caffe web demo运行+源码分析
caffe web demo学习
1、运行
安装好caffe后,进入/opt/caffe/examples/web_demo/的caffe web demo项目目录,查看一下app.py文件,这是一个flask编写的网站
查看readme.md了解该项目,查看requirements.txt了解所需的python包
然后运行该项目:python app.py,发现报错
class_labels_file is missing
网上说还需要下载一些data,运行下面两条命令:
确保已经下载了 Reference CaffeNet Model 和 the ImageNet Auxiliary Data:
python opt/caffe/scripts/download_model_binary.py models/bvlc_reference_caffenet
opt/caffe/data/ilsvrc12/get_ilsvrc_aux.sh
然后再运行该项目:python app.py
在127.0.0.1:5000查看
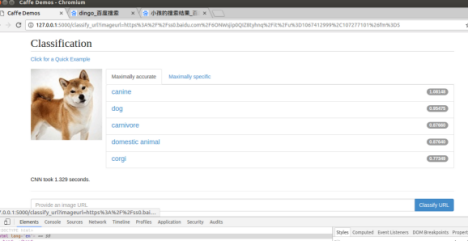
2、app.py源码分析
这个web demo使用了在ilsvrc2012比赛的数据集上训练得到的模型。
模型已经预先训练好,并给出了模型的网络结构文件deploy.prototxt,训练好的模型文件bvlc_reference_caffenet.caffemodel,训练数据的均值文件ilsvrc_2012_mean.npy(需要它是因为需要对测试数据去均值),标签序号与标签内容的对应文件synset_words.txt,与原始数据集结构有关的imagenet.bet.pickle
其中网络结构文件、训练好的模型文件、均值文件会被输入到caffe.Classifier里用来构造分类器,标签序号与标签内容文件用来在网页上给显示结果。
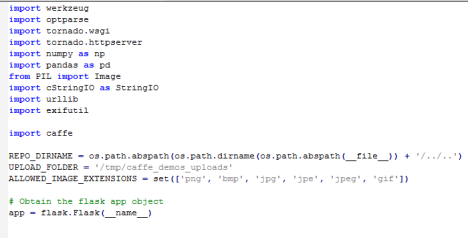
1)index函数

2)classify_url函数
读取url,urllib.urlopen().read()打开url并读取出二进制字节流(python3中为urllib.request.urlopen().read()),caffe.io.load_image()转换为caffe能接受的格式,输出日志,调用classify_image识别图片,将识别结果和imageurl渲染回html显示给用户
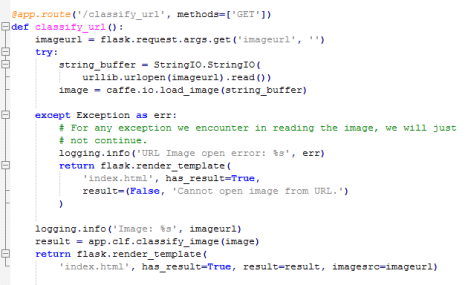
3)classify_upload函数
获取上传的图片,在文件名前插入时间以区分不同文件,将文件保存到服务器,输出日志,调用classify_image识别图片,将识别结果和图片(以base64编码的形式)渲染回html显示给用户
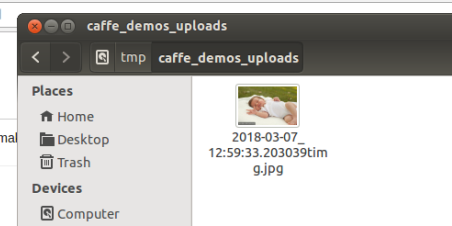
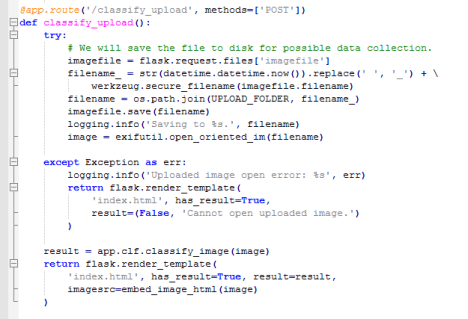
4)embed_image_html函数
为3)服务,读取文件返回base64编码

5)allowed_file函数
检查文件后缀名是否在可接受的类型中(这个函数在app.py中并没有被调用,不知道为什么)

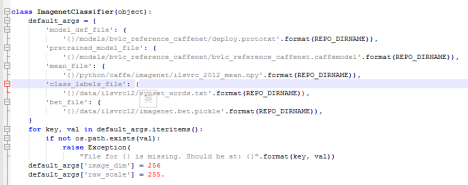
6)ImagenetClassifier内部类
定义了5个默认参数:模型的网络结构文件deploy.prototxt,训练好的模型文件bvlc_reference_caffenet.caffemodel,训练数据的均值文件ilsvrc_2012_mean.npy(需要它是因为需要对测试数据去均值),标签序号与标签内容的对应文件synset_words.txt,与原始数据集结构有关的imagenet.bet.pickle
for循环验证了这些文件存不存在,不存在的话报错(安装过程中的报错就是这里抛出的)
定义了2个默认参数,image_dim表示???,raw_scale表示???
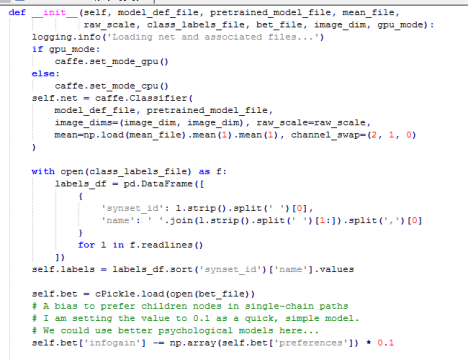
初始化指定识别使用cpu还是gpu
初始化分类器:caffe.Classifier,接收上面定义的模型的网络结构文件deploy.prototxt,训练好的模型文件bvlc_reference_caffenet.caffemodel,训练数据的均值文件ilsvrc_2012_mean.npy(需要它是因为需要对测试数据去均值)三个参数
。。。。。。。
在7)中
app.clf = ImagenetClassifier(**ImagenetClassifier.default_args)
app.clf.net.forward()
两句代码执行完之后,我们实际上就创建并训练好我们的分类器了。
然后我们调用net.predict函数,将caffe.io.load_image得到的图片传进去,就可以进行识别,并返回一个numpy.ndarray类型的最后一层(输出层)的结果。
net.predict完之后,识别的中间结果也已经存在app.clf.net中了,只需要调用net.blobs['layer名'].data就可以获取到numpy.ndarray类型的中间结果了。
predict时的oversample表示过取样,默认为true
ndarray.shape可以获取ndarray数组的形状,更多源于numpy.ndarray数组的信息见这篇https://docs.scipy.org/doc/numpy/reference/generated/numpy.ndarray.html
ndarray.flatten表示把ndarray多维数组展开成一维ndarray数组,见这篇https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.ndarray.flatten.html
ndarray数组前面加负号表示对每个元素取负值
ndarray.argsort不改变原数组,并返回原数组值从小到大的索引值,示例如下,或见这篇http://blog.csdn.net/maoersong/article/details/21875705
>>> x = np.array([3, 1, 2])
>>> np.argsort(x)
array([1, 2, 0])
个人通过加了如下几行代码看了一下这个模型各层结果的格式:(在使用logging.info的过程中注意,logging.info的输出要通过%s来占位,不同于print可直接输出)
# add by zss
# logging.info('classifier.predict.faltten:%s',list(scores))
# logging.info('classifier.predict:%s',list(self.net.predict([image],oversample=True)))
logging.info('########################:%s',list(self.net.blobs['fc8'].data[1]))
如下:
predict函数返回的最后一层(prob层)的结果格式为1*1000的概率数组(值在0-1之间)
‘fc8’层的结果,格式为10*1000的概率数组(值在0-1之间)
分析:
prob层和fc8层的结果对应着1000个标签,含义是该图片是该标签的概率。
fc8层有10个长度1000的数组是因为我们在定义模型(caffe.Classifier())时,对oversample选项采用了默认值true,开启了过取样,相当于将每张图片经过旋转和镜像对称变成了10张相同的图片,所以fc8层有10个结果,然后prob层将这10个结果综合得到了最终结果1*1000的概率数组),关于oversample过取样见这篇http://blog.csdn.net/guoyilin/article/details/42886365
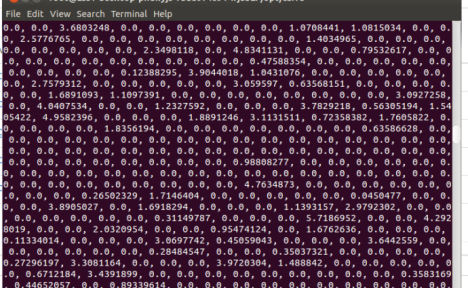
‘fc7’层的结果,格式为10*4096的foat数组(值可能大于1),形如下图
分析:
fc7层的结果对应着输入的那一张图片,经过过取样后的10张图片,各自的4096个特征的值

7)start_tornado函数
为8)服务,启动flask服务器
不太明白,为什么要用tornado的函数启动flask服务器?
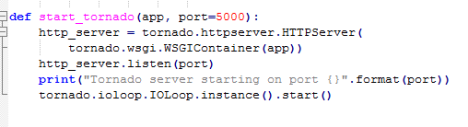
8)start_from_terminal函数
为9)服务,使用optparse定义了一些参数debug,port,gpu,用来控制debug模式是否打开,flask运行的端口,gpu模式还是cpu模式,运行flask的端口号,然后调用7)启动flask服务器

9)命令行启动
设置log级别,创建用来存储用户上传的图片的临时文件夹,调用8)
caffe web demo运行+源码分析的更多相关文章
- lesson2:java阻塞队列的demo及源码分析
本文向大家展示了java阻塞队列的使用场景.源码分析及特定场景下的使用方式.java的阻塞队列是jdk1.5之后在并发包中提供的一组队列,主要的使用场景是在需要使用生产者消费者模式时,用户不必再通过多 ...
- Bytom Dapp 开发笔记(三):Dapp Demo前端源码分析
本章内容会针对比原官方提供的dapp-demo,分析里面的前端源码,分析清楚整个demo的流程,然后针对里面开发过程遇到的坑,添加一下个人的见解还有解决的方案. 储蓄分红合约简述 为了方便理解,这里简 ...
- lesson1:threadlocal的使用demo及源码分析
本文中所使用的demo源码地址:https://github.com/mantuliu/javaAdvance 其中的类Lesson1ThreadLocal 本文为java晋级系列的第一讲,后续会陆续 ...
- cocos2D-x demo 的源码分析 #define ..##.. 的妙用.
最近在看cocos2d-x 但不知道如何下手,于是先看一下他编译的完成的testcpp的源码.发现了下面一段程序 typedef CCLayer* (*NEWTESTFUNC)(); #define ...
- ASimpleCache源码分析
ASimpleCache里只有一个JAVA文件——ACache.java,首先我用思维导图制作了ACache类的详细结构图: 通过分析官方给的demo来驱动源码分析吧 以字符串存储为例(官方给的dem ...
- ABP源码分析一:整体项目结构及目录
ABP是一套非常优秀的web应用程序架构,适合用来搭建集中式架构的web应用程序. 整个Abp的Infrastructure是以Abp这个package为核心模块(core)+15个模块(module ...
- spring AOP源码分析(一)
对于springAOP的源码分析,我打算分三部分来讲解:1.配置文件的解析,解析为BeanDefination和其他信息然后注册到BeanFactory中:2.为目标对象配置增强行为以及代理对象的生成 ...
- 移动web app开发必备 - Deferred 源码分析
姊妹篇 移动web app开发必备 - 异步队列 Deferred 在分析Deferred之前我觉得还是有必要把老套的设计模式给搬出来,便于理解源码! 观察者模式 观察者模式( 又叫发布者-订阅者模 ...
- 使用react全家桶制作博客后台管理系统 网站PWA升级 移动端常见问题处理 循序渐进学.Net Core Web Api开发系列【4】:前端访问WebApi [Abp 源码分析]四、模块配置 [Abp 源码分析]三、依赖注入
使用react全家桶制作博客后台管理系统 前面的话 笔者在做一个完整的博客上线项目,包括前台.后台.后端接口和服务器配置.本文将详细介绍使用react全家桶制作的博客后台管理系统 概述 该项目是基 ...
随机推荐
- Atitit.jpg png格式差别以及解决jpg图片不显示的问题
Atitit.模板引擎原理以及常见模板技术 1. Asp Php jsp smarty模板1 1.1. 模板引擎基本原理1 1.2. 调试模式原理2 2. Attilax总结的模板引擎原理2 3. 支 ...
- Zynq GPIO 中断
/* * Copyright (c) 2009-2012 Xilinx, Inc. All rights reserved. * * Xilinx, Inc. * XILINX IS PROVIDIN ...
- 544. Top k Largest Numbers【medium】
Given an integer array, find the top k largest numbers in it. Example Given [3,10,1000,-99,4,100] ...
- TI_DSP_corePac_带宽管理 - 1.2(仲裁寄存器)
下图为仲裁寄存器,重要的是理解SDMAARB寄存器.在该寄存器中仅仅须要设计MAXWAIT值,PRI(优先级)设置要在外设(如FFTC,AIF2等)提供的仲裁寄存器中设置,由于是外设在訪问slave, ...
- tuning 03 Sizing the Share pool
share pool : (组成) library cache: stores shared sql and pl/sql code (包含 statement text, parsed code, ...
- 客户端-服务器端互动比较与原生实例(比较ajax,server-sent event,websocket/netsocket)
昨日学习了websocket的原生实例,觉得有必要把几种常见的客户端-服务器端无刷新交互形式列举比较: 一.Ajax:客户端决定何时主动向Server端发请求 如:无刷新评论.无刷新更换图片. 主要目 ...
- 要创建一个EJB,必须要至少编写哪些Java类和接口?
要创建一个EJB,必须要至少编写哪些Java类和接口? A. 定义远程(或业务)接口 B. 定义本地接口 C. 定义Bean接口 D. 编写Bean的实现 解答:ABC
- Collection接口与Iterator接口
Collection接口的实现类跟Vector相似.要从实现了Collection接口的类的实例中取出保存在其中的元素对象,必须通过Collection接口的Iterator()方法,返回一个Iter ...
- GridLayout 可使容器中的各个组件呈网格状布局
GridLayout 可使容器中的各个组件呈网格状布局,平局占据容器的空间,即使容器的大小发生变化,每个组件还是平均占据容器的空间. 和FlowLayout一样,GridLayout也是按照从上到下, ...
- 开启GitHub模式,now!
(原文地址为:http://www.karottc.com/blog/2014/06/15/current-doing/) 最近看到了一篇文章,该文章的作者将自己连续177天在github上commi ...