【笔记】机器学习 - 李宏毅 - 13 - Why Deep
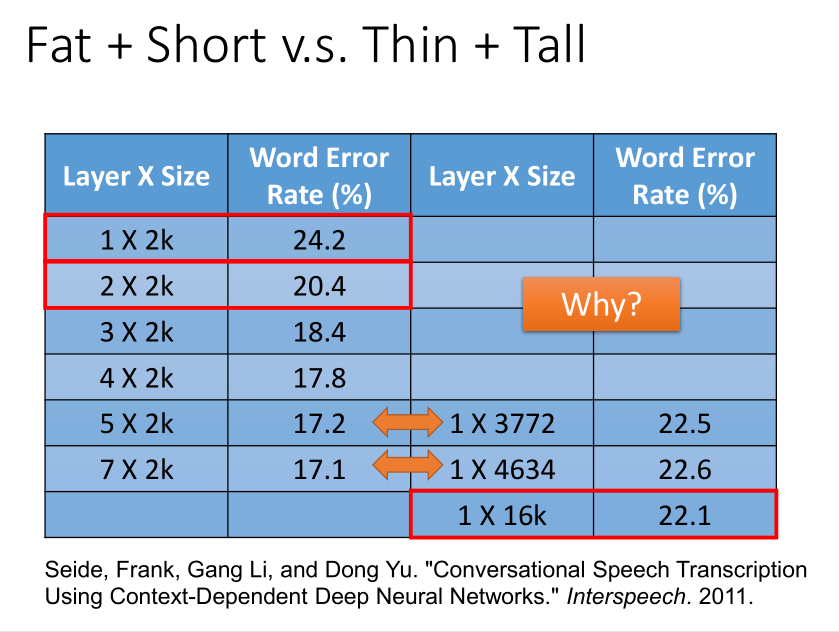
当参数一样多的时候,神经网络变得更高比变宽更有效果。为什么会这样呢?
其实和软件行业的模块化思想是一致的。
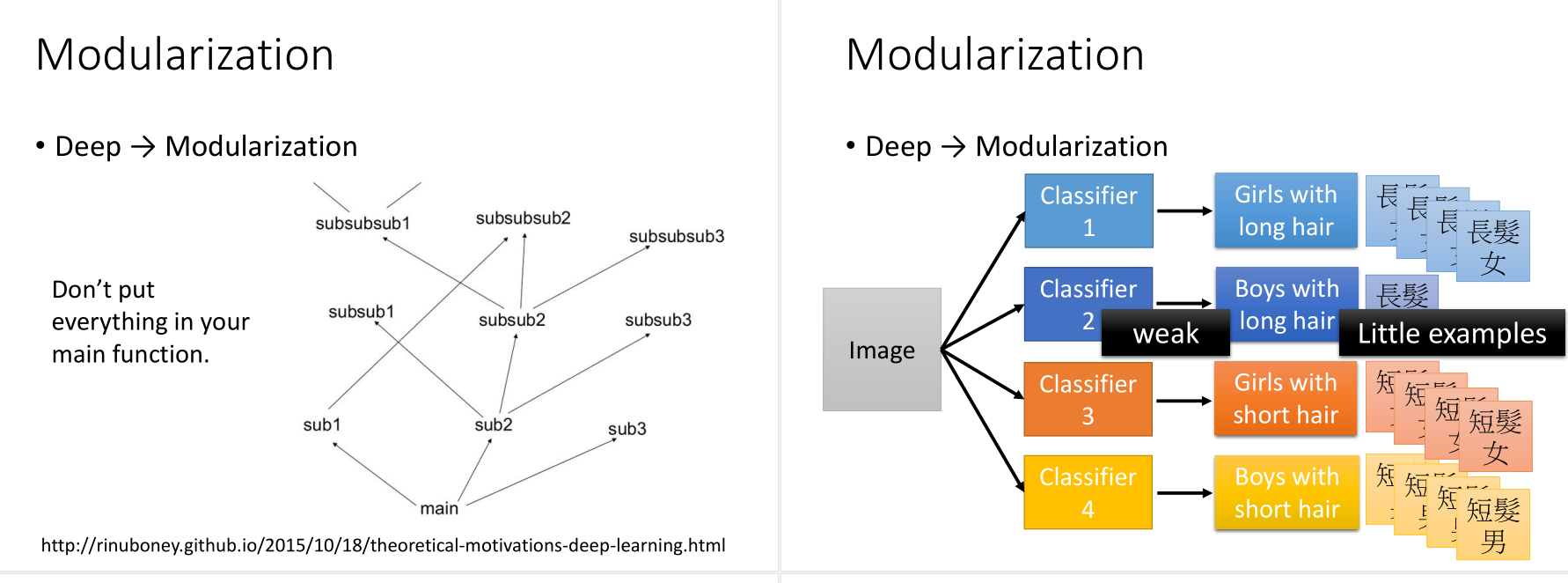
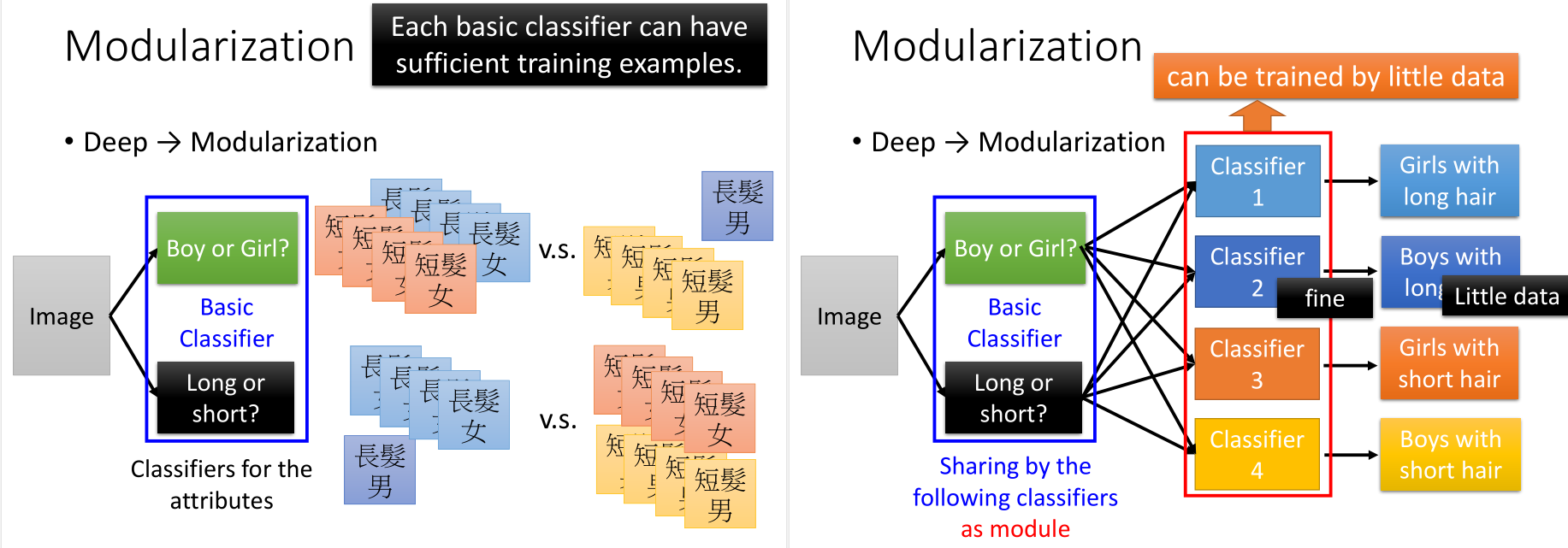
比如,如果直接对这四种分类进行训练,长发的男孩数据较少,那么这一类训练得到的classifier不是很好。
但如果分成长发or短发,男孩or女孩,这两种基分类器,那么数据就是足够的,可以得到很好的结果。这样的话,其实用比较少的数据就可以得到很好地分类结果。
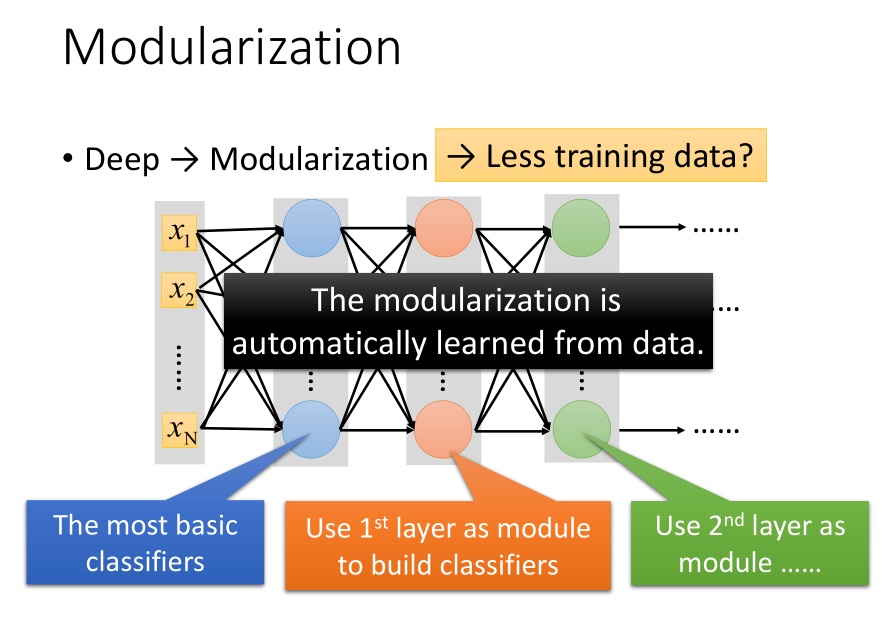
模组化这个事情机器是可以自动学到的。
图像应用

语音应用
第一步要做的事情就是把acoustic feature转成state,再把state转成phoneme,再转成文字。
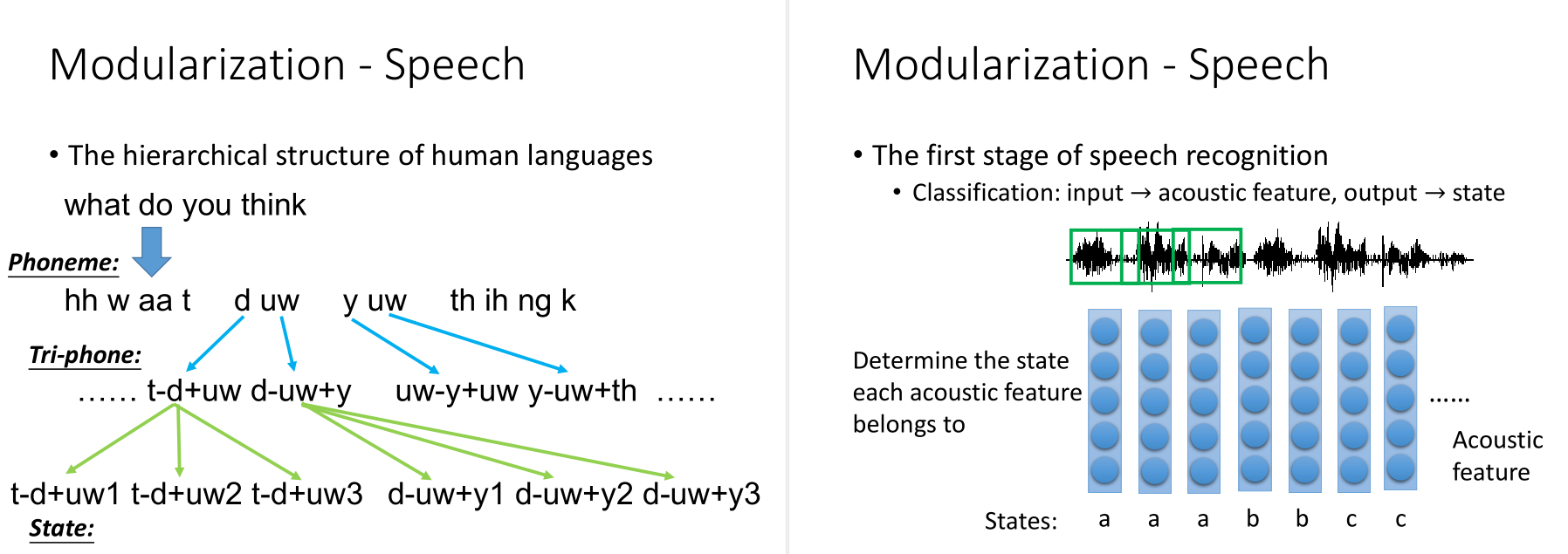
传统的HMM-GMM方法,给你一个feature,你就可以说每一个acoustic feature从每一个state产生出来的几率。
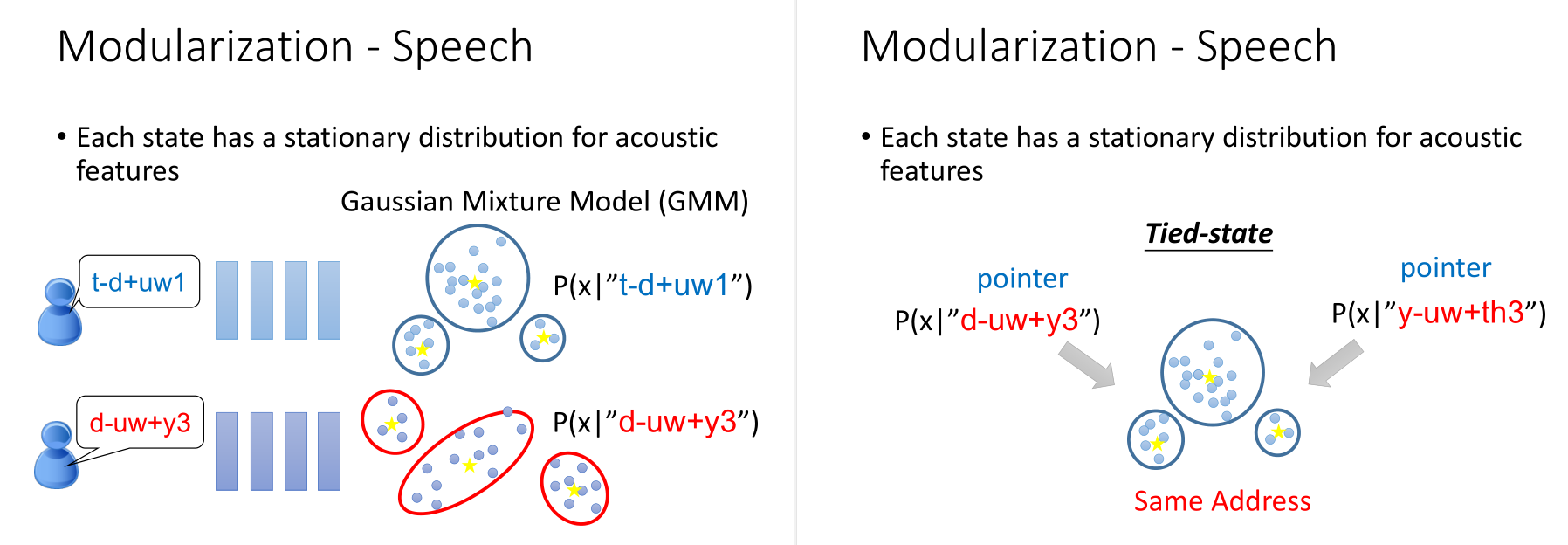
但是每一个state都要用Gaussian Mixture Model来描述,参数太多了。
有一些state,他们会共用同一个model distribution,这件事叫做Tied-state。是否共用,需要借助知识。
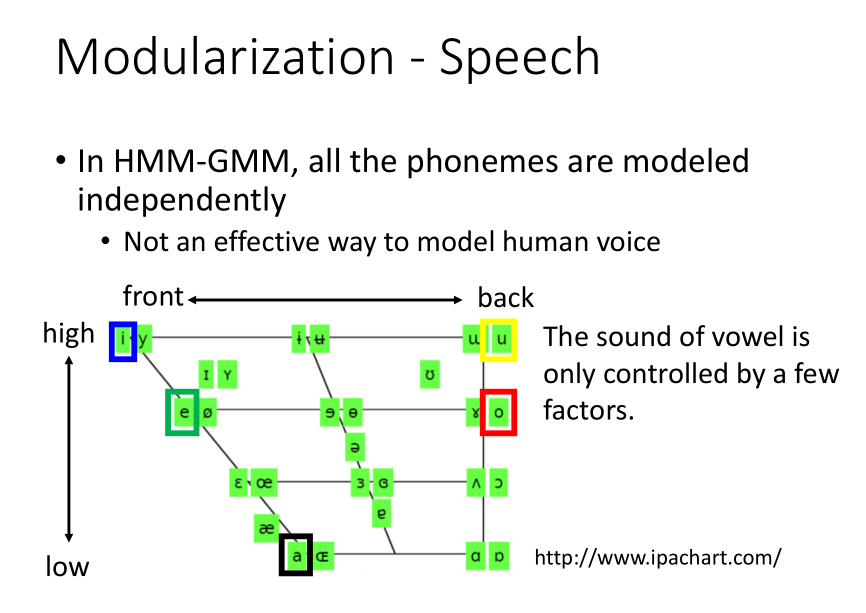
HMM-GMM的方式,所有的state是independently的,没有一个effective的方法来model人声。
不同的phoneme之间其实是有关系的,如果说每个phoneme都搞一个model,这件事是没有效率的。
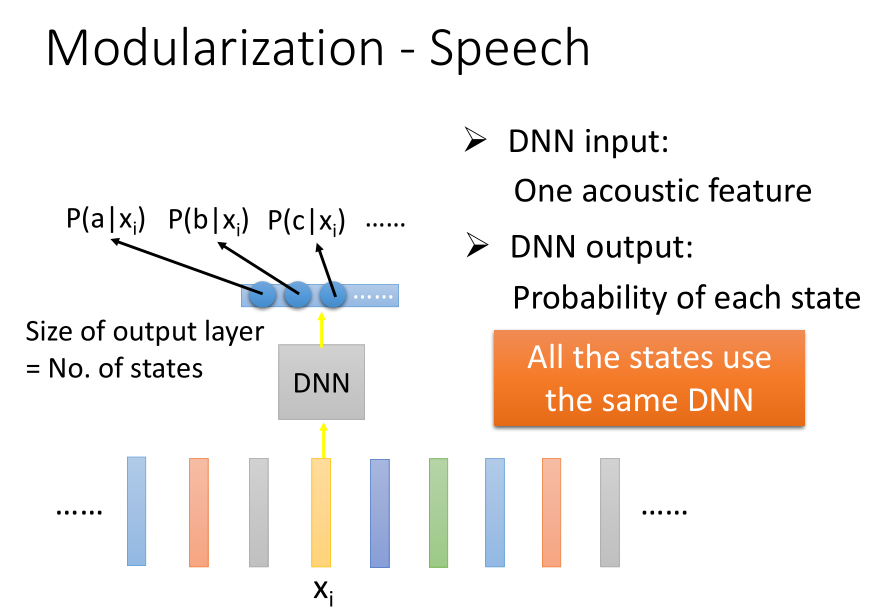
DNN的方法,input是一个acoustic feature,output是acoustic feature属于每个state的几率。
最关键的一点是所有的state都共用同一个DNN,并没有为每一个state产生一个DNN。
虽然DNN的参数很多,但并不是因为参数多所以比GMM好,因为GMM的每一个phoneme都有一个model,参数加起来可能比DNN还要多。
两种方法比较:
DNN做的事情在比较低层的时候,它并不是马上去侦测这个发音是属于哪个state。
它的做事是它先观察(detector)说,当你听到这个发音的时候,人是用什么方式在发这个声音的。(模组化)
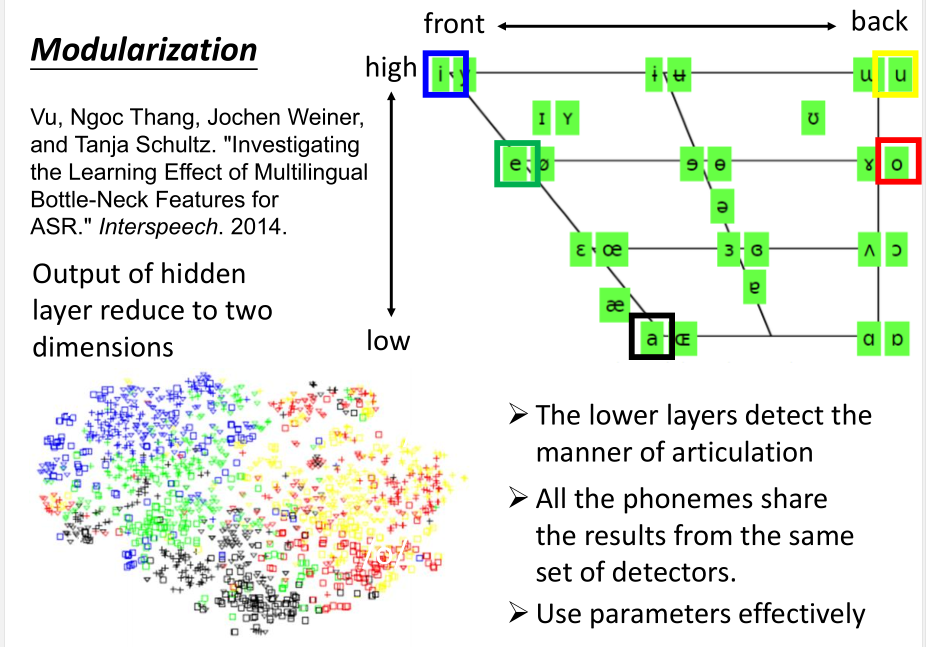
普遍性原理:
过去的理论说,任何的continuous function,都可以用一层来完成。但这种模型效率并不高。
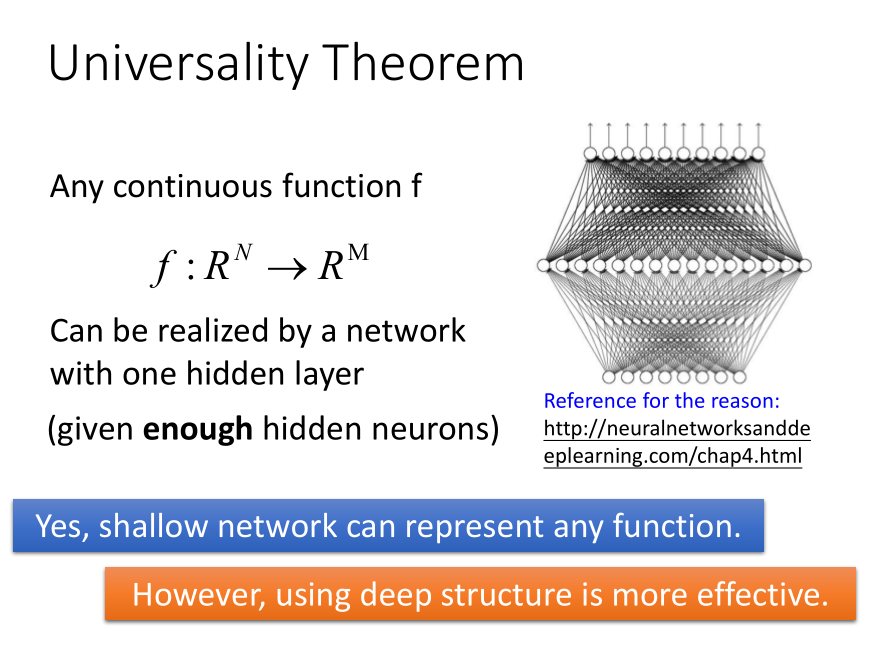
逻辑电路和逻辑闸的例子,后边做的是奇偶校验。
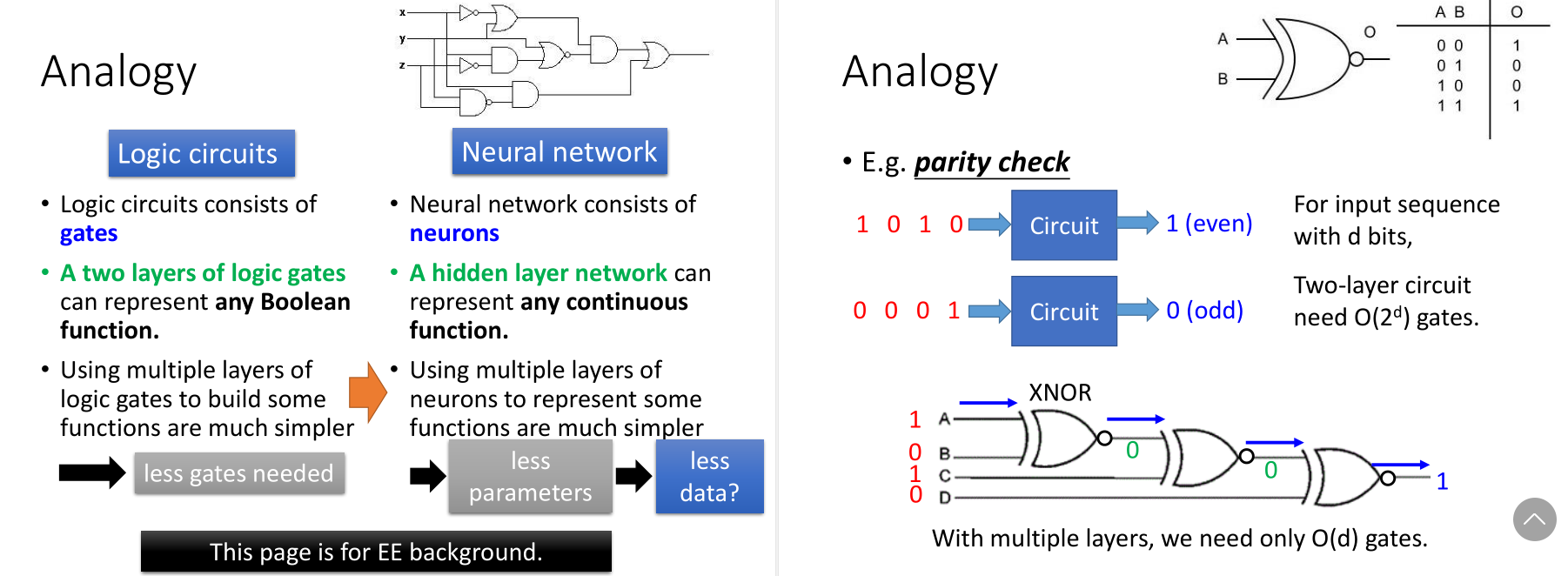
还有个形象的例子就是剪窗花,右图的features transformation和它是一个道理。
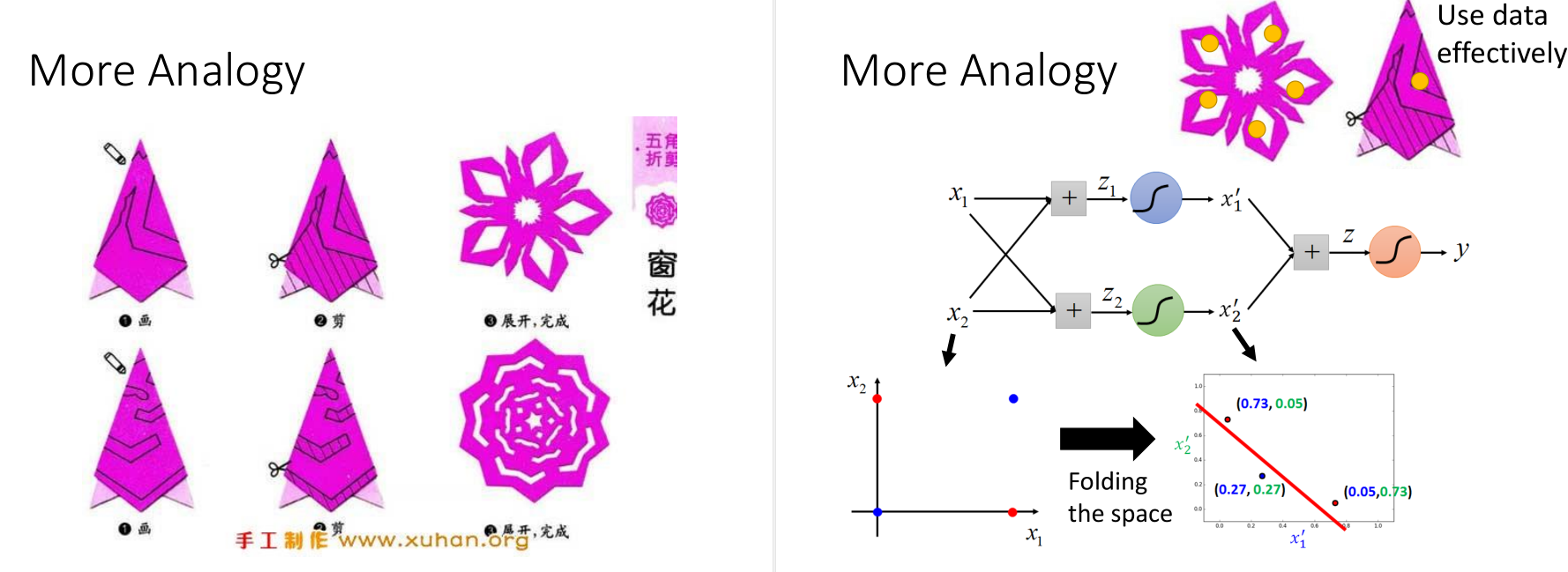
二维坐标的例子。

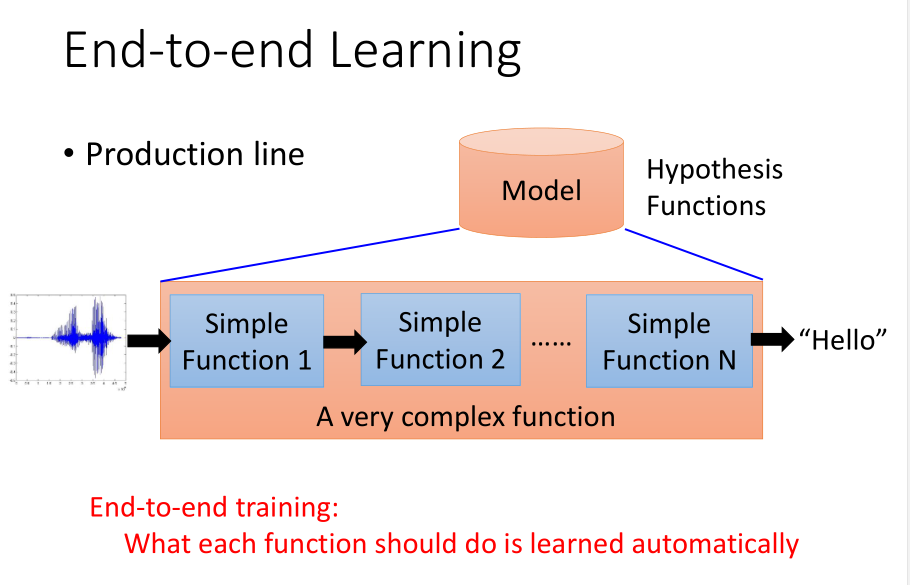
End to End Learning
深度学习的一个好处就是,我们可以做End-to-end learning。
就是说只要给model input和output,不用告诉它每层function要咋样分工,让它自己去学中间每一个function。
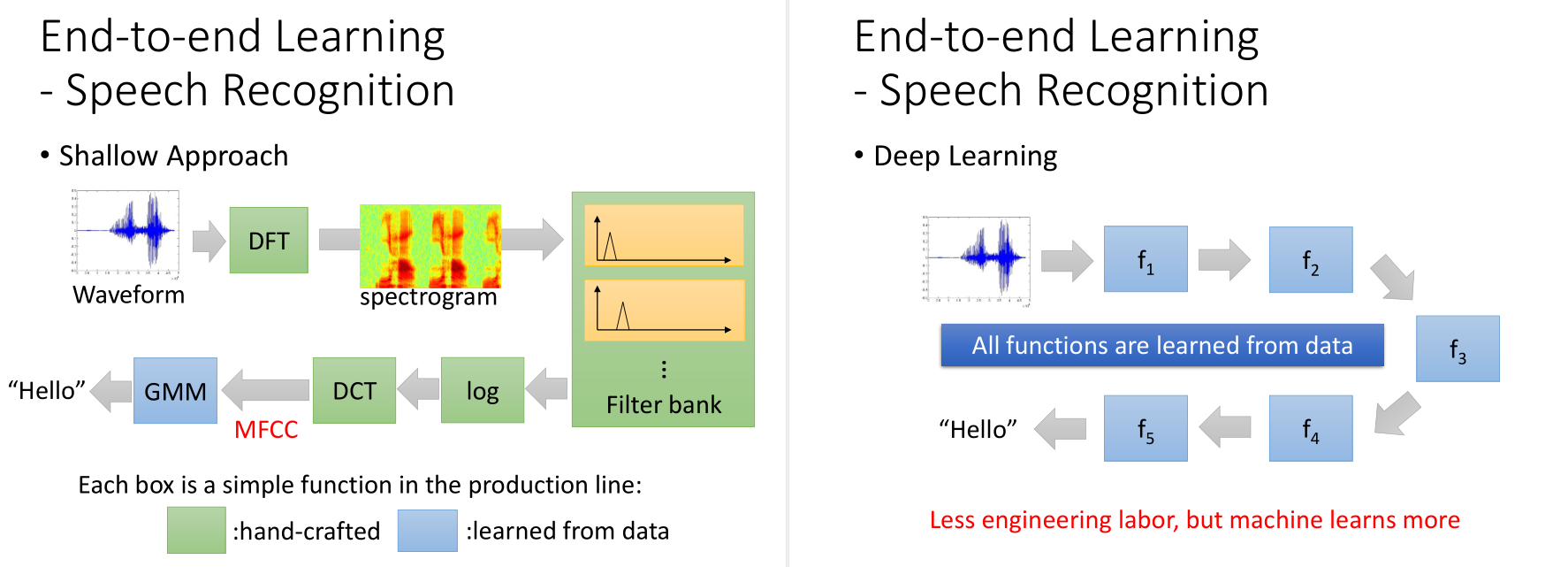
对于语音识别问题,DNN的方法得到的结果,和传统方法中最好的MFCC可以持平。
图像识别的问题也是一样。

还有,对于复杂问题,一层是远远不够的。
对于语音识别来说,看起来每个人说的很不一样,但当到第八层时,不同的人说的同样的句子,它自动的被line在一起了。

对于手写数字识别,到了第三层时,就可以很好地分开了。

【笔记】机器学习 - 李宏毅 - 13 - Why Deep的更多相关文章
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- 深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE
深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE 201 ...
- Andrew Ng机器学习课程13
Andrew Ng机器学习课程13 声明:引用请注明出处http://blog.csdn.net/lg1259156776/ 引言:主要从一般的角度介绍EM算法及其思想,并推导了EM算法的收敛性.最后 ...
- 《深入Java虚拟机学习笔记》- 第13章 逻辑运算
<深入Java虚拟机学习笔记>- 第13章 浮点运算
- 【论文笔记】Malware Detection with Deep Neural Network Using Process Behavior
[论文笔记]Malware Detection with Deep Neural Network Using Process Behavior 论文基本信息 会议: IEEE(2016 IEEE 40 ...
- 《从零开始学Swift》学习笔记(Day 13)——数据类型之整型和浮点型
Swift 2.0学习笔记(Day 13)——数据类型之整型和浮点型 原创文章,欢迎转载.转载请注明:关东升的博客 Swift提供8.16.32.64位形式的有符号及无符号整数.这些整数类型遵循 ...
- 【笔记】机器学习 - 李宏毅 - 7 - Deep Learning
深度学习发展历史: 感知机和逻辑回归很像,只是没有\(sigmoid\)激活函数. 深度学习训练的三个步骤: Step1:神经网络(Neural network) Step2:模型评估(Goodnes ...
- 机器学习笔记P1(李宏毅2019)
该博客将介绍机器学习课程by李宏毅的前两个章节:概述和回归. 视屏链接1-Introduction 视屏链接2-Regression 该课程将要介绍的内容如下所示: 从最左上角开始看: Regress ...
- R语言学习笔记-机器学习1-3章
在折腾完爬虫还有一些感兴趣的内容后,我最近在看用R语言进行简单机器学习的知识,主要参考了<机器学习-实用案例解析>这本书. 这本书是目前市面少有的,纯粹以R语言为基础讲解的机器学习知识,书 ...
随机推荐
- nginx+lua在我司的实践
导读:nginx是一个高性能的反向代理服务器,lua是一个小巧的脚本语言,这两个的巧妙结合会擦出怎样的火花呢. 关键词:nginx,lua,nginx+lua 前言 nginx,lua,nginx+l ...
- wordpress 如何正确升级
http://www.admin5.com/article/20141230/578710.shtml 正确的版本升级应该是,备份数据库和文件,然后禁用所有的插件后在执行升级.这样也避免不了升级过后启 ...
- BZOJ1257 [CQOI2007]余数之和 (数论分块)
题意: 给定n, k,求$\displaystyle \sum_{i=1}^nk\;mod\;i$ n,k<=1e9 思路: 先转化为$\displaystyle \sum_{i=1}^n(k- ...
- CyclicBarrier与CountDownLatch区别
阻塞与唤醒方式的区别 CountDownLatch计数方式 CountDownLatch是减计数.调用await()后线程阻塞.调用countDown()方法后计数减一,当计数为零时,调用await( ...
- new 的实现原理
自己封装一个new <script> // 创建一个构造函数 function Father() { this.name = '小红'; this.eat = function () { ...
- 手把手带你阅读Mybatis源码(一)构造篇
前言 今天会给大家分享我们常用的持久层框架——MyBatis的工作原理和源码解析,后续会围绕Mybatis框架做一些比较深入的讲解,之后这部分内容会归置到公众号菜单栏:连载中…-框架分析中,欢迎探讨! ...
- 极简估值教程——第一篇 速判估值与PEG的推导
来自盛京剑客的雪球原创专栏 一.极简速判估值怎么判? 很简单.简单到粗暴. 用PEG PEG=PE/(g*100)=1.0 什么意思? PE市盈率,g未来收益增长率,PEG为1.0合理估值,大于1.0 ...
- VFP 的 SPT 起跳 -- 陈纯(BOE数据网络工作室)
细节描述 Visual FoxPro 的 SPT 技术快速入门 说在前面熟悉 Fox 的朋友都知道,在 VFP 里我们可以使用远程视图 (Remote View) 和 SPT(SQL Pass Thr ...
- 《自拍教程14》Linux的常用命令
Linux操作系统, 包括我们大家熟知的Android, Ubuntu, Centos, Red Hat, UOS等. 这些常用命令先大概了解下,当然能熟练掌握并运用到实际工作中那最好不过了. 后续技 ...
- filebeat+kafka
kafka出现接收不到filebeat数据,最后发现版本兼容问题 filebeat换成 filebeat-7.4.2-linux-x86_64 kafka是docker-compose启动的,版本是 ...