CVPR 2016 paper reading (6)
1. Neuroaesthetics in fashion: modeling the perception of fashionability, Edgar Simo-Serra, Sanja Fidler, Francesc Moreno-Noguer, Raquel Urtasun, in CVPR 2015.
Goal: learn and predict how fashionable a person looks on a photograph, and suggest subtle improvements that user could make to improve her/his appeal.
This paper proposes a Conditional Random Field model that jointly reasons about several fashionability factors such as the type of outfit (全套装备) and garments (衣服) the user is wearing, the type of the user, the photograph's setting (e.g., the scenery behind the user), and the fashionability score.
Importantly, the proposed model is able to give rich feed back to the user, conveying which garments or even scenery she/he should change in order to improve fashionability.

This paper collects a novel dataset that consists of 144,169 user posts from a clothing-oriented social website chictopia.com. In a post, a user publishes one to six photographs of her/himself wearing a new outfit. Generally each photograph shows a different angle of the user or zoons in on different garments. User sometimes also add a description of the outfit, and/or tags of the types and colors of the garments they are wearing.

Discovering fashion from weak data:
The energy of the CRF as a sum of energies encoding unaries for each variable as well as non-parametric pairwise pothentials which reflect the correlations between the different random variables:
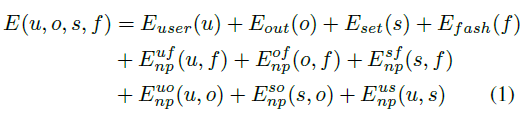
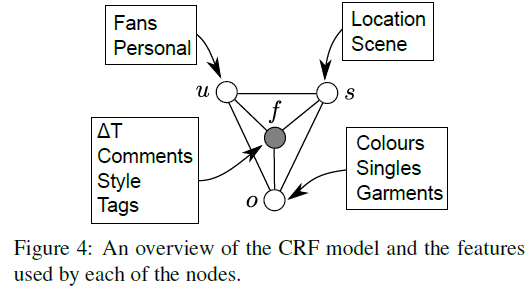
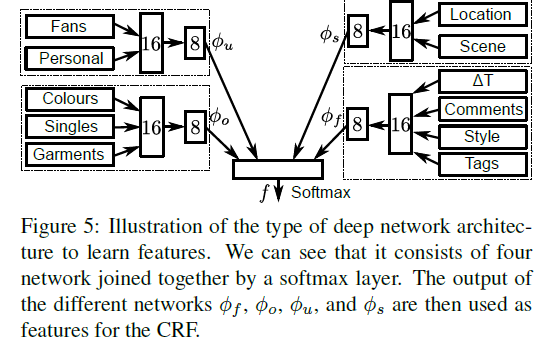
User specific features:
- the logarithm of the number of fans
- use rekognition to compute attributes of all the images of each post, keep the features for the image with the highest score.
Then compute the unary potentials as the output of a small neural network, produce an 8-D feature map.
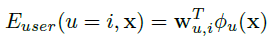
Outfit features:
bag-of-words approach on the "garments" and "colours" meta-data

Setting features:
- the output of a pre-trained scene classifier (multi-layer perceptron, whose input is CNN feature)
- user-provided location: look up the latitude and longitude of the user-provided location, project all the values on the unit sphere, and add some small Guassian noise. Then perform unsupervised clustering using the geodesic distances, and use the geodesic distance from each cluster center as a feature.
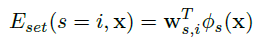
Fashion:
- delta time: the time between the creation of the post and when the post was crawled as a feature
- bag-of-words on the "tag"
- comments: parse the comments with the sentiment-analysis model, which can predict how positive a review is on a 1- 5 scale, sum the scores for each post.
- style: style classifier pretrained on Flickr80K.
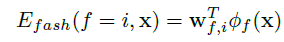
Correlations:
use a non-parametric function for each pairwise and let the CRF learn the correlations:
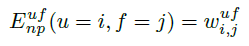
Similarly for the other pairwise potentials.
Learn and Inference:
First jointly train the deep networks that are used for feature extraction to predict fashionablity, and estimate the initial latent states using clustering.
Then learn the CRF model using the primal-dual method.
CVPR 2016 paper reading (6)的更多相关文章
- CVPR 2016 paper reading (2)
1. Sketch me that shoe, Qian Yu, Feng Liu, Yi-Zhe Song, Tao Xiang, Timothy M. Hospedales, Cheng Chan ...
- CVPR 2016 paper reading (3)
DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations, Ziwei Liu, Pin ...
- 浅析"Sublabel-Accurate Relaxation of Nonconvex Energies" CVPR 2016 Best Paper Honorable Mention
今天作了一个paper reading,感觉论文不错,马克一下~ CVPR 2016 Best Paper Honorable Mention "Sublabel-Accurate Rela ...
- (转)CVPR 2016 Visual Tracking Paper Review
CVPR 2016 Visual Tracking Paper Review 本文摘自:http://blog.csdn.net/ben_ben_niao/article/details/52072 ...
- Paper Reading: In Defense of the Triplet Loss for Person Re-Identification
In Defense of the Triplet Loss for Person Re-Identification 2017-07-02 14:04:20 This blog comes ...
- Paper Reading: Stereo DSO
开篇第一篇就写一个paper reading吧,用markdown+vim写东西切换中英文挺麻烦的,有些就偷懒都用英文写了. Stereo DSO: Large-Scale Direct Sparse ...
- 深度视觉盛宴——CVPR 2016
小编按: 计算机视觉和模式识别领域顶级会议CVPR 2016于六月末在拉斯维加斯举行.微软亚洲研究院在此次大会上共有多达15篇论文入选,这背后也少不了微软亚洲研究院的实习生的贡献.大会结束之后,小编第 ...
- Paper Reading - Deep Visual-Semantic Alignments for Generating Image Descriptions ( CVPR 2015 )
Link of the Paper: https://arxiv.org/abs/1412.2306 Main Points: An Alignment Model: Convolutional Ne ...
- Paper Reading - Mind’s Eye: A Recurrent Visual Representation for Image Caption Generation ( CVPR 2015 )
Link of the Paper: https://ieeexplore.ieee.org/document/7298856/ A Correlative Paper: Learning a Rec ...
随机推荐
- SSRS使用MySql作为数据源遇到的问题。
因为工作需求,SSRS需要取到MySql数据源,还好有了ODBC. 谷歌了很多,都是不完整的Solution,放上完整版的供大家评价参考. 下面是StepByStep. 问题1.使用ODBC数据源,填 ...
- Eclipse提示workspaces is use
问题描述: 有时候因为强行关闭Eclipse导致再次打开出现workspace提示正在使用 解决办法: 删除workspace目录下隐藏文件夹 .metadata 中的 .lock 文件 worksp ...
- 虚拟机下centos时间不正确的方便解决方法
就是用NTP了,通过外部的服务同步时间. ntpdate us.pool.ntp.org | logger -t NTP 如果没有ntpdate ,可以使用 yum install ntpdate 进 ...
- 一 NIO的概念
Java NIO由下列几个核心部分组成: Channels(通道) Buffers(缓冲区) Asynchronous IO(异步IO) Channel 和 Buffer 基本上所有的IO在NIO中都 ...
- dokcer安装并开机自启动服务
linux内核最好是3.10以上.不过本次使用的是centos6.5 内核2.6 1.yum -y install docker-io 如果出现: 需要安装yum源: 3.service docker ...
- Java内存溢出定位和解决方案(new)
引起内存溢出的原因有很多种,列举一下常见的有以下几种: 1.内存中加载的数据量过于庞大,如一次从数据库取出过多数据:2.集合类中有对对象的引用,使用完后未清空,使得JVM不能回收:3.代码中存在死循环 ...
- SPOJ QTREE7
题意 一棵树,每个点初始有个点权和颜色 \(0 \ u\) :询问所有\(u,v\) 路径上的最大点权,要满足\(u,v\) 路径上所有点的颜色都相同 $1 u \(:反转\)u$ 的颜色 \(2 ...
- var a =10 与 a = 10的区别
学习文章------汤姆大叔-变量对象 总结笔记 变量特点: ①变量声明可以存储在变量对象中.②变量不能直接用delete删除. var a =10 与 a = 10的区别: ①a = 10只是为全局 ...
- 初识shell expect
场景:工作中经常会遇到shell脚本写的连接脚本,所以稍微了解下. 一.shell Shell 是一个用C语言编写的程序,它是用户使用Linux的桥梁.Shell既是一种命令语言,又是一种程序设计语言 ...
- React Native之React速学教程(中)
概述 本篇为<React Native之React速学教程>的第一篇.本篇将从React的特点.如何使用React.JSX语法.组件(Component)以及组件的属性,状态等方面进行讲解 ...