【spark】IDEA建立基于scala语言的spark项目
1.新建一个Spark项目
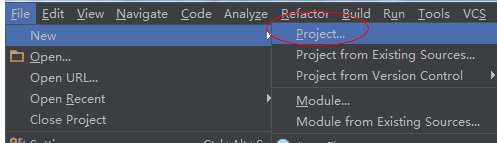
2.选择maven,用模板创建项目
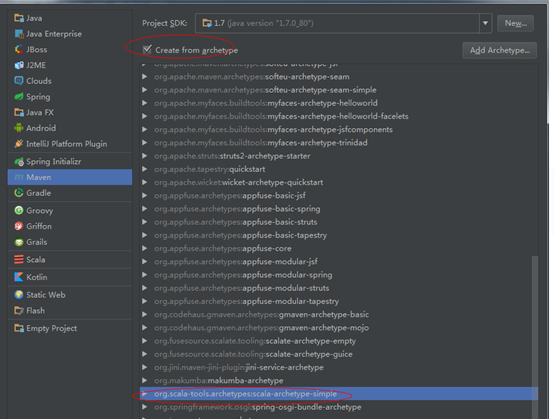
如果 没有这个模板,我们需要添加一个
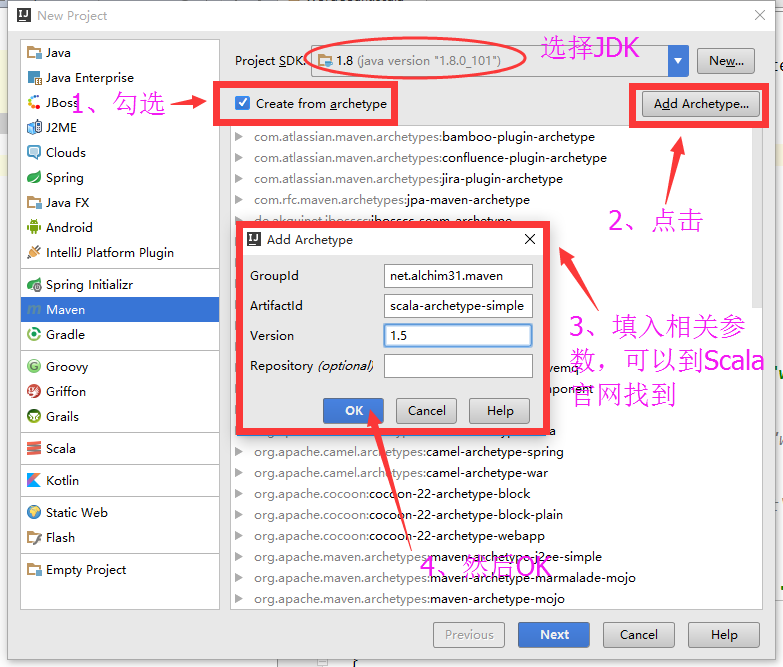
我们这里使用的是1.6版本
Archetype Group Id : net.alchim31.maven
Archetype Artifact Id : scala-archetype-simple
Archetype Version : 1.63.填写GoupId等。
4.选择本地的maven配置文件和仓库
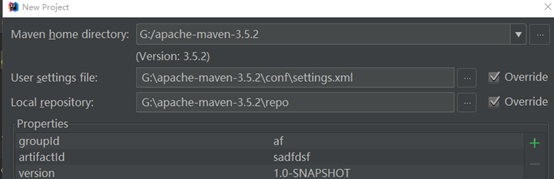
5.创建完毕
这里我们要注意项目pom.xml文件中的配置
核对scala版本
并在pom.xml文件中添加如下信息
<properties>
<scala.version>2.12.3</scala.version>
<spark.version>2.2.0</spark.version>
<hadoop.version>2.6.0</hadoop.version>
<hbase.version>1.2.0</hbase.version>
</properties> <dependencies>
<!--scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency> <!-- hadoop -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency> <!--hbase-->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
</dependencies>
6.更新pom.xml文件
7.编写项目Hello World
8.运行,如果运行的时候报错
(1)
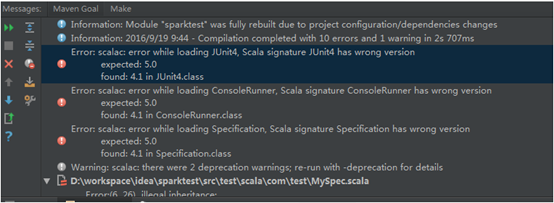
这是由于Junit版本造成的,我们可以删掉Test文件,以及删掉pom.xml文件中测试的相关依赖。
删除
和文件中的
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
我们可以也可以修改相应的版本为要求版本 4.5
(2)
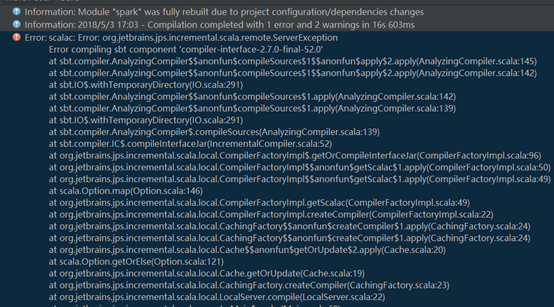
如果出现这种错误,是因为你的scala版本和maven中的scala版本不匹配

修改pom.xml文件中的对应scala版本为你本地的scala版本即可。
【spark】IDEA建立基于scala语言的spark项目的更多相关文章
- 利用Scala语言开发Spark应用程序
Spark内核是由Scala语言开发的,因此使用Scala语言开发Spark应用程序是自然而然的事情.如果你对Scala语言还不太熟悉,可 以阅读网络教程A Scala Tutorial for Ja ...
- 大数据spark学习第一周Scala语言基础
Scala简单介绍 Scala(Scala Language的简称)语言是一种能够执行于JVM和.Net平台之上的通用编程语言.既可用于大规模应用程序开发,也可用于脚本编程,它由由Martin Ode ...
- cloudera manager安装spark后使用spark shell编写基于scala的world count
val file = sc.textFile("hdfs://zhcloudil-lcnode04:8020/user/cloudil/wc_spark.txt") val cou ...
- 基于Spark环境对比Python和Scala语言利弊
在数据挖掘中,Python和Scala语言都是极受欢迎的,本文总结两种语言在Spark环境各自特点. 本文翻译自 https://www.dezyre.com/article/Scala-vs-Py ...
- Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈与熟练的掌握Scala语言【大数据Spark实战高手之路】
Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈 大数据的概念与应用,正随着智能手机.平板电脑的快速流行而日渐普及,大数据中图的并行化处理一直是一个非常热门的话题.图计算正在被广泛地应用于社交 ...
- Intellij IDEA使用Maven搭建spark开发环境(scala)
如何一步一步地在Intellij IDEA使用Maven搭建spark开发环境,并基于scala编写简单的spark中wordcount实例. 1.准备工作 首先需要在你电脑上安装jdk和scala以 ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Spark学习之路(二)—— Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择Spark版本和对应的Hadoop版本后再下载: 解压安装包: ...
随机推荐
- Andrew Ng机器学习编程作业:Regularized Linear Regression and Bias/Variance
作业文件: machine-learning-ex5 1. 正则化线性回归 在本次练习的前半部分,我们将会正则化的线性回归模型来利用水库中水位的变化预测流出大坝的水量,后半部分我们对调试的学习算法进行 ...
- 使用Ehcache缓存同步启动时抛出异常net.sf.ehcache.CacheException: Can't assign requested address
这个问题在插入公司内网网线的时候不会复现,由于我使用的是公司无线网络,故导致此问题. 具体解决办法是:在启动服务时,指定使用默认ipv4的网络接口.可以在启动jvm时添加参数-Djava.net.pr ...
- GIL解释器,协程,gevent模块
GIL解释器锁 在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势 首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CP ...
- Visual Studio 2012的Windows Service服务安装方式
windows服务应用程序是一种长期运行在操作系统后台的程序,它对于服务器环境特别适合,它没有用户界面,不会产生任何可视输出,任何用户输出都回被写进windows事件日志.计算机启动时,服务会自动开始 ...
- PHP preg_replace
preg_replace (PHP 3 >= 3.0.9, PHP 4, PHP 5) preg_replace -- 执行正则表达式的搜索和替换 说明 mixed preg_replace ( ...
- cdoj 秋实大哥搞算数
地址:http://acm.uestc.edu.cn/#/contest/show/95 题目: N - 秋实大哥搞算数 Time Limit: 3000/1000MS (Java/Others) ...
- Calendar的那些神坑
参考我的博客:http://www.isedwardtang.com/2017/08/31/java-calendar-bug/
- Linux x86架构下ACPI PNP Hardware ID的识别机制
转:https://blog.csdn.net/morixinguan/article/details/79343578 关于Hardware ID的用途,在前面已经大致的解释了它的用途,以及它和AC ...
- 【Head First Servlets and JSP】笔记 25:JSTL 参考
<%@ page contentType="text/html;charset=UTF-8" language="java" %> <%@ t ...
- Linux关于yum命令Error: Cannot retrieve repository metadata (repomd.xml) for repository:xxxxxx.
Linux关于yum命令Error: Cannot retrieve repository metadata (repomd.xml) for repository:xxxxxx. 问题: Linux ...