(第1篇)什么是hadoop大数据?我又为什么要写这篇文章?
摘要: hadoop是什么?hadoop是如何发展起来的?怎样才能正确安装hadoop环境?
这些天,有很多人咨询我大数据相关的一些信息,觉得大数据再未来会是一个朝阳行业,希望能尽早学会、入行,借这个机会,我决定写一下关于大数据的知识和我这些年的感悟。
我写这个博客目的就是为了帮助新人快速进入大数据行业,市面上有很多类似的书籍都是重理论少实践,特别缺少一线企业实践经验的传授,而这个课程会让您少走弯路、快速入门和实践,让您再最短时间内达到一个一线企业大数据工程师的能力标准,因为在课程整理和实践安排上过滤掉很多用不上的知识,直接带领大家以最直接的方式掌握大数据使用方法。
我在知名一线互联网公司从事大数据开发与管理多年,深知业界大数据公司一直对大数据人才的渴望,同时也知道有很多的大数据爱好者想参与进这个朝阳行业,因为平时也是需要参与大数据工程师的招聘与培养的,所以特别想通过一种方式,让广大的大数据爱好者更好的与企业对接,让优秀的人才找到合适的企业,《Hadoop大数据实战手册》是我根据多年从业经验整理的系列课程,接下来的文章是根据这本书再次整理成文,希望让更多的大数据爱好者收益!
那hadoop又是什么呢?
hadoop简介
Hadoop是一个由Apache基金会所开发的开源分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。解决了大数据(大到一台计算机无法进行存储,一台计算机无法在要求的时间内进行处理)的可靠存储和处理。适合处理非结构化数据,包括HDFS,MapReduce基本组件。
1.Hadoop版本衍化历史
由于Hadoop版本混乱多变对初级用户造成一定困扰,所以对其版本衍化历史有个大概了解,有助于在实践过程中选择合适的Hadoop版本。
Apache Hadoop版本分为分为1.0和2.0两代版本,我们将第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop 2.0。下图是Apache Hadoop的版本衍化史:
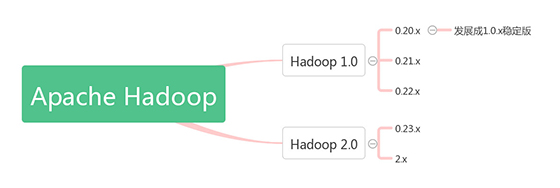
第一代Hadoop包含三个大版本,分别是0.20.x,0.21.x和0.22.x,其中,0.20.x最后演化成1.0.x,变成了稳定版。
第二代Hadoop包含两个版本,分别是0.23.x和2.x,它们完全不同于Hadoop 1.0,是一套全新的架构,均包含HDFS Federation和YARN两个系统,相比于0.23.x,2.x增加了NameNode HA和Wire-compatibility两个重大特性。

Hadoop遵从Apache开源协议,用户可以免费地任意使用和修改Hadoop,也正因此,市面上出现了很多Hadoop版本,其中比较出名的一是Cloudera公司的发行版,该版本称为CDH(Cloudera Distribution Hadoop)。
截至目前为止,CDH共有4个版本,其中,前两个已经不再更新,最近的两个,分别是CDH3(在Apache Hadoop 0.20.2版本基础上演化而来的)和CDH4在Apache Hadoop 2.0.0版本基础上演化而来的),分别对应Apache的Hadoop 1.0和Hadoop 2.0。
2. Hadoop生态圈
架构师和开发人员通常会使用一种软件工具,用于其特定的用途软件开发。例如,他们可能会说,Tomcat是Apache Web服务器,MySQL是一个数据库工具。
然而,当提到Hadoop的时候,事情变得有点复杂。Hadoop包括大量的工具,用来协同工作。因此,Hadoop可用于完成许多事情,以至于,人们常常根据他们使用的方式来定义它。
对于一些人来说,Hadoop是一个数据管理系统。他们认为Hadoop是数据分析的核心,汇集了结构化和非结构化的数据,这些数据分布在传统的企业数据栈的每一层。对于其他人,Hadoop是一个大规模并行处理框架,拥有超级计算能力,定位于推动企业级应用的执行。还有一些人认为Hadoop作为一个开源社区,主要为解决大数据的问题提供工具和软件。因为Hadoop可以用来解决很多问题,所以很多人认为Hadoop是一个基本框架。
虽然Hadoop提供了这么多的功能,但是仍然应该把它归类为多个组件组成的Hadoop生态圈,这些组件包括数据存储、数据集成、数据处理和其它进行数据分析的专门工具。
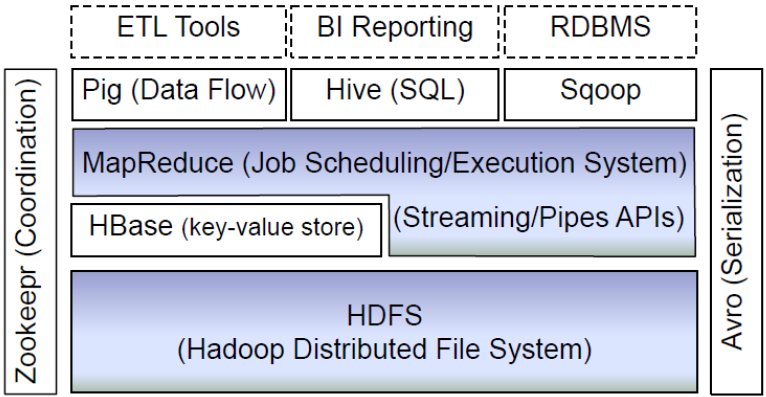
该图主要列举了生态圈内部主要的一些组件,从底部开始进行介绍:
1) HDFS:Hadoop生态圈的基本组成部分是Hadoop分布式文件系统(HDFS)。HDFS是一种数据分布式保存机制,数据被保存在计算机集群上。数据写入一次,读取多次。HDFS为HBase等工具提供了基础。
2)MapReduce:Hadoop的主要执行框架是MapReduce,它是一个分布式、并行处理的编程模型。MapReduce把任务分为map(映射)阶段和reduce(化简)。开发人员使用存储在HDFS中数据(可实现快速存储),编写Hadoop的MapReduce任务。由于MapReduce工作原理的特性, Hadoop能以并行的方式访问数据,从而实现快速访问数据。
3) Hbase:HBase是一个建立在HDFS之上,面向列的NoSQL数据库,用于快速读/写大量数据。HBase使用Zookeeper进行管理,确保所有组件都正常运行。
4) ZooKeeper:用于Hadoop的分布式协调服务。Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
5) Hive:Hive类似于SQL高级语言,用于运行存储在Hadoop上的查询语句,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。像Pig一样,Hive作为一个抽象层工具,吸引了很多熟悉SQL而不是Java编程的数据分析师。
6) Pig:它是MapReduce编程的复杂性的抽象。Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。其编译器将Pig Latin翻译成MapReduce程序序列。
7) Sqoop:是一个连接工具,用于在关系数据库、数据仓库和Hadoop之间转移数据。Sqoop利用数据库技术描述架构,进行数据的导入/导出;利用MapReduce实现并行化运行和容错技术。
看到这里,hadoop到目前的一个发展概况和hadoop的本身是是什么,基本说完了。我会在下一篇文章中详细介绍,如何安装hadoop。欢迎对大数据感兴趣的朋友与我交流学习,可以加我微信13020055199(备注:oschina交流),或者在评论区留言。
(第1篇)什么是hadoop大数据?我又为什么要写这篇文章?的更多相关文章
- 《Hadoop大数据架构与实践》学习笔记
学习慕课网的视频:Hadoop大数据平台架构与实践--基础篇http://www.imooc.com/learn/391 一.第一章 #,Hadoop的两大核心: #,HDFS,分布式文件系统 ...
- 单机,伪分布式,完全分布式-----搭建Hadoop大数据平台
Hadoop大数据——随着计算机技术的发展,互联网的普及,信息的积累已经到了一个非常庞大的地步,信息的增长也在不断的加快.信息更是爆炸性增长,收集,检索,统计这些信息越发困难,必须使用新的技术来解决这 ...
- 超人学院Hadoop大数据资源分享
超人学院Hadoop大数据资源分享 http://bbs.superwu.cn/forum.php?mod=viewthread&tid=770&extra=page%3D1 很多其它 ...
- 超人学院Hadoop大数据技术资源分享
超人学院Hadoop大数据技术资源分享 http://bbs.superwu.cn/forum.php?mod=viewthread&tid=807&fromuid=645 很多其它精 ...
- 超人学院Hadoop大数据资源共享
超人学院Hadoop大数据资源共享-----数据结构与算法(java解密版) http://yunpan.cn/cw5avckz8fByJ 訪问password b0f8 很多其它精彩内容请关注: ...
- hadoop大数据技术架构详解
大数据的时代已经来了,信息的爆炸式增长使得越来越多的行业面临这大量数据需要存储和分析的挑战.Hadoop作为一个开源的分布式并行处理平台,以其高拓展.高效率.高可靠等优点越来越受到欢迎.这同时也带动了 ...
- 【HADOOP】| 环境搭建:从零开始搭建hadoop大数据平台(单机/伪分布式)-下
因篇幅过长,故分为两节,上节主要说明hadoop运行环境和必须的基础软件,包括VMware虚拟机软件的说明安装.Xmanager5管理软件以及CentOS操作系统的安装和基本网络配置.具体请参看: [ ...
- Hadoop大数据部署
Hadoop大数据部署 一. 系统环境配置: 1. 关闭防火墙,selinux 关闭防火墙: systemctl stop firewalld systemctl disable firewalld ...
- 数据仓库和Hadoop大数据平台有什么差别?
广义上来说,Hadoop大数据平台也可以看做是新一代的数据仓库系统, 它也具有很多现代数据仓库的特征,也被企业所广泛使用.因为MPP架构的可扩展性,基于MPP的数据仓库系统有时候也被划分到大数据平台类 ...
随机推荐
- FastReport使用List的方法
public class User { string username; string password; public User(string username, string password) ...
- react框架实现点击事件计数小案例
下面将以一个小案例来讲解react的框架的一般应用,重点内容在代码段都有详细的解释,希望对大家有帮助 代码块: 代码块: import React from 'react'; import React ...
- class特性
每个HTML元素都可以附带一个class特性.有时候,你希望有一种方法可以指定多个元素并将这些元素和页面上的其他元素区分出来,而不是单独指定文档中的某个元素. <!DOCTYPE html> ...
- android 常见分辨率与DPI对照表
分辨率对应DPI ldpi QVGA (240×320) mdpi HVGA (320×480) hdpi WVGA (480×800),FWVGA (480×854) xhdpi 720P( ...
- geeksforgeeks-Array-Rotation and deletion
As usual Babul is again back with his problem and now with numbers. He thought of an array of numb ...
- ichartjs一分钟快速入门教程
1.构建项目环境 由于ichartjs是一个js库,所以只要将ichart.js加入你页面的head中就完成了ichartjs的运行环境.代码如下: <script type="tex ...
- 2018-2019-2 网络对抗技术 20165320 Exp1 PC平台逆向破解
学到的新知识总结 管道:符号为| 前一个进程的输出直接作为后一个进程的输入 输出重定向:符号为> 将内容定向输入到文件中 perl:一门解释性语言,不需要预编译,直接在命令行中使用.常与输出重定 ...
- android 面试题(一)
1.Android中真实宽高,getWidth和getMeasuredWidth的区别:哪个计算的是真实的宽? getWidth():得到的是View在父Layout中布局好后的宽度值,如果没有父布局 ...
- SLAM学习资料汇总
转自 http://www.cnblogs.com/wenhust/ 书籍: 1.必读经典 Thrun S, Burgard W, Fox D. <Probabilistic robotic ...
- 一步一步详解ID3和C4.5的C++实现
1. 关于ID3和C4.5的原理介绍这里不赘述,网上到处都是,可以下载讲义c9641_c001.pdf或者参考李航的<统计学习方法>. 2. 数据与数据处理 本文采用下面的训练数据: 数据 ...