Spark学习:ShutdownHookManager虚拟机关闭钩子管理器
Java程序经常也会遇到进程挂掉的情况,一些状态没有正确的保存下来,这时候就需要在JVM关掉的时候执行一些清理现场的代码。
JAVA中的ShutdownHook提供了比较好的方案。
JDK提供了Java.Runtime.addShutdownHook(Thread hook)方法,可以注册一个JVM关闭的钩子,这个钩子可以在一下几种场景中被调用:
1. 程序正常退出
2. 使用System.exit()
3. 终端使用Ctrl+C触发的中断
4. 系统关闭
5. OutOfMemory宕机
6. 使用Kill pid命令干掉进程(注:在使用kill -9 pid时,是不会被调用的)
下面是JDK1.7中关于钩子的定义:
public void addShutdownHook(Thread hook)
参数:
hook - An initialized but unstarted Thread object
抛出:
IllegalArgumentException - If the specified hook has already been registered, or if it can be determined that the hook is already running or has already been run
IllegalStateException - If the virtual machine is already in the process of shutting down
SecurityException - If a security manager is present and it denies RuntimePermission("shutdownHooks")
从以下版本开始:
1.3
另请参见:
removeShutdownHook(java.lang.Thread), halt(int), exit(int)
首先来测试第一种,程序正常退出的情况:
package com.hook; import java.util.concurrent.TimeUnit; public class HookTest
{
public void start()
{
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
@Override
public void run()
{
System.out.println("Execute Hook.....");
}
}));
} public static void main(String[] args)
{
new HookTest().start();
System.out.println("The Application is doing something"); try
{
TimeUnit.MILLISECONDS.sleep();
}
catch (InterruptedException e)
{
e.printStackTrace();
}
}
}
运行结果:
The Application is doing something
Execute Hook.....
如上可以看到,当main线程运行结束之后就会调用关闭钩子。
下面再来测试第五种情况(顺序有点乱,表在意这些细节):
package com.hook; import java.util.concurrent.TimeUnit; public class HookTest2
{
public void start()
{
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
@Override
public void run()
{
System.out.println("Execute Hook.....");
}
}));
} public static void main(String[] args)
{
new HookTest().start();
System.out.println("The Application is doing something");
byte[] b = new byte[**];
try
{
TimeUnit.MILLISECONDS.sleep();
}
catch (InterruptedException e)
{
e.printStackTrace();
}
} }
运行参数设置为:-Xmx20M 这样可以保证会有OutOfMemoryError的发生。
运行结果:
The Application is doing something
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at com.hook.HookTest2.main(HookTest2.java:)
Execute Hook.....
可以看到程序遇到内存溢出错误后调用关闭钩子,与第一种情况中,程序等待5000ms运行结束之后推出调用关闭钩子不同。
接下来再来测试第三种情况:
package com.hook; import java.util.concurrent.TimeUnit; public class HookTest3
{
public void start()
{
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
@Override
public void run()
{
System.out.println("Execute Hook.....");
}
}));
} public static void main(String[] args)
{
new HookTest3().start();
Thread thread = new Thread(new Runnable(){ @Override
public void run()
{
while(true)
{
System.out.println("thread is running....");
try
{
TimeUnit.MILLISECONDS.sleep();
}
catch (InterruptedException e)
{
e.printStackTrace();
}
}
} });
thread.start();
} }
在命令行中编译:javac com/hook/HookTest3.java
在命令行中运行:Java com.hook.HookTest3 (之后按下Ctrl+C)
运行结果:
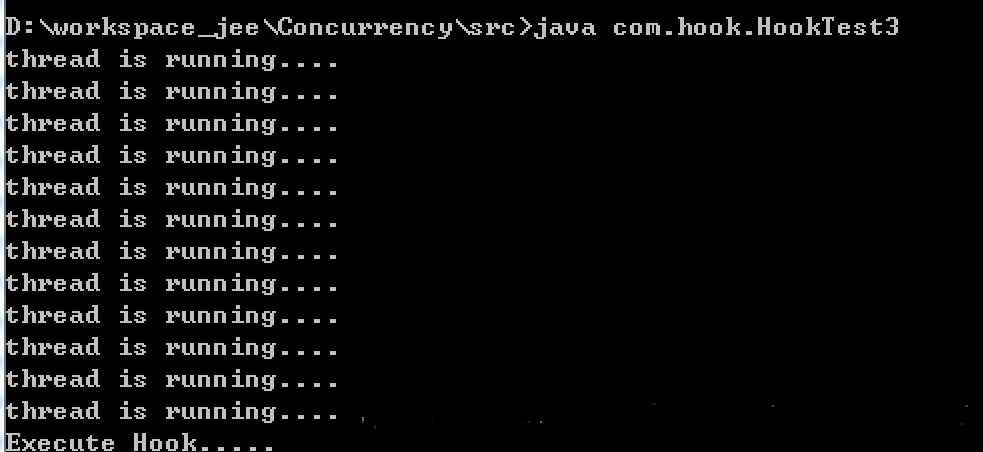
上面是java的,下面来看看spark的ShutdownHookManager
ShutdownHookManager的创建是在SparkContext中,为了在Spark程序挂掉的时候,处理一些清理工作
/** ShutdownHookManager的创建,为了在Spark程序挂掉的时候,处理一些清理工作 */
_shutdownHookRef = ShutdownHookManager.addShutdownHook(
ShutdownHookManager.SPARK_CONTEXT_SHUTDOWN_PRIORITY) { () =>
logInfo("Invoking stop() from shutdown hook")
// 这调用停止方法。关闭SparkContext,我就搞不懂了
stop()
}
来看看整体代码
package org.apache.spark.util import java.io.File
import java.util.PriorityQueue import scala.util.Try import org.apache.hadoop.fs.FileSystem import org.apache.spark.internal.Logging /**
* Various utility methods used by Spark.
*
* Spark使用的各种实用方法。
*/
private[spark] object ShutdownHookManager extends Logging {
val DEFAULT_SHUTDOWN_PRIORITY = // 默认的ShutdownHookManager优先级 /**
* The shutdown priority of the SparkContext instance. This is lower than the default
* priority, so that by default hooks are run before the context is shut down.
*
* SparkContext实例的shutdown优先级。这比默认的优先级要低,因此在默认情况下,在关闭上下文之前运行默认的hooks。
*/
val SPARK_CONTEXT_SHUTDOWN_PRIORITY = /**
* The shutdown priority of temp directory must be lower than the SparkContext shutdown
* priority. Otherwise cleaning the temp directories while Spark jobs are running can
* throw undesirable errors at the time of shutdown.
*
* temp目录的关闭优先级必须低于SparkContext关闭的优先级。否则,当Spark作业正在运行时,清理temp目录将会在关闭时抛出错误的错误。
*/
val TEMP_DIR_SHUTDOWN_PRIORITY = // 懒加载
private lazy val shutdownHooks = {
val manager = new SparkShutdownHookManager()
// 运行所有的hook,并且添加进去
manager.install()
manager
} private val shutdownDeletePaths = new scala.collection.mutable.HashSet[String]() // Add a shutdown hook to delete the temp dirs when the JVM exits
// 当JVM退出时,添加一个关闭钩子来删除temp dirs
logDebug("Adding shutdown hook") // force eager creation of logger addShutdownHook(TEMP_DIR_SHUTDOWN_PRIORITY) { () =>
logInfo("Shutdown hook called")
// we need to materialize the paths to delete because deleteRecursively removes items from
// shutdownDeletePaths as we are traversing through it.
shutdownDeletePaths.toArray.foreach { dirPath =>
try {
logInfo("Deleting directory " + dirPath)
// 递归地删除文件或目录及其内容。 如果删除失败,则抛出异常。
Utils.deleteRecursively(new File(dirPath))
} catch {
case e: Exception => logError(s"Exception while deleting Spark temp dir: $dirPath", e)
}
}
} // Register the path to be deleted via shutdown hook
// 通过关闭hook注册要删除的路径
def registerShutdownDeleteDir(file: File) {
// 得到文件的绝对路径
val absolutePath = file.getAbsolutePath() // 假如到要删除文件路径的集合
shutdownDeletePaths.synchronized {
shutdownDeletePaths += absolutePath
}
} // Remove the path to be deleted via shutdown hook 删除通过关闭hook删除的路径
def removeShutdownDeleteDir(file: File) {
val absolutePath = file.getAbsolutePath()
// 删除文件
shutdownDeletePaths.synchronized {
shutdownDeletePaths.remove(absolutePath)
}
} // Is the path already registered to be deleted via a shutdown hook ?
// 已经注册的路径是否通过关闭hook被删除?
// 判断shutdownDeletePaths中是否包含给定的路径,如果包含返回true,否则返回false
def hasShutdownDeleteDir(file: File): Boolean = {
val absolutePath = file.getAbsolutePath()
shutdownDeletePaths.synchronized {
shutdownDeletePaths.contains(absolutePath)
}
} // Note: if file is child of some registered path, while not equal to it, then return true;
// else false. This is to ensure that two shutdown hooks do not try to delete each others
// paths - resulting in IOException and incomplete cleanup.
// 注意:如果文件是某个已注册路径的子元素,而不等于它,则返回true;其他错误的。
// 这是为了确保两个关闭hooks不会试图删除彼此的路径——导致IOException和不完整的清理。
def hasRootAsShutdownDeleteDir(file: File): Boolean = {
val absolutePath = file.getAbsolutePath()
val retval = shutdownDeletePaths.synchronized {
shutdownDeletePaths.exists { path =>
!absolutePath.equals(path) && absolutePath.startsWith(path)
}
}
if (retval) {
logInfo("path = " + file + ", already present as root for deletion.")
}
retval
} /**
* Detect whether this thread might be executing a shutdown hook. Will always return true if
* the current thread is a running a shutdown hook but may spuriously return true otherwise (e.g.
* if System.exit was just called by a concurrent thread).
*
* 检测此线程是否正在执行关闭hook。如果当前线程是一个正在运行的关闭hook,但可能会错误地返回true(例如,如果系统),
* 则将始终返回true。退出是由一个并发线程调用的。
*
* Currently, this detects whether the JVM is shutting down by Runtime#addShutdownHook throwing
* an IllegalStateException.
*
* 当前,这检测到JVM是否在Runtime#addShutdownHook,抛出了一个IllegalStateException异常。
*/
def inShutdown(): Boolean = {
try {
val hook = new Thread {
override def run() {}
} // 这一点先加入后移除 是什么意思啊?
// scalastyle:off runtimeaddshutdownhook
Runtime.getRuntime.addShutdownHook(hook)
// scalastyle:on runtimeaddshutdownhook
Runtime.getRuntime.removeShutdownHook(hook)
} catch {
case ise: IllegalStateException => return true
}
false
} /**
* Adds a shutdown hook with default priority. 添加默认优先级的 shutdown hook。
*
* @param hook The code to run during shutdown.
* @return A handle that can be used to unregister the shutdown hook.
*/
def addShutdownHook(hook: () => Unit): AnyRef = {
addShutdownHook(DEFAULT_SHUTDOWN_PRIORITY)(hook)
} /**
* Adds a shutdown hook with the given priority. Hooks with lower priority values run
* first.
*
* 根据一个指定的优先级添加一个shutdown hook,优先级低的Hooks优先被运行
*
* @param hook The code to run during shutdown.
* @return A handle that can be used to unregister the shutdown hook.
*/
def addShutdownHook(priority: Int)(hook: () => Unit): AnyRef = {
shutdownHooks.add(priority, hook)
} /**
* Remove a previously installed shutdown hook. 删除先前安装的shutdown hook
*
* @param ref A handle returned by `addShutdownHook`.
* @return Whether the hook was removed.
*/
def removeShutdownHook(ref: AnyRef): Boolean = {
shutdownHooks.remove(ref)
} } private [util] class SparkShutdownHookManager { // 权限队列
private val hooks = new PriorityQueue[SparkShutdownHook]()
@volatile private var shuttingDown = false /**
* Install a hook to run at shutdown and run all registered hooks in order.
* 安装一个hook来运行关闭,并运行所有已注册的hooks。
*/
def install(): Unit = {
val hookTask = new Runnable() {
override def run(): Unit = runAll()
}
org.apache.hadoop.util.ShutdownHookManager.get().addShutdownHook(
hookTask, FileSystem.SHUTDOWN_HOOK_PRIORITY + )
} def runAll(): Unit = {
shuttingDown = true
var nextHook: SparkShutdownHook = null
while ({ nextHook = hooks.synchronized { hooks.poll() }; nextHook != null }) {
Try(Utils.logUncaughtExceptions(nextHook.run()))
}
} def add(priority: Int, hook: () => Unit): AnyRef = {
hooks.synchronized {
if (shuttingDown) {
throw new IllegalStateException("Shutdown hooks cannot be modified during shutdown.")
}
val hookRef = new SparkShutdownHook(priority, hook)
hooks.add(hookRef)
hookRef
}
} def remove(ref: AnyRef): Boolean = {
hooks.synchronized { hooks.remove(ref) }
} } private class SparkShutdownHook(private val priority: Int, hook: () => Unit)
extends Comparable[SparkShutdownHook] { override def compareTo(other: SparkShutdownHook): Int = {
other.priority - priority
} def run(): Unit = hook() }
Spark学习:ShutdownHookManager虚拟机关闭钩子管理器的更多相关文章
- Spark 分布式环境--连接独立集群管理器
Spark 分布式环境:master,worker 节点都配置好的情况下 : 却无法通过spark-shell连接到 独立集群管理器 spark-shell --master spark://soyo ...
- linux学习之lvm-逻辑卷管理器
一.简介 lvm即逻辑卷管理器(logical volume manager),它是linux环境下对磁盘分区进行管理的一种机制.lvm是建立在硬盘和分区之上的一个逻辑层,来提高分区管理的灵活性.它是 ...
- JAVA虚拟机关闭钩子(Shutdown Hook)
程序经常也会遇到进程挂掉的情况,一些状态没有正确的保存下来,这时候就需要在JVM关掉的时候执行一些清理现场的代码.JAVA中的ShutdownHook提供了比较好的方案. JDK提供了Java.Run ...
- Windows服务安装、卸载、启动和关闭的管理器
最近在重构公司的系统,把一些需要独立执行.并不需要人为关注的组件转换为Windows服务,Windows服务在使用的过程中有很多好处,相信这一点,就不用我多说了.但是每次都要建立Windows服务项目 ...
- SurvivalShooter学习笔记(八.敌人管理器)
敌人管理器:管理敌人的随机出生点创建 在场景中建立几个空物体,作为敌人的出生点 public class EnemyManager : MonoBehaviour { public PlayerHea ...
- Spark集群管理器介绍
Spark可以运行在各种集群管理器上,并通过集群管理器访问集群中的其他机器.Spark主要有三种集群管理器,如果只是想让spark运行起来,可以采用spark自带的独立集群管理器,采用独立部署的模式: ...
- 向虚拟机注册钩子,实现Bean对象的初始化和销毁方法
作者:小傅哥 博客:https://bugstack.cn 沉淀.分享.成长,让自己和他人都能有所收获! 一.前言 有什么方式,能给代码留条活路? 有人说:人人都是产品经理,那你知道吗,人人也都可以是 ...
- Python 的上下文管理器是怎么设计的?
花下猫语:最近,我在看 Python 3.10 版本的更新内容时,发现有一个关于上下文管理器的小更新,然后,突然发现上下文管理器的设计 PEP 竟然还没人翻译过!于是,我断断续续花了两周时间,终于把这 ...
- Spark学习之在集群上运行Spark(6)
Spark学习之在集群上运行Spark(6) 1. Spark的一个优点在于可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力. 2. Spark既能适用于专用集群,也可以适用于共享的云计算 ...
随机推荐
- freemarker特殊字符转义
一个坑了很久的问题,今天上午终于在同事帮助下搞定了,,利用ibatis框架,从sqlserver数据库中读取数据,放到java对象中,其中有一项description中有特殊字符,没留意,在ftl文件 ...
- Hadoop初期学习和集群搭建
留给我学习hadoop的时间不多了,要提高效率,用上以前学的东西.hadoop要注重实战,把概念和原理弄清楚,之前看过一些spark,感觉都是一些小细节,对于理解hadoop没什么帮助.多看看资料,把 ...
- day_6.9py网络编程
.路由器:能够链接不同的网络使他们之间能够通信 mac就是手拉手传输数据用的
- D - Lake Counting
Due to recent rains, water has pooled in various places in Farmer John's field, which is represented ...
- 配置数据源的三种方式和sql心跳的配置
三种方式配置数据源连接池: <?xml version="1.0" encoding="UTF-8"?> <beans xmlns=" ...
- juqery 点击谁获取他的值,赋给input标签
//html代码 <a href="javascript:;" class="confirm fahuo" data-fahuo-id="{$v ...
- PAT甲级1052 Linked List Sorting
题目:https://pintia.cn/problem-sets/994805342720868352/problems/994805425780670464 题意: 给定一些内存中的节点的地址,值 ...
- [No0000170]Spring Boot慢速入门
Spring的实例化Bean有三种方式: 使用类构造器直接实例化 使用静态工厂的方法实例化 使用实例工厂方法实例化 <?xml version="1.0" encoding= ...
- Cookie映射
Cookie映射 第 5 章 Cookie映射 http://amp.ad.sina.com.cn/sax/doc/zh-CN/xhtml/bk01pt02ch05.xhtml 第 5 章 Cooki ...
- 再探树形dp
随着校oj终于刷进了第一页,可以不用去写那些水题了,开始认真学习自己的东西,当然包括文化课.努力.. 这道题呢是道树形dp,可看到了根本就不知道怎么写思考过程: 5min 终于看懂了题 画了样例的图把 ...