XPath2Doc,一个半自动采集网页生成Word Docx文件的工具,带企查查和天眼查模板
原始出处:https://www.cnblogs.com/Charltsing/p/XPath2Doc.html
很多人需要从网站采集一些数据填写Word模板,手工操作费时费力还容易出错,所以我给朋友写了这个工具。本程序只支持Docx格式的模板文件。
本程序不是爬虫,不是自动采集工具,不能自动登录网站。需要自己在WebBrowser窗口里面手工登录,并找到需要的数据页面,然后点击程序按钮进行采集,所以是个半自动的网页数据填充Docx工具。
工作原理:
网页的每个元素,都可以表示成为XPath语句,所以我们可以读取浏览器打开的网站页面源代码,通过XPath语句得到网页元素中的文本。
教程:http://www.w3school.com.cn/xpath/index.asp
XPath语句的获取办法:
通常我们可以使用谷歌的Chrome浏览器打开网站页面,按F12调出开发者工具界面,在ELements选项卡下,随着鼠标的移动可以看到网页内容被阴影覆盖,点开三角符号,可以更进一步定位准确的位置,直到找到最终需要的数据位置。在找到的文本上点鼠标右键,在弹出的菜单中,选择Copy-Copy XPath,然后粘贴到记事本即可得到需要的XPath语句。
这里需要说明一点:如果拷贝出来的XPath语句中有/tbody会影响采集,程序内部对此问题进行了处理,但可能会在某些特殊情况下还是会影响数据采集,可以手工去掉。
软件运行环境:
Windows7 Sp1操作系统请安装下面的组件(重要:VC库如果不安装,本程序无法启动):
1、.Net Framework 4.5.2。https://www.microsoft.com/en-us/download/details.aspx?id=42642
2、32位 VC2017(或更高版本)运行库 。 https://support.microsoft.com/zh-cn/help/2977003/the-latest-supported-visual-c-downloads
下载vc_redist.x86.exe
在Windows10系统下上述组件一般自带,不需要单独安装。Windows10 1903运行通过。
不支持Windows XP操作系统。
软件操作说明:
1、本程序工作需要三个配置文件:General.ini,自定义.ini,自定义模板.docx。后两个文件名自己定义。
General.ini文件中定义了INI文件和Docx模板文件的存放目录,可以不填,默认是程序所在目录。
自定义.ini、自定义模板.docx是软件使用者自己创建的网页采集XPath语句及最后生成文件所用的Docx模板,具体设置方法请看ini文件中的说明。注意,Docx模板文件中的“@<#0001#>@”之类的字符是在INI文件中定义的用于替换网页采集内容的标记字符串。ini文件中定义了替换关键字的前后缀和模板文件名。
2、使用本程序前,请先建立好你自己的INI配置文件和Docx模板文件。(具体可以参见附带的企查查、天眼查两个配置文件和起诉书模板)
需要说明的是,模板文件支持对文档的不同部分使用不同的网址进行采集,注意Url的设置。
3、使用方法:
启动程序--选择模板--点击采集数据按钮旁边的黑色三角符号,点开下拉菜单,点击需要采集的部分。等候浏览器加载网页完毕,手工输入需要查询的内容,点击查询,找到数据的具体页面,然后点击采集数据按钮,观察右侧的列表中是不是已经得到需要的数据。继续点开下拉菜单,选择下一个需要采集的部分,如果网址发生了变化要等候浏览器加载完毕,找到需要的数据页面。点击采集数据按钮观察右侧列表中是不是得到了第二部分的数据。如此反复,直到数据全部采集完毕。
如果前后两部分的网址相同,在点击下一部分的下拉菜单之前,要先在浏览器中重新查询新的数据,等新数据页面出来之后在点击下拉菜单选择下一部分进行采集。(网址相同的情况下,点击下一部分会直接从网页取数据,如果浏览器没有换页面,数据就错了。)如果某个部分需要重新采集,请先点击下拉菜单中的该部分名称,然后点击采集按钮重复采集该部分(此时可以随意改变浏览器的数据页面,得到的就是不同公司数据)。
列表中采集得到的数据结果如果有偏差,可以单击自行修改。XPath语句如果有什么错误,也可以自己修改看测试结果(XPath语句在修改后会立即重新抓取浏览器的数据,所以浏览器最好是有效数据页面),在程序中修改的XPath语句,不会保存到INI文件中,请自行手工保存。
如果列表中数据无误,预览窗口中的Docx模板内容也正确,则可以点击创建文档按钮,填写要生成的文件名,本软件会使用抓取到的网页数据替换模板中的索引字符串,自动生成Docx文档。
需要说明的是,右下角的Docx预览窗口不能完整的支持Word文档,对不标准的文档可能会出现文本缺失或者错位现象。遇到这种情况,可以忽略,或者将模板文件改成规范的文本格式(单倍行距)。
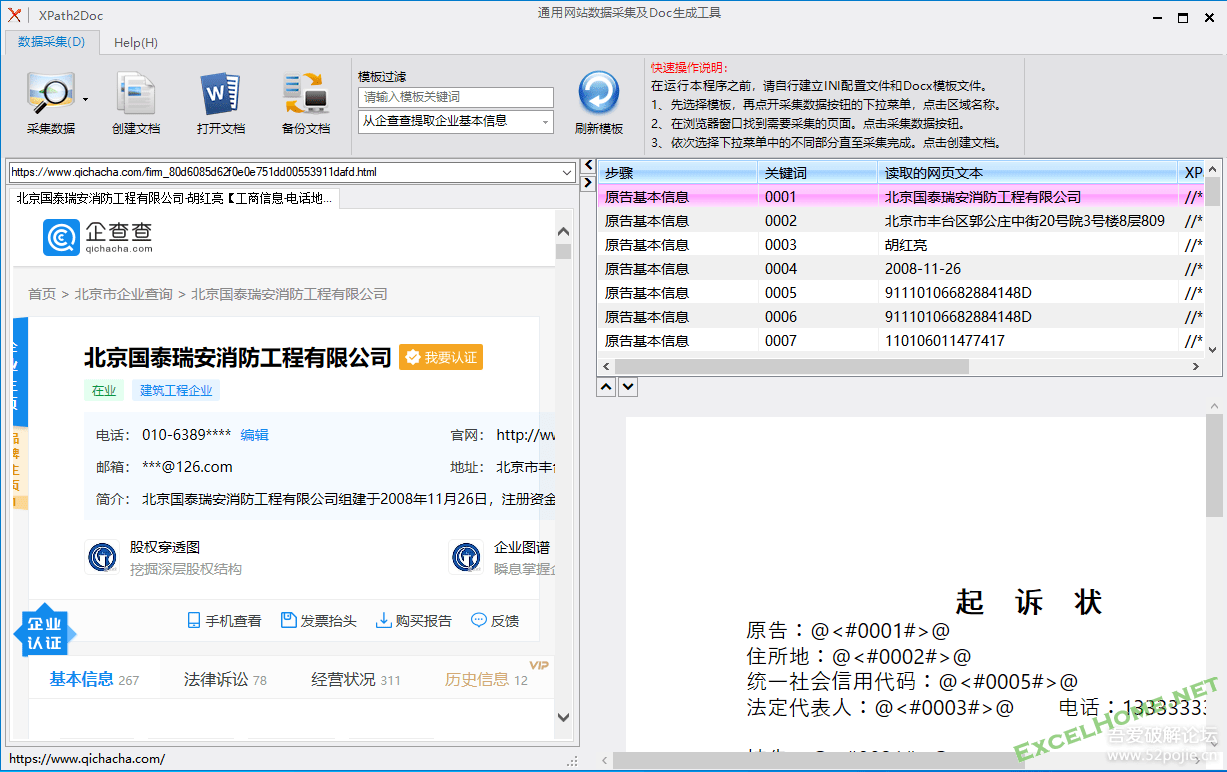
压缩包中自带了企查查、天眼查配置文件和起诉书的简单模板,供使用者参考。
本程序使用有一个门槛:通过手工操作Chrome得到网页数据的XPath语句。
建议电脑小白找个略懂鼠标操作的人帮助获取和填写INI配置文件
也可以在本贴留言,或百度联系作者以获取对程序的使用帮助。
软件操作演示可以看压缩包中的 Demo.gif 动画文件
下载链接:链接:https://pan.baidu.com/s/13hegfjZr1T9XVJqQKudPuQ 提取码:2t3m
联系QQ 564955427
XPath2Doc,一个半自动采集网页生成Word Docx文件的工具,带企查查和天眼查模板的更多相关文章
- POI读写Word docx文件
使用POI读写word docx文件 目录 1 读docx文件 1.1 通过XWPFWordExtractor读 1.2 通过XWPFDocument读 2 写docx ...
- 使用POI读写word docx文件
目录 1 读docx文件 1.1 通过XWPFWordExtractor读 1.2 通过XWPFDocument读 2 写docx文件 2.1 直接通过XWPF ...
- 利用 Pandoc 将 Markdown 生成 Word/PDF 文件
Pandoc 是一个格式转化工具,可以用于各(luan)种(qi)各(ba)样(zao)的文件转换, 反正我是认不全官网上的那个图(傲娇脸), 之前一直使用它将 Markdown 文件转换成 Html ...
- 解决 apache poi 转换 word(docx) 文件到 html 文件表格没边框的问题
一.起因 这几天在做电子签章问题,要通过替换docx文件中的占位符生成包含业务数据的合同数据,再转换成html文件,转换成pdf文件.遇到的问题是:通过apache poi转换docx到html时,原 ...
- PHPWord生成word实现table合并(colspan和rowspan)
PHPWord(http://phpword.codeplex.com/)是一个很好处理和生成WORD文档的工具,但是生成复杂的word,如colspan和rowspan的实现,还是需要你做些修改. ...
- 利用html模板生成Word文件(服务器端不需要安装Word)
利用html模板生成Word文件(服务器端不需要安装Word) 由于管理的原因,不能在服务器上安装Office相关组件,所以只能采用客户端读取Html模板,后台对模板中标记的字段数据替换并返回给客户端 ...
- PoiDocxDemo【Android将表单数据生成Word文档的方案之二(基于Poi4.0.0),目前只能java生成】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 这个是<PoiDemo[Android将表单数据生成Word文档的方案之二(基于Poi4.0.0)]>的扩展,上一篇是根 ...
- Java利用poi生成word(包含插入图片,动态表格,行合并)
转(小改): Java利用poi生成word(包含插入图片,动态表格,行合并) 2018年12月20日 09:06:51 wjw_11093010 阅读数:70 Java利用poi生成word(包含插 ...
- Python生成word
Python生成word 使用python-docx-template库, 将html转为word. python-docx-template可以使用类似jinja2的模板语法. 依赖docx库, 安 ...
随机推荐
- JQuery事件(2)
jQuery 事件 下面是 jQuery 中事件方法的一些例子: Event 函数 绑定函数至 $(document).ready(function) 将函数绑定到文档的就绪事件(当文档完成加载时) ...
- 第九篇 float浮动
float浮动 首先老师要声明,浮动这一块,和边距.定位相比,它是比较难的,但是用它,页面排版会更好. 这节课就直接上代码,看着代码去学浮动. 我们先弄一个div,给它一个背景颜色: HTML ...
- python删除数组中元素
有数组a,要求去掉a所有为0的元素 a = [2,4,0,8,9,10,100,0,9,7] Filter a= filter(None, a) Lambada a = filter(lambda x ...
- Linux中的grep 命令
介绍grep文本处理命令,它也可以解释正则. 常用选项: -E :开启扩展(Extend)的正则表达式. -i :忽略大小写(ignore case). -v :反过来(invert),只打印没有匹配 ...
- Linux: df du
df :列出文件系统的整体磁盘使用量 du :评估文件系统的磁盘使用量(常用在推估目录所占容量) 1 df :[-ahikHTm] 目录或文件名 选项或参数: -a: 列出所有的文件系统,包括系统 ...
- sed命令替换文件内容
reference: https://www.cnblogs.com/starof/p/4181985.html 抓取目录名并修改 ls | grep "XXX" > 1.t ...
- mybatis-plus generator使用
pom配置 <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus- ...
- 京东POP店铺使用京东物流切仓操作方法
首先进入京东物流工作台:https://wl.jdwl.com/ 在运营管理中,点击店铺商品 然后看截图操作
- 如何解决tab栏切换只发一次请求的问题
用的antd的tab栏组件,发现切换tab栏只在componentDidMount里面发了一次请求,后来发现是缓存问题,于是用activeKey再次进行了判断,代码如下:
- PHP入门(五)
一.超级全局变量 超级全局变量在PHP 4.1.0之后被启用, 是PHP系统中自带的变量,在一个脚本的全部作用域中都可用. PHP中预定义了几个超级全局变量(superglobals) ,这意味着它们 ...