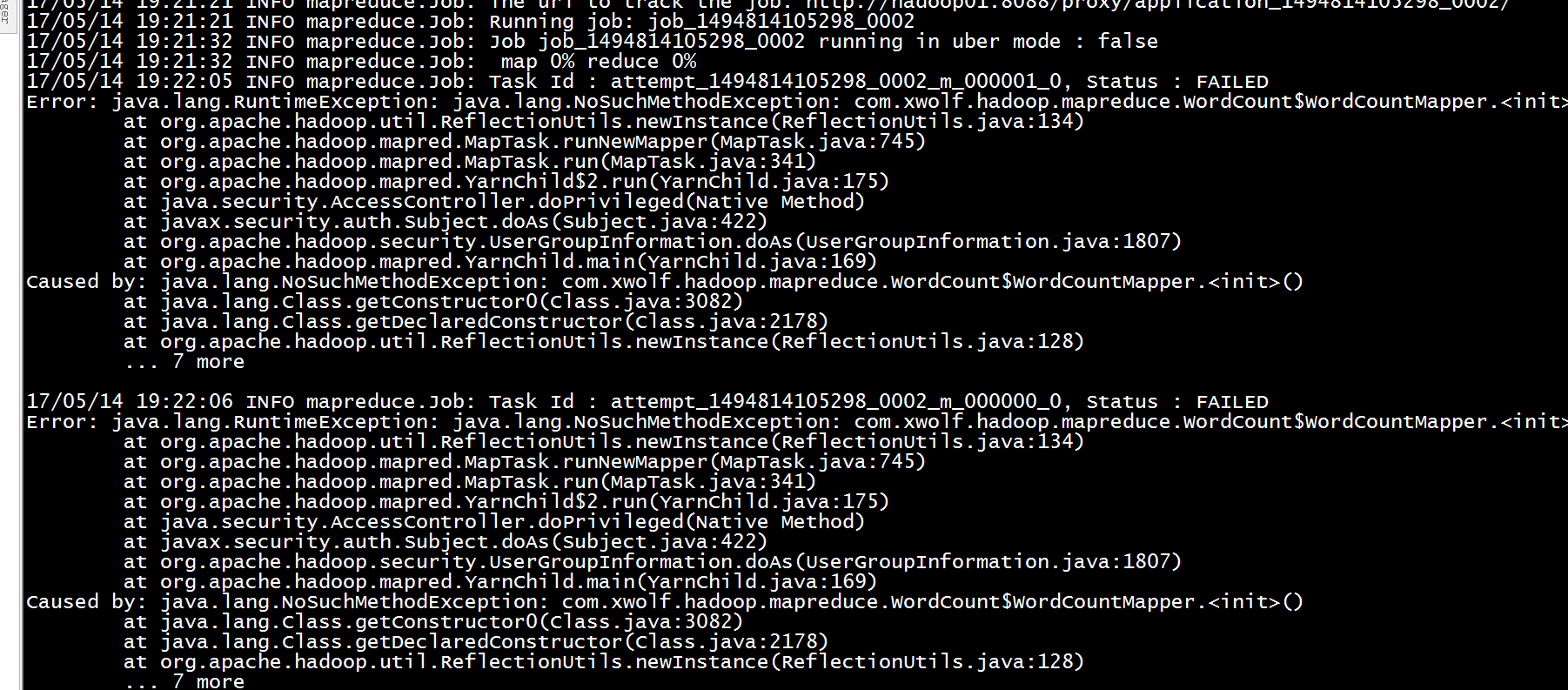
执行mapreduce出现的错,原因是map类和reduce没有加static修饰,因为hadoop在调用map和reduce类时采用的反射调用,内部类不是静态的,没有获取到内部类的实例
[hadoop] hadoop 运行 wordcount的更多相关文章
- Hadoop3 在eclipse中访问hadoop并运行WordCount实例
前言: 毕业两年了,之前的工作一直没有接触过大数据的东西,对hadoop等比较陌生,所以最近开始学习了.对于我这样第一次学的人,过程还是充满了很多疑惑和不解的,不过我采取的策略是还是先让环 ...
- hadoop机群 运行wordcount出现 Input path does not exist: hdfs://ns1/user/root/a.txt
机群搭建好,执行自带wordcount时出现: Input path does not exist: hdfs://ns1/user/root/a.txt 此错误. [root@slave1 hado ...
- RedHat 安装Hadoop并运行wordcount例子
1.安装 Red Hat 环境 2.安装JDK 3.下载hadoop2.8.0 http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/had ...
- win7下idea远程连接hadoop,运行wordCount
1.将hadoop-2.6.1.tar.gz解压到本地 配置环境变量 HADOOP_HOME E:\kaifa\hadoop-2.6.1\hadoop-2.6.1 HADOOP_BIN_PATH %H ...
- CentOS上安装Hadoop2.7,添加数据节点,运行wordcount
安装hadoop的步骤比较繁琐,但是并不难. 在CentOS上安装Hadoop2.7 1. 安装 CentOS,注:图形界面并无必要 2. 在CentOS里设置静态IP,手工编辑如下4个文件 /etc ...
- 运行第一个Hadoop程序,WordCount
系统: Ubuntu14.04 Hadoop版本: 2.7.2 参照http://www.cnblogs.com/taichu/p/5264185.html中的分享,来学习运行第一个hadoop程序. ...
- hadoop运行wordcount实例,hdfs简单操作
1.查看hadoop版本 [hadoop@ltt1 sbin]$ hadoop version Hadoop -cdh5.12.0 Subversion http://github.com/cloud ...
- debian下 Hadoop 1.0.4 集群配置及运行WordCount
说明:我用的是压缩包安装,不是安装包 官网安装说明:http://hadoop.apache.org/docs/r1.1.2/cluster_setup.html,繁冗,看的眼花...大部分人应该都不 ...
- Hadoop集群WordCount运行详解(转)
原文链接:Hadoop集群(第6期)_WordCount运行详解 1.MapReduce理论简介 1.1 MapReduce编程模型 MapReduce采用"分而治之"的思想,把对 ...
- (二)Hadoop例子——运行example中的wordCount例子
Hadoop例子——运行example中的wordCount例子 一. 需求说明 单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为 MapReduce版"Hello ...
随机推荐
- putty失活不挂起运行
https://blog.csdn.net/c1481118216/article/details/53010963 以下方式是试过了https://www.cnblogs.com/mysqlplus ...
- 使用Linux(CentOS)搭建SVN服务器全攻略
虽然在windows上搭建SVN很简单,但是效能却不高,这当然是和linux相比了.然而在linux上搭建SVN却非常繁琐,所以今天这篇文章就来一步一步教您如何在Centos上搭建SVN 安装 #yu ...
- Unity Alpha融合参数(便查)
Alpha Blending,中文译作Alpha混合 Blending就是控制透明的.处于光栅化的最后阶段. 这里例如我们给一个模型贴一个材质,那么在某个点计算出来颜色值称为源,而该点之前累积的颜色值 ...
- epoll源码分析
epoll源码分析 最近在使用libev过程中遇到一个场景:一个fd从一个ev_loop迁移到另一个ev_loop,会出现这个fd同时存在两个epoll的瞬间.不禁要问了,一个fd同时被两个epoll ...
- eclipse default handler IHandler interface “the chosen operation is not enabled”
NOTE: These two methods: Tip: Subclass AbstractHandler rather than implementing IHandler. but you ca ...
- 基于Centos搭建Jenkins 环境搭建
系统要求: CentOS 7.2 64 位操作系统 安装 Jenkins Jenkins 简介 Jenkins 是一个开源软件项目,是基于Java开发的一种持续集成工具,用于监控持续重复的工作,旨在提 ...
- Docker(二):Registry 镜像仓库
- 编写SHELL脚本--判断用户的参数
测试语句格式: [ 条件表达式 ] 常见的几种形式: [ -d /etc ] 判断/etc是不是一个目录类型, [ -e /etc/php.ini ] 判断/etc/php.ini 文件是否存在 [ ...
- swoole+Redis实现实时数据推送
<?php /** * *************************************** * 单进程保护 * * ********************************* ...
- 《ZooKeeper分布式专题与Dubbo微服务入门》
最近在慕课网新上的课程,有兴趣的朋友可以关注一波 http://coding.imooc.com/class/201.html