可决系数R^2和方差膨胀因子VIF
然而很多时候,被筛选的特征在模型上线的预测效果并不理想,究其原因可能是由于特征筛选的偏差。
但还有一个显著的因素,就是选取特征之间之间可能存在高度的多重共线性,导致模型对测试集预测能力不佳。
为了在筛选特征之初就避免陷入这样的误区。介绍一种VIF(方差膨胀检验)方法,来对特征之间的线性相关关系进行检验,从而选取到独立性更好的特征,增强模型的解释能力。
1.可决系数R^2
1.1什么是可决系数
可决系数,亦称测定系数、决定系数、可决指数。
与复相关系数类似的,表示一个随机变量与多个随机变量关系的数字特征,用来反映回归模式说明因变量变化可靠程度的一个统计指标,一般用符号“R”表示,
可定 义为已被模式中全部自变量说明的自变量的变差对自变量总变差的比值。
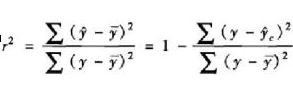
1.2总变异的分割
一个特定数值对于其平均值的偏离,称为离差,而一变量的各数值对于其平均值的偏离,称为变异。通常用离差平方和来描述变异程度。离差平方和又简称平方和(Sum of square)。在研究单变量的离中趋势描述时,我们已经接触了离差平方和的概念,样本标准差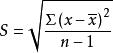 的定义公式中就直接使用了上述概念。平方和被相应的自由度去除,得到平均平方,简称为均方(Mean square)。样本标准差就是被自由度(n-1)所平均的x对于
的定义公式中就直接使用了上述概念。平方和被相应的自由度去除,得到平均平方,简称为均方(Mean square)。样本标准差就是被自由度(n-1)所平均的x对于 离差均方的算术平方根。下面我们将应用平方的概念去开发测度一个回归方程拟合协变关系效果的量数。
离差均方的算术平方根。下面我们将应用平方的概念去开发测度一个回归方程拟合协变关系效果的量数。
先结合图1分析一下在因变量y倚自变量x回归前提下y值的离差。
y值对其平均数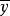 的离差可以看作是由两部分合成的,一是y的回归拟合值对平均数的离差(
的离差可以看作是由两部分合成的,一是y的回归拟合值对平均数的离差(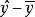 ),另一是y值对于拟合值的离差(
),另一是y值对于拟合值的离差( )。
)。
前者呈线性变化,在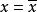 时,=0,x取值越偏离,这一离差就越大,存在着这样的函数关系:
时,=0,x取值越偏离,这一离差就越大,存在着这样的函数关系:
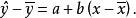
这一离差完全是由y倚x的回归关系决定的,因而称为已解释离差(Explained deviation)。
后者呈随机变化,与y倚x的回归关系无关,因而称为未解释离差(Unexplained deviation)。
总离差与已解释离差、未解释离差的关系写成公式是:
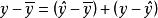 。
。
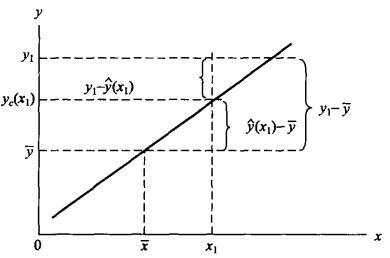 图1
图1
总离差的平方和,简称总平方和,用SST表示,又称作总变差(Total variation)。
已解释离差的平方和,简称回归平方和,用SSR表示,又称作已解释变差(Explained variation)。
未解释离差的平方和,简称误差平方和,用SSE表示,又称作未解释变差(Unexplained variation)。
可以证明,由总离差的分解公式能推出总变差的分解公式:
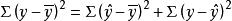 ,或:SST=SSR+SSE。
,或:SST=SSR+SSE。
将上式两边都除以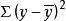 ,得:已解释变差/总变量 +未解释变差/总变差=1,即
,得:已解释变差/总变量 +未解释变差/总变差=1,即
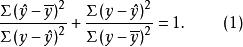
这样我们就把在绝对数意义上对总变差的分割,改换成在相对数意义上对总变差的分割,这对于研究回归方程的拟合效果很有帮助。
1.3样本可决系数
从公式(1)看到,若以总变差为基数,相对数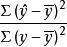 表示的是回归关系已经解释的y值变异在其总变异中所占的比率,而相对数
表示的是回归关系已经解释的y值变异在其总变异中所占的比率,而相对数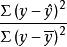 则表示回归关系不能解释的y值变异在总变异中所占的比率。
则表示回归关系不能解释的y值变异在总变异中所占的比率。
前者正是我们要寻求的测度回归方程拟合y对x的协变关系效果的量数,称为可决系数(Coefficient of determination)。
产生于样本数据的可决系数是样本可决系数,用r2表示。
在总体回归分析中,相对于样本可决系数的是总体可决系数,用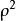 表示。
表示。
因此,样本可决系数的定义公式是:
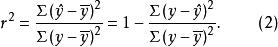
1.4相关系数与可决系数的关系
由可以推导到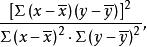 所以存在着这样的关系:可决系数是相关系数的二次幂。
所以存在着这样的关系:可决系数是相关系数的二次幂。
因此,也可以在求得可决系数的基础上计算相关系数,方法是将可决系数开平方,至于平方根的符号,则取与回归方程斜率b相同的符号。正是因为存在这样的关系,我们用r2作为可决系数的符号,而没有另用别的字母。
即然r和r2两者问存有这样的联系,那么它们的描述分析作用是否相同呢?我们认为,尽管两者对变量间协变关系的解释有相通的一面,但是两者间的区别也是不容忽视的。
首先,可决系数是在拟合回归方程后进一步评价它的解释作用,而回归分析有其具体目的和假定前提。相关系数直接用于相关分析,它只描述变量间协变关系的密切程度,而不问哪个是自变量,哪个是因变量,相关分析也有3条假设前提:
(1) X和Y均为随机变量。
(2) X和Y均服从正态分布,两者不必相互独立。
(3) 对于X所有取值,Y值的标准差都相等;对于Y所有取值,X值的标准差也都相等。
这样看来,可决系数和相关系数所描述的问题性质不尽相同。
其次,可决系数取已解释变差对总变差的比率形式,在运算上有直接的解释意义。相关系数是沿交叉乘积和——协方差——相关系数的思想开发出来的,其最终公式形式不好作直接的解释。尽管如此,在许多应用中,如果两者都可以出现,我们还是更多地注意到r 值。
1.5总体可决系数
总体可决系数是在总体中关于Y总变异中总体回归方程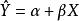 已经解释的变异所占比重的描述量数。它用下式表示
已经解释的变异所占比重的描述量数。它用下式表示
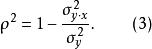
在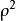 的定义公式中,
的定义公式中,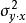 是围绕总体回归直线的方差,
是围绕总体回归直线的方差,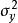 是围绕总体平均数的方差。
是围绕总体平均数的方差。
作为总体参数,通常视为未知的,有待于用样本统计量去估计。将和的无偏估计量分别代入上式,即得到估计量的公式
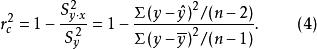
不难发现,公式(2)与公式(4)略有不同,前者采用的是平方和比率的形式,而后者采用的是均方和比率的形式。
 称为经调整样本可决系数(Adjusted coefficient of determination),它用于对总体可决系数进行点估计。
称为经调整样本可决系数(Adjusted coefficient of determination),它用于对总体可决系数进行点估计。
经调整可决系数平抑了方程中自变量数目的对解释作用的夸大,尤其在多元回归分析中,因为对同一样本k个自变量的回归方程总比k-1个自变量的回归方程求得已解释变差小,
经调整的可决系数在k个自变量的方程中已解释变差除以(n-k-1),而在(k-1)个自变量的方程中则除以(n-k-2)。
2方差膨胀因子VIF
所谓VIF方法,计算难度并不高。在线性回归方法里,应用最广泛的就是最小二乘法(OLS),只不过我们对每个因子,用其他N个因子进行回归解释。
其中有一个检验模型解释能力的检验统计指标为R^2(样本可决系数),R^2的大小决定了解释变量对因变量的解释能力。
而为了检验因子之间的线性相关关系,我们可以通过OLS对单一因子和解释因子进行回归,然后如果其R^2较小,说明此因子被其他因子解释程度较低,线性相关程度较低。
注:之所以不使用协方差计算相关性是由于协方差难以应用在多元线性相关情况下。给出VIF计算方法:
其中, 为第i个变量
与其他全部变量
(
)的复相关系数,所谓复相关系数即可决系数
的算术平方根,也即拟合优度的算术平方根。不过这个可决系数
是指用
做因变量,对其他全部
(
)做一个新的回归以后得到的可决系数。
方差膨胀因子不仅和可决定系数有关,还跟皮尔逊相关系数(矩阵)有关系
,
不用说,就是对这个相关系数矩阵求行列式,即皮尔逊相关系数矩阵。例子如下
而 则指的是将相关系数矩阵
的第i行i列去掉,剩下的部分计算行列式。如果大学线代课没全忘的话,这个东西就是余子式。
3、检验实践
选取因子:EPS(每股收益),
ROE(净资产收益率),
market_cap(市值),
pb(市净率),
'net_profit_ratio'(销售净利率),
'gross_income_ratio',(销售毛利率)
'quick_ratio',(速动比率)
'current_ratio'(流动比率(单季度))
时间窗口选取:2012.3.4—2018.7.4
回望频率:两个月检
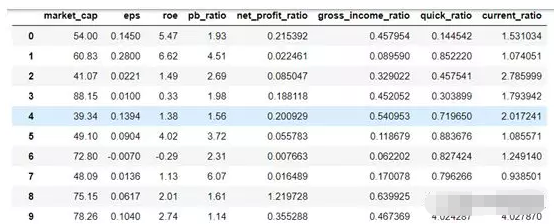
1. 获取数据:(鉴于篇幅仅展示2012-03-04当日前十支股票数据)
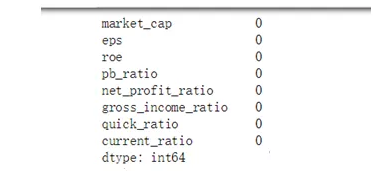
2. 缺失值检验:(鉴于篇幅仅展示2013-03-04当日检验情况)
返回0代表无缺失值,返回其他数字代表缺失值数量
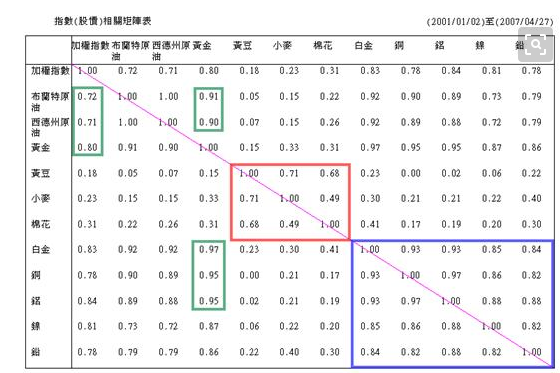
3. 被检验两两特征间线性相关性预了解(图例,鉴于篇幅仅展示2013-03-04当日检验情况)
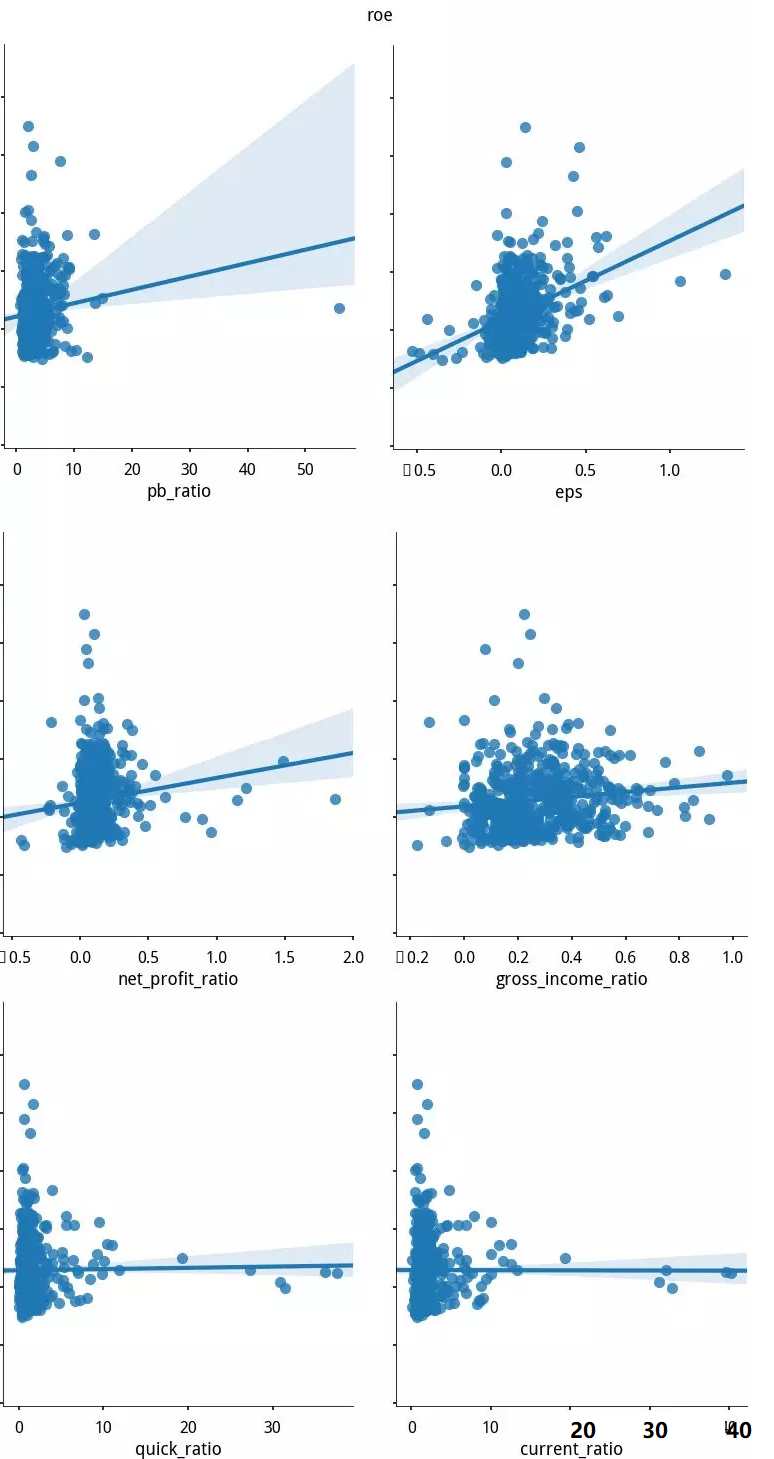
案例图表示,各特征对市值特征market_cap的解释能力
蓝色阴影部分,是回归直线斜率95%的置信区间
4. 计算并获取每个时点下被解释特征与其余7个特征之间的回归VIF值,绘制时间序列图

分别是百分比堆积图,和绝对数值图(柱状图)。通过百分比堆积图可以看出,各因子的VIF值全程比较稳定,所以其占据总体的百分比也稳定。柱状图可以看出各因子值细节。
5. 全段测试计算时间内,各特征VIF值均值,比较大小(图例)
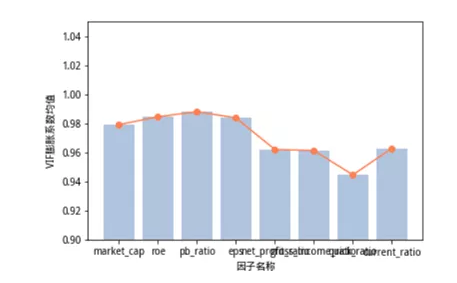
6. 相比而言quick_ratio这一特征的VIF在窗口期平均值较低,因而这就提示了我们如果在构建模型时,采用其余其中特征时可以考虑添加这一特征,增强模型的解释能力。
4.方法总结与体会
使用VIF进行检验的方法主要为,对某一特征和其余特征进行回归,得到R^2,计算VIF,剔除因子中VIF高的特征,保留VIF较低的特征,以此类推,直到得到一个相关性较低的特征组合来增强模型的解释能力。
在实际测试过程中,并非要指定一个VIF阈值,比如某特征的VIF值超过阈值才剔除,而是通过观察所有特征的VIF值,如果发现该值较大(显著离群),剔除该特征即可。
本次我们的几个特征表现都非常出色,VIF值稳定且没有离群较大值,因此,没能找到任何一个需要剔除的特征。
可决系数R^2和方差膨胀因子VIF的更多相关文章
- Variance Inflation Factor (VIF) 方差膨胀因子解释_附python脚本
python信用评分卡(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_camp ...
- R语言建立回归分析,并利用VIF查看共线性问题的例子
R语言建立回归分析,并利用VIF查看共线性问题的例子 使用R对内置longley数据集进行回归分析,如果以GNP.deflator作为因变量y,问这个数据集是否存在多重共线性问题?应该选择哪些变量参与 ...
- R语言学习笔记:因子
R语言中的因子就是factor,用来表示分类变量(categorical variables),这类变量不能用来计算而只能用来分类或者计数. 可以排序的因子称为有序因子(ordered factor) ...
- R WLS矫正方差非齐《回归分析与线性统计模型》page115
rm(list = ls()) A = read.csv("data115.csv") fm = lm(y~x1+x2,data = A) coef(fm) A.cooks = c ...
- R语言学习笔记:因子(Factors)
因子提供了一个简单并且紧凑的形式来处理分类(名义上的)数据.因子用”水平level”来表示所有可能的取值.如果数据集有取值个数固定的名字变量,因子就特别有用. > g<-c("f ...
- 可决系数R^2和MSE,MAE,SMSE
波士顿房价预测 首先这个问题非常好其实要完整的回答这个问题很有难度,我也没有找到一个完整叙述这个东西的资料,所以下面主要是结合我自己的理解和一些资料谈一下r^2,mean square error 和 ...
- R语言之多重共线性的判别以及解决方法
多重共线性(Multicollinearity)是指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确. 1.可以计算X矩阵的秩qr(X)$rank,如果 ...
- 【R】多元线性回归
R中的线性回归函数比较简单,就是lm(),比较复杂的是对线性模型的诊断和调整.这里结合Statistical Learning和杜克大学的Data Analysis and Statistical I ...
- R语言与概率统计(三) 多元统计分析(中)
模型修正 #但是,回归分析通常很难一步到位,需要不断修正模型 ###############################6.9通过牙膏销量模型学习模型修正 toothpaste<-data. ...
随机推荐
- AJAX向Django后端提交POST请求
一.ajax登录示例 二.CSRF跨站请求伪造 方式一 方式二 方式三 方式四 一.ajax登录示例 urls.py from django.conf.urls import url from dja ...
- JS获取select被选中的option的值
一:JavaScript原生的方法 1:拿到select对象: var myselect=document.getElementById(“test”); 2:拿到选中项的索引:var index=m ...
- Python编程之列表操作实例详解【创建、使用、更新、删除】
Python编程之列表操作实例详解[创建.使用.更新.删除] 这篇文章主要介绍了Python编程之列表操作,结合实例形式分析了Python列表的创建.使用.更新.删除等实现方法与相关操作技巧,需要的朋 ...
- zabbix添加主机后无法显示解决
第一次添加主机后显示正常,后来删除了主机,重新添加了一下主机再也无法显示主机,很苦恼,原来需要点击重设,
- TCP中SYN洪水攻击
在查看TCP标识位SYN时,顺便关注了一下SYN Flood,从网上查阅一些资料加以整理,SYN洪水攻击利用TCP三次握手. 1.SYN洪水介绍 当一个系统(客户端C)尝试和一个提供了服务的系统(服务 ...
- 【MM系列】SAP PO增强BADI
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[MM系列]SAP PO增强BADI 前言部 ...
- Windows.命令行(CMD)_执行命令&环境变量
1.CMD命令中如果 命令有换行的话,就使用 ^来连接(这就类似于 Linux命令行中 \ 的作用) 2.环境变量 2.1.显示 所有环境变量的值,命令:set 2.2.显示 某个环境变量的值,命令 ...
- Sql注入校验
/// <summary> /// Sql注入校验 /// </summary> /// <param name="listWord">字符&l ...
- MySQL的count(*)性能怎么样?
对于count(主键id)来说,innodb引擎会遍历整张表,把每一行的id值都取出来,返回给server层,server层判断id值不为空,就按行累加 对于count(1)来说,innodb引擎遍历 ...
- call 和 apply的定义和区别?
1.方法定义 call方法: 语法:call([thisObj[,arg1[, arg2[, [,.argN]]]]]) 定义:调用一个对象的一个方法,以另一个对象替换当前对象. 说明: call ...