Hive HiveServer2+beeline+jdbc客户端访问操作
HiveServer
查看/home/hadoop/bigdatasoftware/apache-hive-0.13.1-bin/bin目录文件,其中有hiveserver2
启动hiveserver2,如下图:

打开多一个终端,查看进程

有RunJar进程说明hiveserver正在运行;
beeline
启动beeline
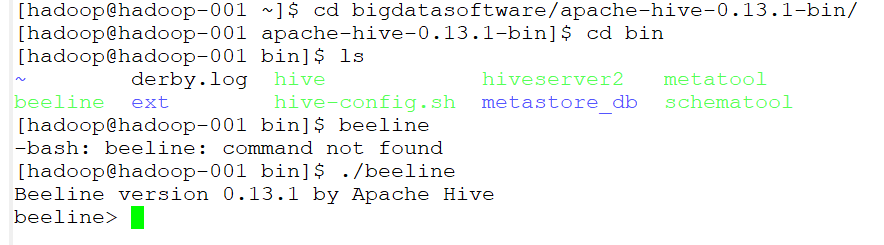
连接到jdbc
!connect jdbc:hive2://hadoop-001:10000 hadoop hadooporg.apache.hive.jdbc.HiveDriver;

然后就可以进行一系列操作了
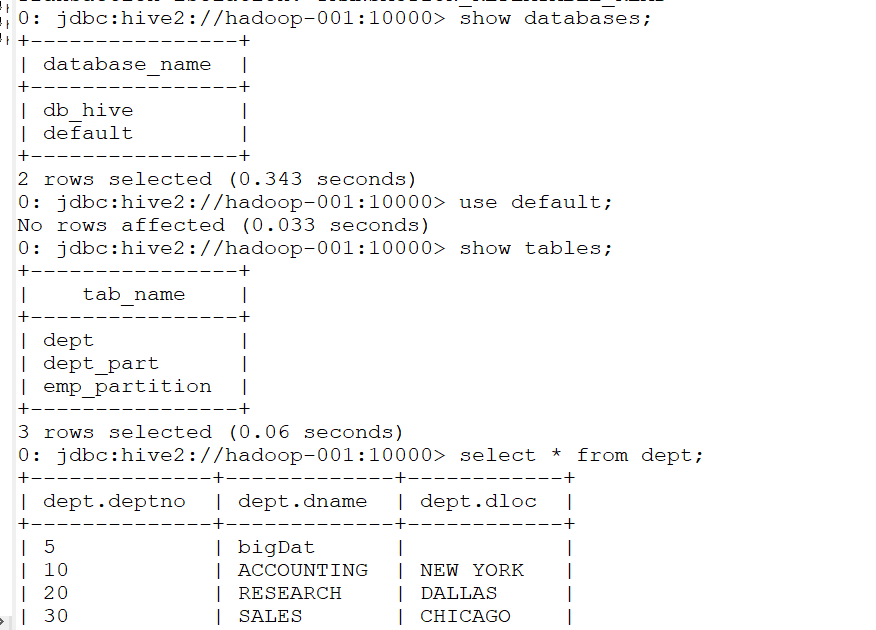
IDEA上jdbc客户端操作hive
Using JDBC
You can use JDBC to access data stored in a relational database or other tabular format.
Load the HiveServer2 JDBC driver. As of 1.2.0 applications no longer need to explicitly load JDBC drivers using Class.forName().
For example:
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connect to the database by creating a
Connectionobject with the JDBC driver.For example:
Connection cnct = DriverManager.getConnection("jdbc:hive2://<host>:<port>", "<user>", "<password>");
The default
<port>is 10000. In non-secure configurations, specify a<user>for the query to run as. The<password>field value is ignored in non-secure mode.
Connection cnct = DriverManager.getConnection("jdbc:hive2://<host>:<port>", "<user>", "");
In Kerberos secure mode, the user information is based on the Kerberos credentials.
Submit SQL to the database by creating a
Statementobject and using itsexecuteQuery()method.For example:
Statement stmt = cnct.createStatement();
ResultSet rset = stmt.executeQuery("SELECT foo FROM bar");
- Process the result set, if necessary.
These steps are illustrated in the sample code below.
代码如下:
package com.gec.demo; import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager; public class HiveJdbcClient {
private static final String DRIVERNAME = "org.apache.hive.jdbc.HiveDriver"; /**
* @param args
* @throws SQLException
*/
public static void main(String[] args) throws SQLException {
try {
Class.forName(DRIVERNAME);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.exit(1);
}
//replace "hive" here with the name of the user the queries should run as
Connection con = DriverManager.getConnection("jdbc:hive2://hadoop-001:10000/default", "hadoop", "hadoop");
Statement stmt = con.createStatement();
String tableName = "dept";
// stmt.execute("drop table if exists " + tableName);
// stmt.execute("create table " + tableName + " (key int, value string)");
// show tables
String sql = "show tables '" + tableName + "'";
System.out.println("Running: " + sql);
ResultSet res = stmt.executeQuery(sql);
if (res.next()) {
System.out.println(res.getString(1));
}
// describe table
sql = "describe " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "\t" + res.getString(2));
} // load data into table
// NOTE: filepath has to be local to the hive server
// NOTE: /tmp/a.txt is a ctrl-A separated file with two fields per line
// String filepath = "/";
// sql = "load data local inpath '" + filepath + "' into table " + tableName;
// System.out.println("Running: " + sql);
// stmt.execute(sql); // select * query
sql = "select * from " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(String.valueOf(res.getInt(1)) + "\t" + res.getString(2));
} // regular hive query
sql = "select count(1) from " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1));
}
}
}
pom.xml配置文件如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>BigdataStudy</artifactId>
<groupId>com.gec.demo</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion> <artifactId>HiveJdbcClient</artifactId> <name>HiveJdbcClient</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<hadoop.version>2.7.2</hadoop.version>
<!--<hive.version> 0.13.1</hive.version>-->
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency> <dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency> <dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>0.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>0.13.1</version>
</dependency> </dependencies>
</project>
Hive HiveServer2+beeline+jdbc客户端访问操作的更多相关文章
- 3.1 HiveServer2.Beeline JDBC使用
https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients 一.HiveServer2.Beeline 1.HiveSer ...
- JDBC数据库访问操作的动态监测 之 Log4JDBC
log4jdbc是一个JDBC驱动器,能够记录SQL日志和SQL执行时间等信息.log4jdbc使用SLF4J(Simple Logging Facade)作为日志系统. 特性: 1.支持JDBC3和 ...
- JDBC数据库访问操作的动态监测 之 p6spy
P6spy是一个JDBC Driver的包装工具,p6spy通过对JDBC Driver的封装以达到对SQL语句的监听和分析,以达到各种目的. P6spy1.3 sf.net http://sourc ...
- hive JDBC客户端启动
JDBC客户端操作步骤
- [Hive]HiveServer2配置
HiveServer2(HS2)是一个服务器接口,能使远程客户端执行Hive查询,并且可以检索结果.HiveServer2是HiveServer1的改进版,HiveServer1已经被废弃.HiveS ...
- [Hive]HiveServer2概述
1. HiveServer1 HiveServer是一种可选服务,允许远程客户端可以使用各种编程语言向Hive提交请求并检索结果.HiveServer是建立在Apache ThriftTM(http: ...
- [Spark][Hive]Hive的命令行客户端启动:
[Spark][Hive]Hive的命令行客户端启动: [training@localhost Desktop]$ chkconfig | grep hive hive-metastore 0:off ...
- jdbc数据访问技术
jdbc数据访问技术 1.JDBC如何做事务处理? Con.setAutoCommit(false) Con.commit(); Con.rollback(); 2.写出几个在Jdbc中常用的接口 p ...
- Redis的C++与JavaScript访问操作
上篇简单介绍了Redis及其安装部署,这篇记录一下如何用C++语言和JavaScript语言访问操作Redis 1. Redis的接口访问方式(通用接口或者语言接口) 很多语言都包含Redis支持,R ...
随机推荐
- kbmMW 5.08.10试用报告
1.不兼容Android 基于5.07的项目,升级到5.08,不能编译android app.已经反应给作者.作者回复将近快发布fixed,修正这个问题及其他发现的问题. 5.08.01解决了andr ...
- Shiro自定义Realm时用注解的方式注入父类的credentialsMatcher
用Shiro做登录权限控制时,密码加密是自定义的. 数据库的密码通过散列获取,如下,算法为:md5,盐为一个随机数字,散列迭代次数为3次,最终将salt与散列后的密码保存到数据库内,第二次登录时将登录 ...
- 【Python】多进程-4
#练习:用event事件控制进程执行顺序,下面例子中,主进程main函数在创建了子进程之后,依然会往下执行,所以会出现主进程先打印出来的情况 import multiprocessing import ...
- 使用solr报错
2017-11-15 20:15:18 错误介绍: 错误原因:url错误 错误解决:换成正确
- JavaScript 是如何工作的: 事件循环和异步编程的崛起 + 5个如何更好的使用 async/await 编码的技巧 - 学习笔记
那么,谁会告诉 JS 引擎去执行你的程序?事实上,JS 引擎不是单独运行的 —— 它运行在一个宿主环境中,对于大多数开发者来说就是典型的浏览器和 Node.js.实际上,如今,JavaScript 被 ...
- 路由器DHCP服务及DHCP中继
实验要求:掌握路由配置DHCP服务配置 拓扑如下: R1enable 进入特权模式config terminal 进入全局模式interface s0/0/0 进入端口ip address 192 ...
- 强化学习中的无模型 基于值函数的 Q-Learning 和 Sarsa 学习
强化学习基础: 注: 在强化学习中 奖励函数和状态转移函数都是未知的,之所以有已知模型的强化学习解法是指使用采样估计的方式估计出奖励函数和状态转移函数,然后将强化学习问题转换为可以使用动态规划求解的 ...
- youtube-dl 使用小记
0.官网地址 youtube-dl官网:https://yt-dl.org/项目地址:https://github.com/rg3/youtube-dl 1.文档简略翻译,具体请以官方文档为准 Usa ...
- PRCT-1302 the OCR has an invalid ip address
PRCT-1302 the OCR has an invalid ip address 1. 报错信息 an internal error occurred within cluster verifi ...
- 20155208徐子涵 2016-2017-2 《Java程序设计》第6周学习总结
20155208徐子涵 2016-2017-2 <Java程序设计>第6周学习总结 教材学习内容总结 10.1.1 1.Java将输入/输出抽象化为串流,数据有来源及目的地,衔接两者的是串 ...