[Python]ctypes+struct实现类c的结构化数据串行处理
1. 用C/C++实现的结构化数据处理
在涉及到比较底层的通信协议开发过程中, 往往需要开发语言能够有效的表达和处理所定义的通信协议的数据结构. 在这方面是C/C++语言是具有天然优势的: 通过struct, union, 和bit-fields, C/C++能够以一种最有效率也最自然的方式处理此类问题.
举例说明一下, 下图是智能电网用于远程自动抄表的通信协议的一部分 

用C可以描述如下:
struct
{
unsigned char uRouter:; //路由标识
unsigned char uSubNode:;//附属节点标识
unsigned char uCM:; //通信模块标识
unsigned char uCD:; //冲突检测
unsigned char uLevel:; //中继级别
unsigned char uChannel:;//信道标识
unsigned char uErrBate:;//纠错编码标识
unsigned char uResBytes; //预计应答字节数
unsigned short uSpeed:; //通信波特率,BIN格式
unsigned short uUnit:; //0:bps;1:kbps
unsigned char uReserve;
} Req;
这样不仅清楚的描述了完全符合通信协议要求的报文数据结构, 而且还有至少以下两个优点:
1. 对结构中的任意变量取址赋值取值极其方便, 如
struct Req r;
r.uCD = ;
r.uChannel = 0x0F;
并不必费心的计算偏移量. 而且如果以后通信协议升级了, 只需要将数据结构定义更改即可, 其余代码完全不用变动.
2. 更重要的是, 这个数据结构在计算机内存中天然的就是按照通信协议的串行结构排列的(假设大端小端问题已设置正确), 只需要
struct Req r;
...
send((unsigned char *)&r, sizeof(r));
就可以以通信协议完全一致的格式将数据转换成字节流发送出去了. 而接收解析也同样方便:
struct Req rs;
unsigned char rcv_buffer[];
...
rcv(rcv_buffer sizeof(Req));
memcpy((unsigned char *)&rs, rcv_buffer, sizeof(r));
2. 用Python实现的结构化数据处理
现在问题来了: 如果用Python, 还能够同样方便的实现上述的结构化数据处理吗? 也就是需要实现以下功能:
能够以变量名访问数据段, 不需要手动计算偏移量
能够处理bit级的数据段
能够方便的形成串行化通信字节流, 也能方便的从接收的字节流中解析数据;
有人可能觉得这不是问题: 用python的字典不是也能实现吗? 仔细想一想, 字典只能够提供第一种需求, 即以变量名访问数据段. 但python因为是高级语言, 整数只提供int一种数据结构, 而协议中很多时候数据段是bit级的, 或单字节, 两字节, 三字节的. 只用python原生的数据结构是不能直接访问bit级的数据段的, 甚至连数据体最后到底占了几字节, 都不能方便的统计.
为了解决这个问题, 本质还是要退回到C语言的级别来. 好在python提供了ctypes这个库, 能够让我们在python中实现类似C语言的功能.
>>> from ctypes import *
>>> class Req(Structure):
_fields_=[('uRouter',c_ubyte,1),
('uSubNode',c_ubyte,1),
('uCM',c_ubyte,1),
('uCD',c_ubyte,1),
('uLevel',c_ubyte,4),
('uChannel',c_ubyte,4),
('uErrBate',c_ubyte,4),
('uResBytes',c_ubyte),
('uSpeed',c_ushort,15),
('uUnit',c_ushort,1),
('uReserve',c_ubyte)]
>>> r=Req()
>>> sizeof(r)
8
>>> r.uUnit=1
>>> print r.uUnit
1
>>> r.uUnit=2
>>> print r.uUnit
0
ctypes库的最主要作用其实是用于python程序调用c编译器生成的库和dll, 但我们这里只用到数据结构这一块.
ctypes在使用时有以下注意事项:
自定义的结构体类必须继承Structure或Union类;
自定义的结构体类中必须定义一个名为fields的列表变量, 其中每个元素是一个tuple, 定义了结构体每个数据单元信息, 格式是(‘变量名字符串’, 变量数据类型 [, 比特数])
定义了class后, 可以用sizeof(类名)查看数据体字节数, 和c语言一样. 然后用实例名.成员名进行相应数据单元的访问, 如果继承后定义了init()方法, 还可以进行类的初始化操作
3. 串行数据流处理
有了结构体, 上面的三条要求满足了俩个, 关于第三个要求, ctypes虽然提供了cast()方法, 但经过我研究, 发现cast其实只能实现简单的数组等结构的数据类型指针转换, 但无法像c那样将结构体对象地址转换成字节地址的. 这种情况下就需要python的另一个库:struct
struct是专门用于结构体与数据流转换的库, 我们用到的主要方法是pack()和unpack(). pack()的使用说明如下:
struct.pack(fmt, v1, v2, …)
Return a string containing the values v1, v2, … packed according to the given format. The arguments must match the values required by the format exactly.
举个例子:
>>> pack('BHB',1,2,3)
'\x01\x00\x02\x00\x03'
pack()的用法和format()很像, 第一个参数用一个字符串指明了要转换的格式, 例如’B’表示8位无符号整数, ‘H’表示16位无符号整数等等, 具体详见python帮助里关于struct库的说明. 这里的’BHB’就等于指明了, 将后面的三个数转成字节流, 第一个数以8位无符号数表示, 第二个以16位无符号数表示, 第三个以8位无符号数表示.
等等! 哪里不对啊? 两个8位无符号数, 一个16位无符号数, 加起来应该4个字节才对. 可是我们看转换结果’\x01\x00\x02\x00\x03’一共是五个字节, 最后一个3也被当16无符号数处理了, 难道是bug了?
这个问题其实在帮助文档里也说的很清楚了, 这是所谓machine’s native format和standard format的区别. 简而言之就是, 对于有些C编译器, 如果没有做特殊编译约束, 出于处理字宽的考虑, 对类似unsigned char这样的数据, 并非真的用1字节表示, 而是用处理时最适合cpu寄存器的长度表示, 比如跟在一个无符号16位数后面的一个无符号8位数, 就同样用16位位宽表示. 这样尽管浪费了内存, 但在寻址赋值等处理起来更有效率… 总而言之, 如果一定要求严格的8位和16位, 就需要使用standard format, 就是在格式字符串的首字母加以限定, 如:
>>> pack('>BhB',1,2,3)
'\x01\x00\x02\x03'
这里的>表示: 字节流转换使用standard format, 而且使用大端模式.
4. 结构体的字节流转换
有了pack()这个工具, 再回到前面的结构体字节流转换上… 发现还是有问题啊, 因为pack()可以实现单字节, 双字节, 却没法对bit field这种东西操作. 又该怎么解决呢.
其实这个问题, 我也没找到好的解决办法, 毕竟pack()需要我们手工一个个指定变量, 定义顺序和字节长度. 这里我提供一种解决方案, 那就是借用Union.
仍以前面的结构体为例, 换一种写法:
>>> class Flag_Struct(Structure):
_fields_=[('uRouter',c_ubyte,1),
('uSubNode',c_ubyte,1),
('uCM',c_ubyte,1),
('uCD',c_ubyte,1),
('uLevel',c_ubyte,4)] >>> class Flag_Union(Union):
_fields_=[('whole',c_ubyte),
('flag_struct',Flag_Struct)] >>> class Channel_Struct(Structure):
_fields_=[('uChannel',c_ubyte,4),
('uErrBate',c_ubyte,4)] >>> class Channel_Union(Union):
_fields_=[('whole',c_ubyte),
('channel_struct',Channel_Struct)] >>> class Speed_Struct(Structure):
_fields_=[('uSpeed',c_ushort,15),
('uUnit',c_ushort,1)] >>> class Speed_Union(Union):
_fields_=[('whole',c_ushort),
('speed_struct',Speed_Struct)] >>> class Req(Structure):
_pack_=1
_fields_=[('flag',Flag_Union),
('channel',Channel_Union),
('uResBytes',c_ubyte),
('speed',Speed_Union),
('uReserve',c_ubyte)]
简而言之, 就是所有涉及bit-field的字段都用一个union和子struct来表示. (其中pack是为了1字节对齐, 原因与上一节介绍过的native format和standard format类似). 这样做的目的是为了折中比特字段访问与整字节的转化处理, 例如:
>>> r=Req()
>>> r.speed.speed_struct.uUnit=1
>>> r.flag.flag_struct.uLevel=0xf
>>> ack('>BBBHB',r.flag.whole,r.channel.whole,r.uResBytes,r.speed.whole,r.uReserve)
'\xf0\x00\x00\x80\x00\x00'
5. 一种更简单的字节流转化方法
后来通过仔细查看文档, 发现其实ctypes里提供了一种更简单的字节流转化方法:
string_at(addressof(r),sizeof(r))
addressof()和string_at都是ctypes里提供的方法. 这是最接近于原生c的处理方法, 这样连union都不用定义了
>>> class Req(Structure):
_pack_=1
_fields_=[('uRouter',c_ubyte,1),
('uSubNode',c_ubyte,1),
('uCM',c_ubyte,1),
('uCD',c_ubyte,1),
('uLevel',c_ubyte,4),
('uChannel',c_ubyte,4),
('uErrBate',c_ubyte,4),
('uResBytes',c_ubyte),
('uSpeed',c_ushort,15),
('uUnit',c_ushort,1),
('uReserve',c_ubyte)] >>> sizeof(Req)
6
>>> r=Req()
>>> r.uUnit=1
>>> r.uCM=1
>>> string_at(addressof(r),sizeof(r))
'\x04\x00\x00\x00\x80\x00'
如果需要大端的数据结构, 超类需要选择BigEndianStructure, 此时bit-field的定义也是从高到低的, 需要重新调整定义的顺序, 如下:
>>> class Req(BigEndianStructure):
_pack_=1
_fields_=[('uLevel',c_ubyte,4),
('uCD',c_ubyte,1),
('uCM',c_ubyte,1),
('uSubNode',c_ubyte,1),
('uRouter',c_ubyte,1),
('uErrBate',c_ubyte,4),
('uChannel',c_ubyte,4),
('uResBytes',c_ubyte),
('uUnit',c_ushort,1),
('uSpeed',c_ushort,15),
('uReserve',c_ubyte)] >>> r=Req()
>>> r.uLevel=0xf
>>> r.uUnit=1
>>> string_at(addressof(r),sizeof(r))
'\xf0\x00\x00\x80\x00\x00'
最后有人要问了: Python是一种高级语言, 为啥要做这么低级的事情呢? 其实术业有专攻, 对于嵌入式通信, 用python做高层的辅助测试工具是非常方便的.
将字节流灌注到结构体中实现解析的方法:
r = Req()
s = io_rcv() #receive byte stream from io
memmove(addressof(r),s,sizeof(Req))
...
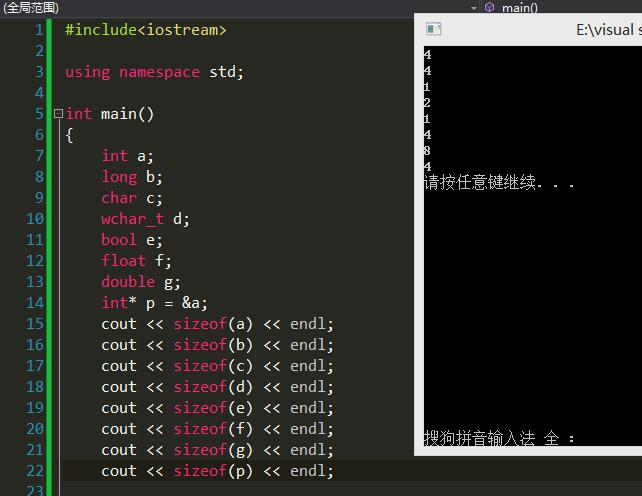
C++数据类型与长度
|
类型 |
16位系统/字节 |
32位系统/字节 |
64位系统/字节 |
|
char |
1 |
1 |
1 |
|
char* |
2 |
4 |
4 |
|
short |
2 |
2 |
2 |
|
int |
2 |
4 |
4 |
|
long |
4 |
4 |
8 |
|
long long |
8 |
8 |
8 |
| double | 8 | ||
| bool | 1 | 1 |
1字节(Byte)=8比特(bit) (位)
参考:[Python]ctypes+struct实现类c的结构化数据串行处理
[Python]ctypes+struct实现类c的结构化数据串行处理的更多相关文章
- Python作业本——第5章 字典和结构化数据
习题 1. {} 2. {'fow': 42} 3.字典是无序的 4.报错 (KeyError) 5.第一种是既搜索键又搜索值,第二种值搜索键 没有区别,in操作符检查一个值是不是字典的一 ...
- Python爬虫(九)_非结构化数据与结构化数据
爬虫的一个重要步骤就是页面解析与数据提取.更多内容请参考:Python学习指南 页面解析与数据提取 实际上爬虫一共就四个主要步骤: 定(要知道你准备在哪个范围或者网站去搜索) 爬(将所有的网站的内容全 ...
- 零基础学Python之结构化数据(附详细的代码解释和执行结果截图)
3结构化数据 字典(查找表).集合.元组.列表 3.1字典 是有两列任意多行的表,第一列存储一个键,第二列存储一个值. 它存储键/值对,每个唯一的键有一个唯一与之关联的值.(类似于映射.表) 它不会维 ...
- TensorFlow从1到2(六)结构化数据预处理和心脏病预测
结构化数据的预处理 前面所展示的一些示例已经很让人兴奋.但从总体看,数据类型还是比较单一的,比如图片,比如文本. 这个单一并非指数据的类型单一,而是指数据组成的每一部分,在模型中对于结果预测的影响基本 ...
- Spark SQL - 对大规模的结构化数据进行批处理和流式处理
Spark SQL - 对大规模的结构化数据进行批处理和流式处理 大体翻译自:https://jaceklaskowski.gitbooks.io/mastering-apache-spark/con ...
- [转] Protobuf高效结构化数据存储格式
从公司的项目源码中看到了这个东西,觉得挺好用的,写篇博客做下小总结.下面的操作以C++为编程语言,protoc的版本为libprotoc 3.2.0. 一.Protobuf? 1. 是什么? Goo ...
- Spark如何与深度学习框架协作,处理非结构化数据
随着大数据和AI业务的不断融合,大数据分析和处理过程中,通过深度学习技术对非结构化数据(如图片.音频.文本)进行大数据处理的业务场景越来越多.本文会介绍Spark如何与深度学习框架进行协同工作,在大数 ...
- MySQL 5.7:非结构化数据存储的新选择
本文转载自:http://www.innomysql.net/article/23959.html (只作转载, 不代表本站和博主同意文中观点或证实文中信息) 工作10余年,没有一个版本能像MySQL ...
- 利用Gson和SharePreference存储结构化数据
问题的导入 Android互联网产品通常会有很多的结构化数据需要保存,比如对于登录这个流程,通常会保存诸如username.profile_pic.access_token等等之类的数据,这些数据可以 ...
随机推荐
- 解决:centos配置ssh免密码登录后仍要输入密码
转自https://www.jb51.net/article/121180.htm 第一步:在本机中创建秘钥 1.执行命令:ssh-keygen -t rsa 2.之后一路回车就行啦:会在-(home ...
- ORA-00979: 不是 GROUP BY 表达式
在oracle数据库中,sql语句中group by子句报错,原因是select 存在列字段,而group by中不存在.
- Redis5以上版本伪集群搭建(高可用集群模式)
redis集群需要至少要三个master节点,我们这里搭建三个master节点,并且给每个master再搭建一个slave节点,总共6个redis节点,这里用一台机器(可以多台机器部署,修改一下ip地 ...
- java软件设计模式只单例设计模式
概述 设计模式(Design pattern)是一套被反复使用.多数人知晓的.经过分类编目的.代码设计经验的总结.使用设计模式是为了可重用代码.让代码更容易被他人理解.保证代码可靠性. 毫无疑问,设计 ...
- 2019-11-29-VisualStudio-使用多个环境进行调试
title author date CreateTime categories VisualStudio 使用多个环境进行调试 lindexi 2019-11-29 08:58:49 +0800 20 ...
- - Power Strings (字符串哈希) (KMP)
https://www.cnblogs.com/widsom/p/8058358.htm (详细解释) //#include<bits/stdc++.h> #include<vect ...
- 【vue2.x基础】用npm起一个完整的项目
1. 安装vue npm install vue -g 2. 安装vue-cli脚手架 npm install vue-cli -g 3. 安装webpack npm install webpack ...
- Python核心技术与实战——十二|Python的比较与拷贝
我们在前面已经接触到了很多Python对象比较的例子,例如这样的 a = b = a == b 或者是将一个对象进行拷贝 l1 = [,,,,] l2 = l1 l3 = list(l1) 那么现在试 ...
- robotframework 使用Chrome手机模拟器两种方法
Open Google Simulator1 ${device metrics}= Create Dictionary width=${360} height=${640} pixelRatio=${ ...
- 深入理解JAVA虚拟机 自动内存管理机制
运行时数据区域 其中右侧三个一起的部分是每个线程一份,左侧两个是所有线程共享的. 程序计数器(Program Counter Register) 英文名称叫Program Counter Regist ...