NLP(十二)依存句法分析的可视化及图分析
依存句法分析的效果虽然没有像分词、NER的效果来的好,但也有其使用价值,在日常的工作中,我们免不了要和其打交道。笔者这几天一直在想如何分析依存句法分析的结果,一个重要的方面便是其可视化和它的图分析。
我们使用的NLP工具为jieba和LTP,其中jieba用于分词,LTP用于词性标注和句法分析,需要事件下载pos.model和parser.model文件。
本文使用的示例句子为:
2018年7月26日,华为创始人任正非向5G极化码(Polar码)之父埃尔达尔教授举行颁奖仪式,表彰其对于通信领域做出的贡献。
首先,让我们来看一下没有可视化效果之前的句法分析结果。Python代码如下:
# -*- coding: utf-8 -*-
import os
import jieba
from pyltp import Postagger, Parser
sent = '2018年7月26日,华为创始人任正非向5G极化码(Polar码)之父埃尔达尔教授举行颁奖仪式,表彰其对于通信领域做出的贡献。'
jieba.add_word('Polar码')
jieba.add_word('5G极化码')
jieba.add_word('埃尔达尔')
jieba.add_word('之父')
words = list(jieba.cut(sent))
print(words)
# 词性标注
pos_model_path = os.path.join(os.path.dirname(__file__), 'data/pos.model')
postagger = Postagger()
postagger.load(pos_model_path)
postags = postagger.postag(words)
# 依存句法分析
par_model_path = os.path.join(os.path.dirname(__file__), 'data/parser.model')
parser = Parser()
parser.load(par_model_path)
arcs = parser.parse(words, postags)
rely_id = [arc.head for arc in arcs] # 提取依存父节点id
relation = [arc.relation for arc in arcs] # 提取依存关系
heads = ['Root' if id == 0 else words[id-1] for id in rely_id] # 匹配依存父节点词语
for i in range(len(words)):
print(relation[i] + '(' + words[i] + ', ' + heads[i] + ')')
输出结果如下:
['2018', '年', '7', '月', '26', '日', ',', '华为', '创始人', '任正非', '向', '5G极化码', '(', 'Polar码', ')', '之父', '埃尔达尔', '教授', '举行', '颁奖仪式', ',', '表彰', '其', '对于', '通信', '领域', '做出', '的', '贡献', '。']
ATT(2018, 年)
ATT(年, 日)
ATT(7, 月)
ATT(月, 日)
ATT(26, 日)
ADV(日, 举行)
WP(,, 日)
ATT(华为, 创始人)
ATT(创始人, 任正非)
SBV(任正非, 举行)
ADV(向, 举行)
ATT(5G极化码, 之父)
WP((, Polar码)
COO(Polar码, 5G极化码)
WP(), Polar码)
ATT(之父, 埃尔达尔)
ATT(埃尔达尔, 教授)
POB(教授, 向)
HED(举行, Root)
VOB(颁奖仪式, 举行)
WP(,, 举行)
COO(表彰, 举行)
ATT(其, 贡献)
ADV(对于, 做出)
ATT(通信, 领域)
POB(领域, 对于)
ATT(做出, 贡献)
RAD(的, 做出)
VOB(贡献, 表彰)
WP(。, 举行)
我们得到了该句子的依存句法分析的结果,但是其可视化效果却不好。
我们使用Graphviz工具来得到上述依存句法分析的可视化结果,代码(接上述代码)如下:
from graphviz import Digraph
g = Digraph('测试图片')
g.node(name='Root')
for word in words:
g.node(name=word)
for i in range(len(words)):
if relation[i] not in ['HED']:
g.edge(words[i], heads[i], label=relation[i])
else:
if heads[i] == 'Root':
g.edge(words[i], 'Root', label=relation[i])
else:
g.edge(heads[i], 'Root', label=relation[i])
g.view()
得到的依存句法分析的可视化图片如下:
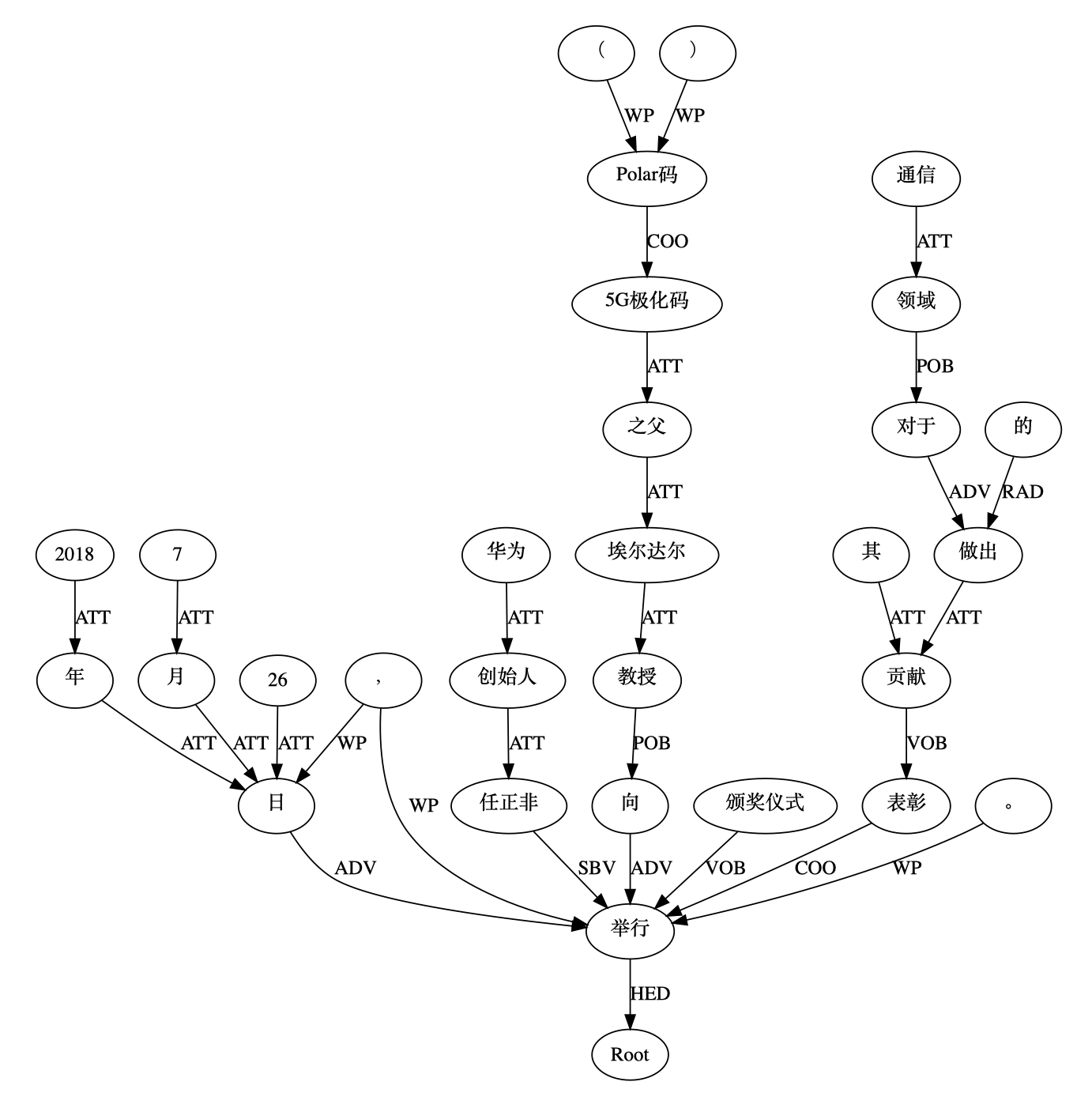
在这张图片中,我们有了对依存句法分析结果的直观感觉,效果也非常好,但是遗憾的是,我们并不能对上述可视化结果形成的图(Graph)进行图分析,因为Graphviz仅仅只是一个可视化工具。那么,我们该用什么样的工具来进行图分析呢?
答案就是NetworkX。以下是笔者对于NetworkX应用于依存句法分析的可视化和图分析的展示,其中图分析展示了两个节点之间的最短路径。示例的Python代码如下:
# 利用networkx绘制句法分析结果
import networkx as nx
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # 指定默认字体
G = nx.Graph() # 建立无向图G
# 添加节点
for word in words:
G.add_node(word)
G.add_node('Root')
# 添加边
for i in range(len(words)):
G.add_edge(words[i], heads[i])
source = '5G极化码'
target1 = '任正非'
distance1 = nx.shortest_path_length(G, source=source, target=target1)
print("'%s'与'%s'在依存句法分析图中的最短距离为: %s" % (source, target1, distance1))
target2 = '埃尔达尔'
distance2 = nx.shortest_path_length(G, source=source, target=target2)
print("'%s'与'%s'在依存句法分析图中的最短距离为: %s" % (source, target2, distance2))
nx.draw(G, with_labels=True)
plt.savefig("undirected_graph.png")
得到的可视化图片如下:
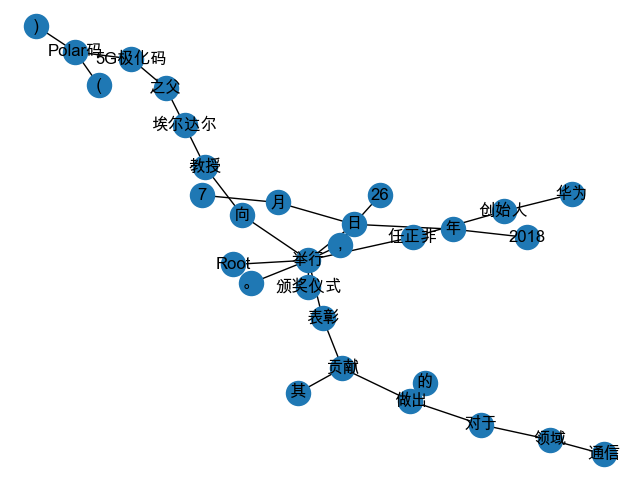
输出的结果如下:
'5G极化码'与'任正非'在依存句法分析图中的最短距离为: 6
'5G极化码'与'埃尔达尔'在依存句法分析图中的最短距离为: 2
本次到此结束,希望这篇简短的文章能够给读者带来一些启发~
注意:不妨了解下笔者的微信公众号: Python爬虫与算法(微信号为:easy_web_scrape), 欢迎大家关注~
NLP(十二)依存句法分析的可视化及图分析的更多相关文章
- G6:AntV 的图可视化与图分析
导读 G6 是 AntV 旗下的一款专业级图可视化引擎,它在高定制能力的基础上,提供简单.易用的接口以及一系列设计优雅的图可视化解决方案,是阿里经济体图可视化与图分析的基础设施.今年 AntV 11. ...
- Redis(十二):redis两种持久化方法对比分析
前言 最近在项目中使用到Redis做缓存,方便多个业务进程之间共享数据.由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能,将数 ...
- (七十二)c#Winform自定义控件-雷达图
前提 入行已经7,8年了,一直想做一套漂亮点的自定义控件,于是就有了本系列文章. GitHub:https://github.com/kwwwvagaa/NetWinformControl 码云:ht ...
- NLP(二十二)利用ALBERT实现文本二分类
在文章NLP(二十)利用BERT实现文本二分类中,笔者介绍了如何使用BERT来实现文本二分类功能,以判别是否属于出访类事件为例子.但是呢,利用BERT在做模型预测的时候存在预测时间较长的问题.因此 ...
- NLP(二十五)实现ALBERT+Bi-LSTM+CRF模型
在文章NLP(二十四)利用ALBERT实现命名实体识别中,笔者介绍了ALBERT+Bi-LSTM模型在命名实体识别方面的应用. 在本文中,笔者将介绍如何实现ALBERT+Bi-LSTM+CRF ...
- NLP(二十六)限定领域的三元组抽取的一次尝试
本文将会介绍笔者在2019语言与智能技术竞赛的三元组抽取比赛方面的一次尝试.由于该比赛早已结束,笔者当时也没有参加这个比赛,因此没有测评成绩,我们也只能拿到训练集和验证集.但是,这并不耽误我们在这 ...
- nlp 总结 分词,词义消歧,词性标注,命名体识别,依存句法分析,语义角色标注
分词 中文分词 (Word Segmentation, WS) 指的是将汉字序列切分成词序列. 因为在汉语中,词是承载语义的最基本的单元.分词是信息检索.文本分类.情感分析等多项中文自然语言处理任务的 ...
- NLP基础 成分句法分析和依存句法分析
正则匹配: .除换行符所有的 ?表示0次或者1次 *表示0次或者n次 a(bc)+表示bc至少出现1次 ^x.*g$表示字符串以x开头,g结束 |或者 http://regexr.com/ 依存句法分 ...
- NLP十大里程碑
NLP十大里程碑 2.1 里程碑一:1985复杂特征集 复杂特征集(complex feature set)又叫做多重属性(multiple features)描写.语言学里,这种描写方法最早出现在语 ...
随机推荐
- springboot 2.X 在访问静态资源的的时候出现404的问题
通过idea快速搭建一个springboot项目: springboot版本2.1.6 在网上看的资料,springboot静态资源访问如下: "classpath:/META‐INF/re ...
- Linux下Flume的安装部署
一.前置条件 Flume需要依赖JDK 1.8+,JDK安装方式见本仓库: Linux环境下JDK安装 二 .安装步骤 2.1 下载并解压 下载所需版本的Flume,这里我下载的是CDH版本的Flum ...
- JavaScript学习笔记(2)
常用对象 Boolean Number String Array 数组 Date 日期 Math 数字 RegExp 正则 Global 全局 函数 var m = function(){} 事件 o ...
- yii DAO操作总结
数据库代码: /* Navicat MySQL Data Transfer Source Server : lonxom Source Server Version : 50524 S ...
- pytest 安装和入门
安装pytest 1.在命令行中运行以下命令: pip install -U pytest 2.检查已经安装的版本: pytest --version This is pytest version 3 ...
- 100天搞定机器学习|Day7 K-NN
最近事情无比之多,换了工作.组队参加了一个比赛.和朋友搞了一些小项目,公号荒废许久.坚持是多么重要,又是多么艰难,目前事情都告一段落,我们继续100天搞定机器学习系列.想要继续做这个是因为,一方面在具 ...
- easyui combobox name选择器
HTML: <input name="myinputdom" id="myinputdom" class="easyui-combobox my ...
- 简述vue中父子组件是怎样相互传递值的(基础向)
前言 首先,你需要知道vue中父组件和子组件分别指的是什么? 父组件:vue的根实例——用new Vue()构造函数创建的vue实例(实例会有一个挂载点,挂载点里的所有内容可理解为父组件的内容) ...
- 8.秋招复习简单整理之Spring面试一般问题
1.不同版本的Spring Framework有哪些主要功能? 2.什么是Spring Framework? Spring是一个轻量级的IOC和AOP容器框架,是为Java应用程序提供基础性服务的一套 ...
- 【全网首发】使用vs2017+qt5.12.4编译64位debug和release的qgis3.4.9
一.摘要: 搜索网络没有发现一篇文章完整的介绍如何编译qgis3.4.x的debug版本,官方的指导也长时间不再更新. 所以前前后后花了4天搞定qgis的debug编译,并成功运行,废话不多说,直接上 ...