Octavia 创建 loadbalancer 的实现与分析
目录
文章目录
从 Octavia API 看起
通过 CLI 创建一个 loadbalancer:
(octavia_env) [root@control01 ~]# openstack loadbalancer create --vip-subnet-id 122056f4-0fad-4ab2-bdf9-9b0942d0b213 --name lb1 --debug
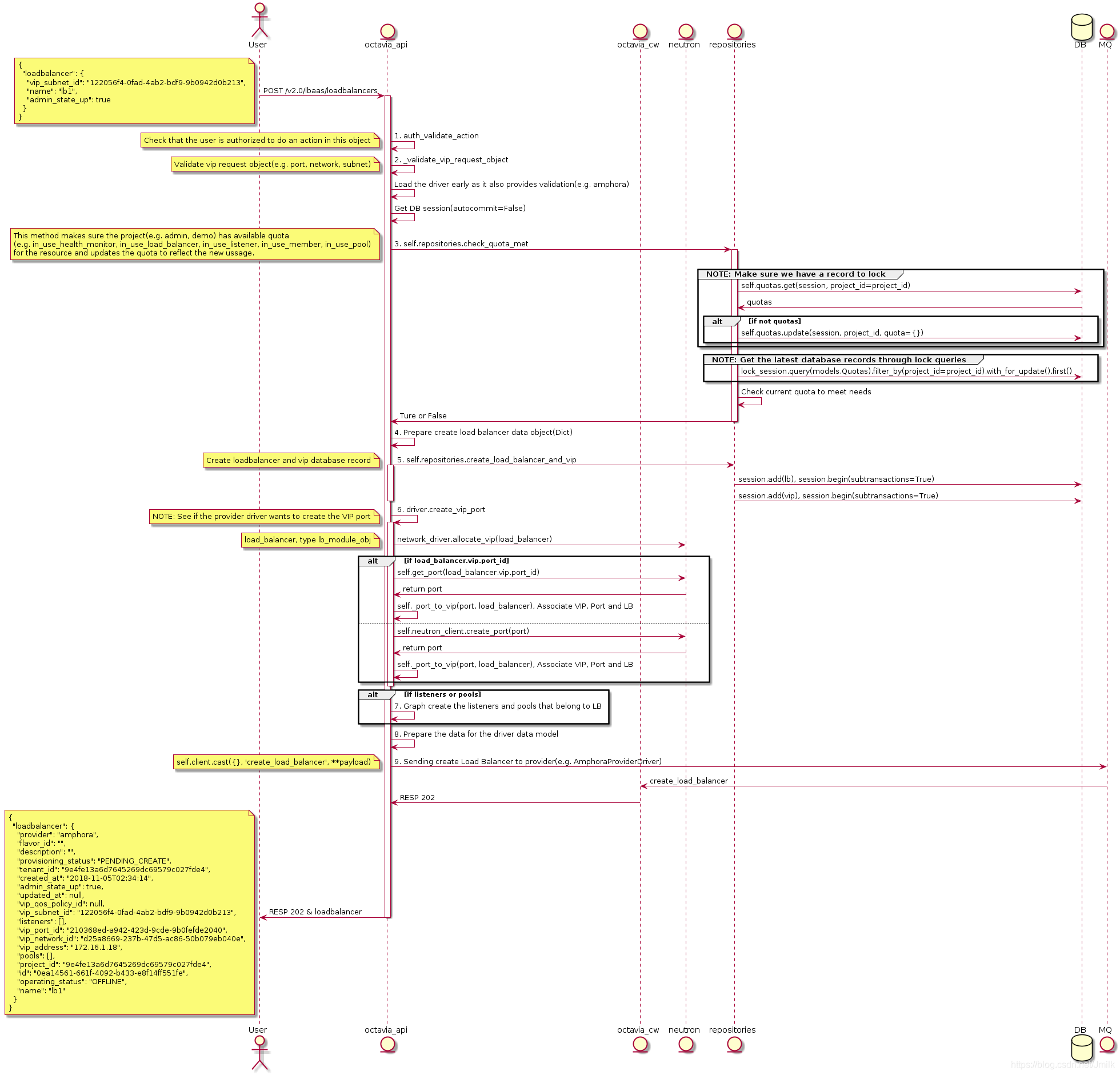
Create LB 的 Octavia API UML 图:
其中 2. _validate_vip_request_object 的细节如下 UML 图:

通过 上述 UML 图可以看出当 octavia-api service 接收到 create loadbalancer 请求后主要处理了下列几件事情:
- 验证请求用户的身份。
- 验证请求 VIP 及其相关对象(e.g. port, subnet, network, )是否可用,可以通过 config secition [networking] 来配置 Allow/disallow 的网络对象。
- 检查请求 Project 的 LB 相关 Quota,可以通过 config section [quotas] 来配置默认 Quota。
- 准备创建 loadbalancer 数据库记录的数据结构。
- 创建 loadbalancer 和 vip 的数据库记录。
- 调用 Amphora driver(default lb provider)创建 VIP 对应的 port,并将 Port、VIP、LB 三者的数据库记录关联起来。
- 以图的方式创建 loadbalancer 下属的 Listeners 和 Pools。
- 准备传递给 Amphora driver 实际用于 create_loadbalancer_flow 的数据结构。
- 异步调用 octavia-cw service 执行 create_loadbalancer_flow。
其中有几点值得我们额外的注意:
通过 networking 和 quota 用户可以限制 LBaaS 的资源范围,e.g. loadbalancer 的个数、listener 的个数 etc… 甚至可以规定使用的 VIP 列表和 VIP 只能在规定的 network/subnet 中创建。
虽然 CLI 并没有给出类似 --listeners or --pools 的选项让用户传递 loadbalancer 下属 Listeners 和 Pools 的 body 属性,但实际上 POST
/v2.0/lbaas/loadbalancers的视图函数时可以处理这两个参数的。所以在 UI 设定的时候可以完成 CLI 不支持的一次性创建 loadbalancer、listener 及 pool 的操作。创建 loadbalancer 时,如果 VIP 的 port 不存在,那么 octavia-api 会调用 neutronclient 创建,命名规则为
lb-<load_balancer.id>,所以你会在 VIP 的 network/subnet 中看见类似的 Port。
Octavia Controller Worker
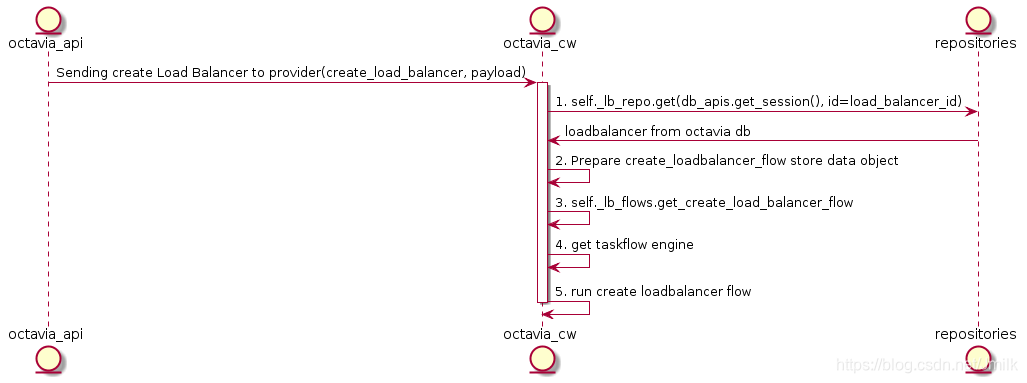
这是一个典型的 taskflow 外层封装,从 get flow、prepare flow store、get flow engine 到最后的 run flow。其中最核心的步骤是 3. self._lb_flows.get_create_load_balancer_flow,想要知道创建 loadbalancer 都做了些什么事情,就要看看这个 Flow 里面都有哪些 Task。
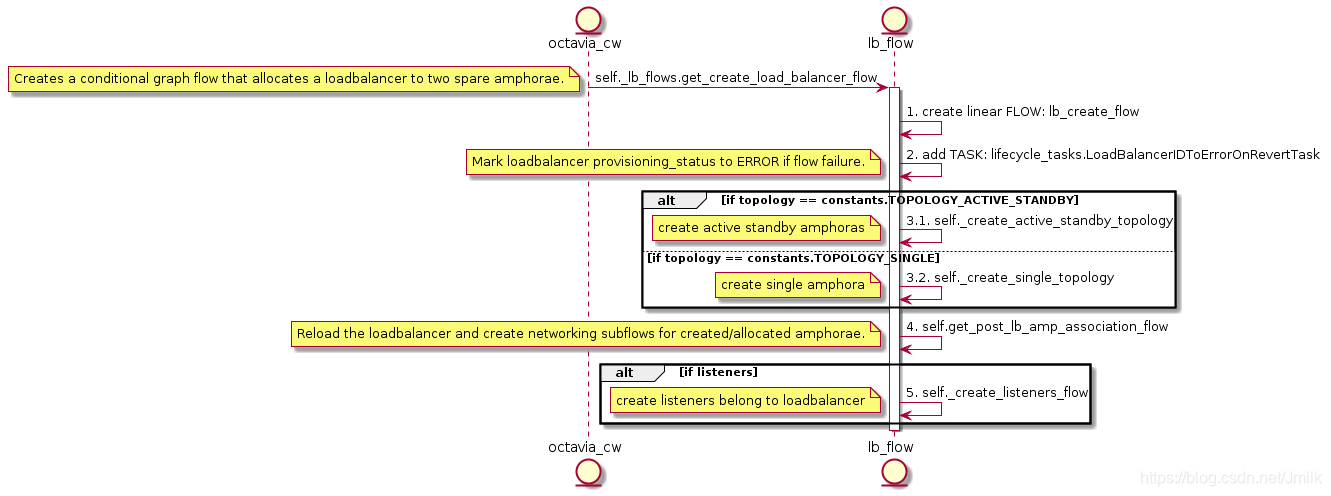
这里我们主要关注为 loadbalancer 准备 Amphora 和 Amphora 的 Networking Setup。
为 loadbalancer 准备 Amphora 的 UML 如下:

为 loadbalancer 准备 Amphora 的过程中有几点值得我们注意:
- 如果配置
[controller_worker] loadbalancer_topology = ACTIVE_STANDBY时,可以结合[nova] enable_anti_affinity = True反亲和性进一步提高 loadbalancer 的高可用性。 - 为 loadbalancer 准备 Amphora 并非每次都是通过 create amphora 来实现的,flow 会先检查是否存在可以映射到 loadbalancer 的 Amphora instance,如果存在就直接映射给 loadbalancer 使用。如果不存在才会启动创建 Amphora instance 的任务流,这里需要配合 housekeeping 机制来完成。housekeeping 会根据配置
[house_keeping] spare_amphora_pool_size=2来准备 spare Amphora instance pool,加速 loadbalancer 的创建流程。 - 创建 Amphora 使用的是 graph flow(图流),图流的特性就是开发者可以自定义条件来控制任务的流向,
amp_for_lb_flow.link就是设定判断条件的语句,这里的判断条件设定为了:如果为 loadbalancer mapping Amphora instance 成功就直接修改数据库中相关对象的隐射关系,如果 mapping 失败则先创建 Amphora instance 之后再修改数据库中相关对象的隐射关系。
为 loadbalancer 的 Amphora 准备 networking 的 UML 如下:
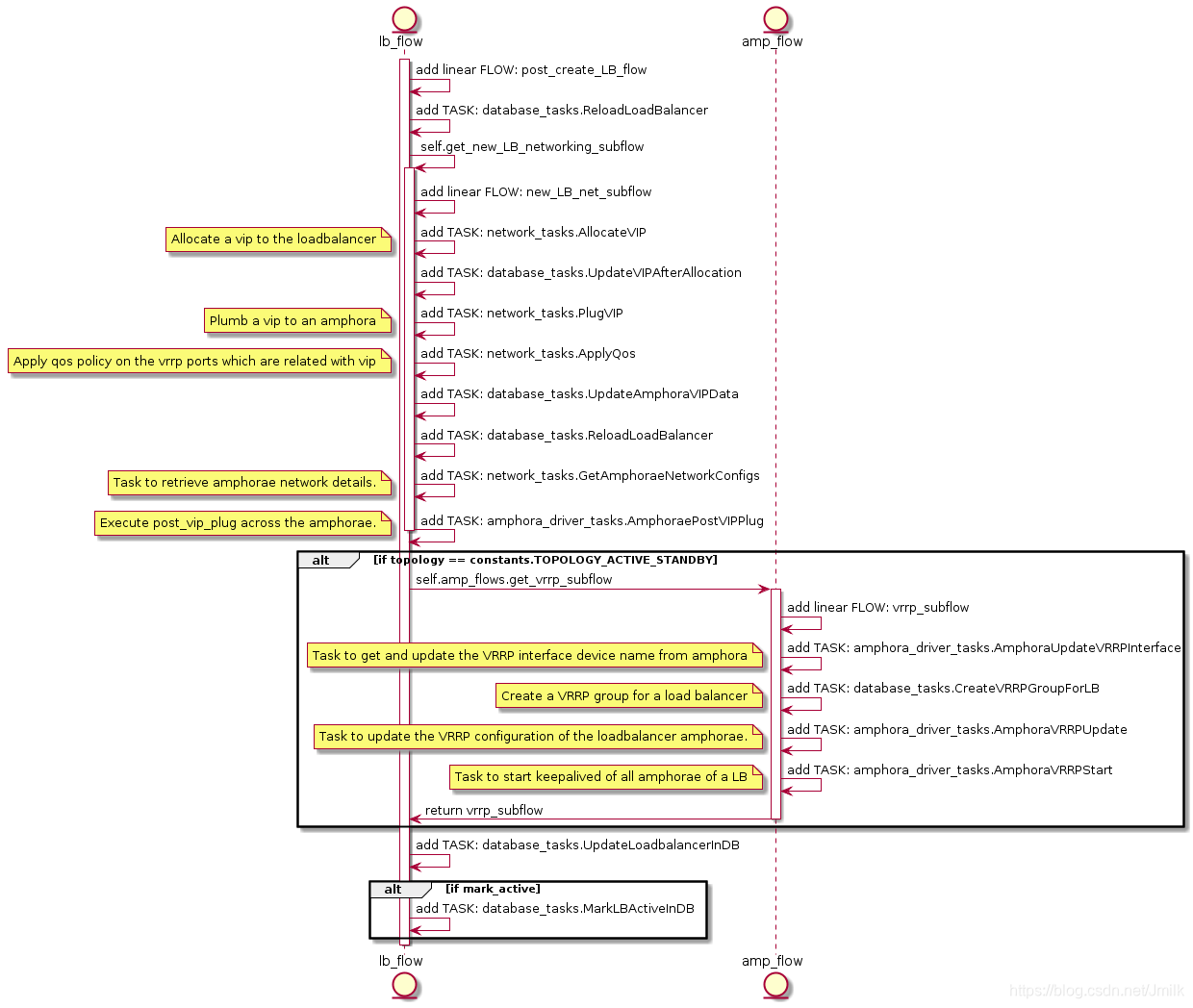
从 UML 可以见 Amphora 的 Networking 主要的工作是为 Amphora 的 Keepalived 设定 VIP,过程中会涉及到大量的 octavia-cw service 与 amphora agent 的通信。后面我们再继续深入看看关键的 Task 中都做什么什么事情。
再继续看看当 listeners 参数被传入时的 flow 是怎么样的:
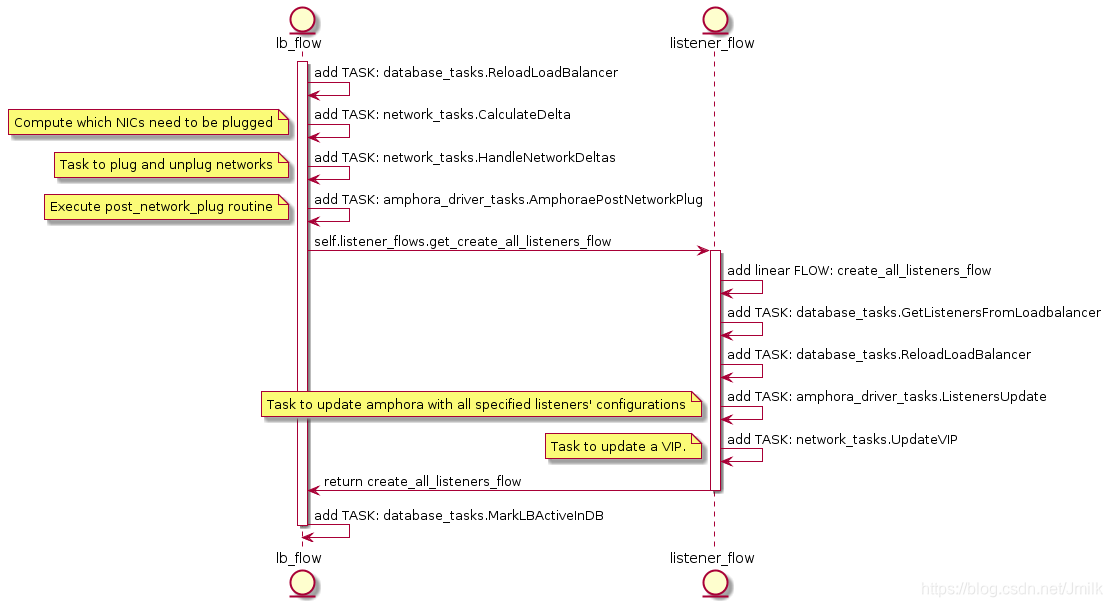
创建 Listener 实际上就是更新了 Amphora 内 HAProxy 的配置信息,所以可见上述最重要的 Task 就是 amphora_driver_task.ListenersUpdate。
自此整个 create loadbalancer 的 flow 就都看完了,接下来我们继续深入到一些关键的 Task 里,看看都做了什么事情。
database_tasks.MapLoadbalancerToAmphora
为 loadbalancer 创建 amphora 时首先会尝试 Maps and assigns a load balancer to an amphora in the database,如果 mapping SUCCESS 则会 return amphora uuid 否则为 None。graph flow 类型的 amp_for_lb_flow 就是通过这个 return 来作为任务流向控制判断条件的。
if None:
create_amp
else:
map_lb_to_amp
compute_tasks.CertComputeCreate & ComputeCreate
Task CertComputeCreate & ComputeCreate 都是创建一个 amphora instance,通过配置项 [controller_worker] amphora_driver 进行选择。当 amphora_driver = amphora_haproxy_rest_driver 时使用 CertComputeCreate,octavia-cw service 与 amphora-agent 之间通过 HTTPS 进行安全通信;当 amphora_driver = amphora_noop_driver 时使用后者,但 amphora_noop_driver 一般被用作测试,可以忽略不计。
compute_id = self.compute.build(
name="amphora-" + amphora_id,
amphora_flavor=CONF.controller_worker.amp_flavor_id,
image_id=CONF.controller_worker.amp_image_id,
image_tag=CONF.controller_worker.amp_image_tag,
image_owner=CONF.controller_worker.amp_image_owner_id,
key_name=key_name,
sec_groups=CONF.controller_worker.amp_secgroup_list,
network_ids=network_ids,
port_ids=[port.id for port in ports],
config_drive_files=config_drive_files,
user_data=user_data,
server_group_id=server_group_id)
这里调用了 novaclient 的封装来创建 amphora instance,其中 image、flavor、sec_groups、keypair 均在配置 [controller_worker] 中定义了。需要注意的是 config_drive_files 和 user_data 两个形参就是为了 amphora instance 启动时为 amphora-agent 注入证书的参数项,应用了 Nova Store metadata on a configuration drive 机制。
config_drive_files = {
'/etc/octavia/certs/server.pem': server_pem,
'/etc/octavia/certs/client_ca.pem': ca}
network_tasks.AllocateVIP
Task AllocateVIP 实际调用了 octavia.network.drivers.neutron.allowed_address_pairs:AllowedAddressPairsDriver.allocate_vip method,return 的是一个建立了 Port、VIP 和 LB 三者关系的 data_models.Vip 对象。该 method 在 octavia-api 已经被调用过一次了,所以到此时 VIP 的 Port 一般都已经存在了,只需要返回一个 data object 即可。然后在通过 Task UpdateAmphoraVIPData 落库持久化。
network_tasks.PlugVIP
Task PlugVIP 是实际为 Amphora instance(s) 设定 VIP 的。

在 PlugVIP 的过程中需要注意几点:
- 在创建 Listener 时都会 update VIP port 的 security_group_rules,因为 Listener 是依附于 VIP 的,所以 Listener 监听的协议端口都应该在 VIP 的安全组上打开,并且关闭不必要的端口。
- PlugVIP 会轮询检查所有 loadbalancer.amphora 是否具有 VIP 对应的 Port,如果没有则会创建出来,设定 VIP 再挂载到 Amphora instance 上。
NOTE:VIP 是 Act/Stby topo Amphora 的虚拟 IP。
最后
至此 Octavia 创建 loadbalancer 的流程就分析分完了,总的来说一图顶千言,还是希望通过 UML 图来描述主要流程再辅以文字说明关键点的方式来进行介绍。
Octavia 创建 loadbalancer 的实现与分析的更多相关文章
- springboot创建,自动装配原理分析,run方法启动
使用IDEA快速创建一个springboot项目 创建Spring Initializr,然后一直下一步下一步直至完成 选择web,表示创建web项目 运行原理分析 我们先来看看pom.xml文件 核 ...
- Octavia 创建 Listener、Pool、Member、L7policy、L7 rule 与 Health Manager 的实现与分析
目录 文章目录 目录 创建 Listener 创建 Pool 创建 Member CalculateDelta HandleNetworkDeltas AmphoraePostNetworkPlug ...
- Nova创建虚拟机的底层代码分析
作为个人学习笔记分享.有不论什么问题欢迎交流! 在openstack中创建虚拟机的底层实现是nova使用了libvirt,代码在nova/virt/libvirt/driver.py. #image_ ...
- JS对象创建常用方式及原理分析
====此文章是稍早前写的,本次属于文章迁移@2017.06.27==== 前言 俗话说"在js语言中,一切都对象",而且创建对象的方式也有很多种,所以今天我们做一下梳理 最简单的 ...
- 虚拟机创建流程中neutron代码分析(二)
前言: 当nova服务发送了创建port的restful调用信息之后,在neutron服务中有相应的处理函数来处理调用.根据restful的工作原理,是按照 paste.ini文件中配置好的流程去处理 ...
- 虚拟机创建流程中neutron代码分析(三)
前言: 当neutron-server创建了port信息,将port信息写入数据库中.流程返回到nova服务端,接着nova创建的流程继续走.在计算节点中neutron-agent同样要完成很多的工作 ...
- 虚拟机创建流程中neutron代码分析(一)
前言: 在openstack的学习当中有一说法就是网络占学习时间的百分之七十.这个说法或许有夸大的成分,但不可否认的是openstack中的 网络是及其重要的部分,并且难度也是相当大.试图通过nova ...
- Hadoop-1.2.1学习之Job创建和提交源码分析
在Hadoop中,MapReduce的Java作业通常由编写Mapper和Reducer開始.接着创建Job对象.然后使用该对象的set方法设置Mapper和Reducer以及诸如输入输出等參数,最后 ...
- 通过fork函数创建进程的跟踪,分析linux内核进程的创建
作者:吴乐 山东师范大学 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 一.实验过程 1.打开gdb, ...
随机推荐
- 雪花算法生成ID
前言我们的数据库在设计时一般有两个ID,自增的id为主键,还有一个业务ID使用UUID生成.自增id在需要分表的情况下做为业务主键不太理想,所以我们增加了uuid作为业务ID,有了业务id仍然还存在自 ...
- 工具使用——使用XShell连接linux系统
1.首先到官网取下载一个XShell安装包,根据提示安装成功. 2.打开软件,点击新建连接 3.在新建连接页面输入,主机名称.主机地址.端口号,点击确定按钮. 4.在弹出的会话窗口中,选中我们刚刚创建 ...
- 如何修改Git已提交的日志
情况一:最后一次提交且未push 执行以下命令: git commit --amend git会打开$EDITOR编辑器,它会加载这次提交的日志,这样我们就可以在上面编辑,编辑后保存即完成此次的修改. ...
- Codeforces 984 扫雷check 欧几里得b进制分数有限小数判定 f函数最大连续子段
A /* Huyyt */ #include <bits/stdc++.h> #define mem(a,b) memset(a,b,sizeof(a)) #define mkp(a,b) ...
- linux shell鼠标键盘快捷键
- React-Redux 总结
一.定义与功能 React-Redux 将所有组件分成两大类:UI 组件(presentational component)和容器组件(container component) 1.UI 组件特征: ...
- 怎么画一条0.5px的边
编者按:本文由人人网FED发表于掘金,并已授权奇舞周刊转载 什么是像素? 像素是屏幕显示最小的单位,在一个1080p的屏幕上,它的像素数量是1920 1080,即横边有1920个像素,而竖边为1080 ...
- Linux 性能测试工具Lmbench详解
Linux 性能测试工具Lmbench详解 2010-06-04 16:07 佚名 评测中心 字号:T | T Lmbench 是一套简易可移植的,符合ANSI/C 标准为UNIX/POSIX 而制定 ...
- 2019杭电多校&CCPC网络赛&大一总结
多校结束了, 网络赛结束了.发现自己还是太菜了,多校基本就是爆零和签到徘徊,第一次打这种高强度的比赛, 全英文,知识点又很广,充分暴露了自己菜的事实,发现数学还是很重要的.还是要多刷题,少玩游戏. 网 ...
- Idea创建多模块依赖Maven项目
idea 创建多模块依赖Maven项目 本来网上的教程还算多,但是本着自己有的才是自己的原则,还是自己写一份的好,虽然可能自己也不会真的用得着. 1. 创建一个新maven项目 2. 3. 输入g ...