word2vec高效训练方法
在word2vec原理中讲到如果每个词向量由300个元素组成,并且一个单词表中包含了10000个单词。回想神经网络中有两个权重矩阵——一个在隐藏层,一个在输出层。这两层都具有300 x 10000 = 3,000,000个权重!使用梯度下降法在这种巨大的神经网络下面进行训练是很慢的。并且可能更糟糕的是,你需要大量的训练数据来调整这些权重来避免过拟合。上百万的权重乘以上十亿的训练样本,意味着这个模型将会是一个超级大怪兽!这时就要采用负样本和层级softmax来优化。
word2vec的C代码中使用了一个公式来计算给出特定单词时候单词表中的单词出现的概率。
wi代表单词,z(wi)代表在总的语料库中的一个概率。比如说,如果单词”peanut”在1十亿的单词库中出现了1000次,那么z(‘peanut’) = 1e-6。
这也是代码中名为“采样”的一个来控制重采样频率的一个参数,它的默认值为0.001。更小的“采样”参数意味着单词被保存下来的几率更小。
1. 负样本
训练一个神经网络意味着使用一个训练样本就要稍微调整一下所有的神经网络权重,这样才能够确保预测训练样本更加精确。换句话说,每个训练样本都会改变神经网络中的权重。
单词表的大小意味着我们的skip-gram神经网络拥有非常庞大的权重数,所有权重都会被十亿个样本中的一个稍微地进行更新!
负采样通过使每一个训练样本仅仅改变一小部分的权重而不是所有权重,从而解决这个问题。下面介绍它是如何进行工作的。
当通过(”fox”, “quick”)词对来训练神经网络时,我们回想起这个神经网络的“标签”或者是“正确的输出”是一个one-hot向量。也就是说,对于神经网络中对应于”quick”这个单词的神经元对应为1,而其他上千个的输出神经元则对应为0。
使用负采样,我们通过随机选择一个较少数目(比如说5个)的“负”样本来更新对应的权重。(在这个条件下,“负”单词就是我们希望神经网络输出为0的神经元对应的单词)。并且我们仍然为我们的“正”单词更新对应的权重(也就是当前样本下”quick”对应的神经元)。
论文说选择5~20个单词对于较小的样本比较合适,而对于大样本,我们可以选择2~5个单词。
如果我们模型的输出层有大约300 x 10,000维度的权重矩阵。所以我们只需要更新正确的输出单词”quick”的权重,加上额外的5个其他应该输出为0的单词的权重。也就是总共6个输出神经元,和总共1800个的权重值。这些总共仅仅是输出层中3百万个权重中的0.06%。
2. 层次softmax
softmax需要对每个词语都计算输出概率,并进行归一化,计算量很大;
进行softmax的目的是多分类,那么是否可以转成多个二分类问题呢, 如SVM思想? 从而引入了层次softmax
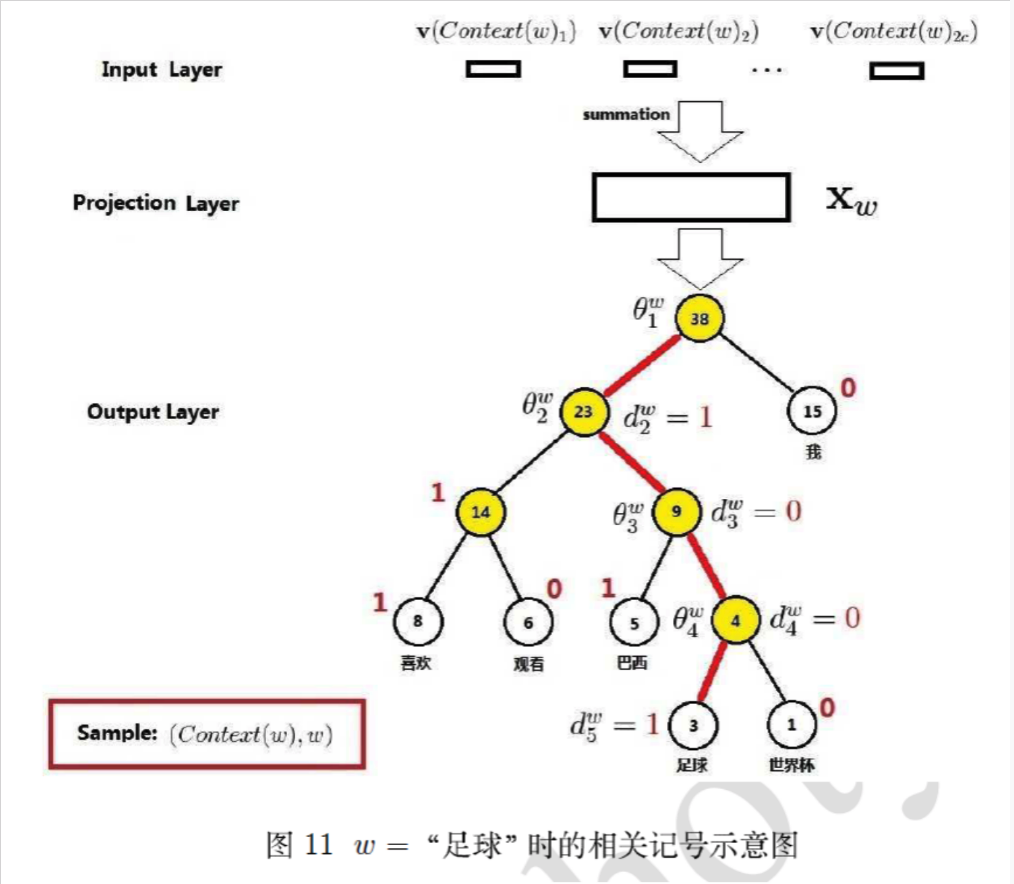
为什么有效?
1)用huffman编码做词表示
2)把N分类变成了log(N)个2分类。 如要预测的term(足球)的编码长度为4,则可以把预测为'足球',转换为4次二分类问题,在每个二分类上用二元逻辑回归的方法(sigmoid);
3)逻辑回归的二分类中,sigmoid函数导数有很好的性质,σ′(x)=σ(x)(1−σ(x))σ′(x)=σ(x)(1−σ(x))
4)采用随机梯度上升求解二分类,每计算一个样本更新一次误差函数
注:gensim的word2vec 默认已经不采用分层softmax了, 因为log21000=10log21000=10也挺大的;如果huffman的根是生僻字,则分类次数更多。
参考文献:
https://blog.csdn.net/qq_28444159/article/details/77514563
http://flyrie.top/2018/10/31/Word2vec_Hierarchical_Softmax/
https://www.cnblogs.com/liyuxia713/p/11185028.html
word2vec高效训练方法的更多相关文章
- word2vec 原理浅析 及高效训练方法
1. https://www.cnblogs.com/cymx66688/p/11185824.html (word2vec中的CBOW 和skip-gram 模型 浅析) 2. https://ww ...
- word2vec——高效word特征提取
继上次分享了经典统计语言模型,最近公众号中有很多做NLP朋友问到了关于word2vec的相关内容, 本文就在这里整理一下做以分享. 本文分为 概括word2vec 相关工作 模型结构 Count-ba ...
- word2vec原理浅析
1.word2vec简介 word2vec,即词向量,就是一个词用一个向量来表示.是2013年Google提出的.word2vec工具主要包含两个模型:跳字模型(skip-gram)和连续词袋模型( ...
- 重磅︱文本挖掘深度学习之word2vec的R语言实现
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:2013年末,Google发布的 w ...
- word2vec词向量训练及中文文本类似度计算
本文是讲述怎样使用word2vec的基础教程.文章比較基础,希望对你有所帮助! 官网C语言下载地址:http://word2vec.googlecode.com/svn/trunk/ 官网Python ...
- PaperWeekly 第五期------从Word2Vec到FastText
PaperWeekly 第五期------从Word2Vec到FastText 张俊 10 个月前 引 Word2Vec从提出至今,已经成为了深度学习在自然语言处理中的基础部件,大大小小.形形色色的D ...
- (转)word2vec前世今生
word2vec 前世今生 2013年,Google开源了一款用于词向量计算的工具——word2vec,引起了工业界和学术界的关注.首先,word2vec可以在百万数量级的词典和上亿的数据集上进行高效 ...
- NLP之——Word2Vec详解
2013年,Google开源了一款用于词向量计算的工具--word2vec,引起了工业界和学术界的关注.首先,word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练:其次,该工具得到的训 ...
- 【NLP CS224N笔记】Lecture 2 - Word Vector Representations: word2vec
I. Word meaning Meaning的定义有很多种,其中有: the idea that is represented by a word,phrase,etc. the idea that ...
随机推荐
- maven生成jar包编码问题
要做一个jar文件供外部调用,此jar的源代码中注释为中文,用maven打包后在其它工程中导入后总不能正常显示中文,记录解决方法如下: 在pom.xml中设置默认编码类型为UTF-8: <pro ...
- 使用sql做迁移矩阵
在数据分析数据差异的时候 经常用到一个图叫做迁移矩阵. 其中里面的值可以是数量也可以是百分比,我们可以从一个时间点明确的看到在另一个时间点或者另一个时间点 子类之间数量迁移. 比如这次我在公司与业务核 ...
- 如何让一个sprite绕一个点旋转,同时又可以实现指定旋转角度并慢慢停下的效果
如何让一个sprite绕一个点旋转,同时又可以实现指定旋转角度并慢慢停下的效果 首先列出sprite围绕一个点旋转的公式,这个可以自己推导,假设sprite的起始位置为(x1,y1),围绕旋转的中心点 ...
- Python 面向对象Ⅴ
基础重载方法 下表列出了一些通用的功能,你可以在自己的类重写: 运算符重载 Python同样支持运算符重载,实例如下: 以上代码执行结果如下所示: 类属性与方法 类的私有属性 __private_at ...
- http学习--常用请求方法和响应状态码
常用的http请求方法: GET方法:请求服务器资源,并返回 POST方法:向指定资源提交数据进行处理请求(比如说表单,上传文件等).数据被包含在请求体中.POST请求可能会导致新的资源建立或已有资源 ...
- Travis CI eval ./gradlew assemble 错误
问题 在进行 Travis CI 进行集成编译的时候出现错误. <-------------> 0% WAITINGThe command "eval ./gradlew ass ...
- hdu 2553 八皇后问题 基础
题意:给你一个n*n的棋盘,要求放n个皇后: <span style="font-size:18px;">#include <iostream> #incl ...
- 洛谷P3294 [SCOI2016]背单词——题解
题目传送 阅读理解题题意解释可以看这位大佬的博客. 发现求后缀与倒序求前缀是等价的,而找前缀自然就想到了trie树.将所有字符串翻转后再建入trie树中,再对每一个字符串翻转后从trie树中找前缀,就 ...
- Codeforces 343D Water Tree & 树链剖分教程
原题链接 题目大意 给定一棵根为1,初始时所有节点值为0的树,进行以下三个操作: 将以某点为根的子树节点值都变为1 将某个节点及其祖先的值都变为0 *询问某个节点的值 解题思路 这是一道裸的树链剖分题 ...
- iview之avatar组件
avatar组件是一个获取网络路径图片的组件 它再vue中使用的话build时不会被打包,路径仍然为原来的路径 所以相对路径不会有效 如下: <Avatar style="margin ...