Hadoop入门 之 Hadoop的安装
1.安装Hadoop的三大步骤
答:1.Linux环境,2.JDK环境,3.配置Hadoop。
2.安装Linux
答:利用阿里云,腾讯云等公有云。选择Ubuntu进行安装,然后利用小putty进行操作。
3.安装JDK,设置环境变量
答:命令:ls,javac看是否安装有jdk,apk-get install openjdk-7-jdk进行安装。安装完毕之后设置环境变量,vim /etc/profile,添加下面四行。
export JAVA_HOME=/jdk的安装路径
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CALSSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
保存一下,vim etc/profile,source /etc/profile。到此,jdk就安装完毕了,可以在任何目录下javac。
4.下载安装配置Hadoop
答:(1)下载安装包 wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz。ls查看当前目录的文件夹,把安装包放到指定文件夹opt中,mv hadoop-1.2.1.tar.gz /opt/,cd opt,ls,解压压缩包tar -zxvf hadoop-1.2.1.tar.gz
cd hadoop1.2.1/,看到主要配置文件在conf里面,cd conf,看到里面有四个需要配置的文件map-red-site.xml,core-site.xml,hdfs-site.xml,hadoop-env.sh。
第一,我们打开 vim hadoop-env.sh,echo JAVA_HOME打印出jdk的安装路径,修改export JAVA_HOME=/jdk路径,wq保存一下。
第二,打开 vim core-site.xml,添加如图2.
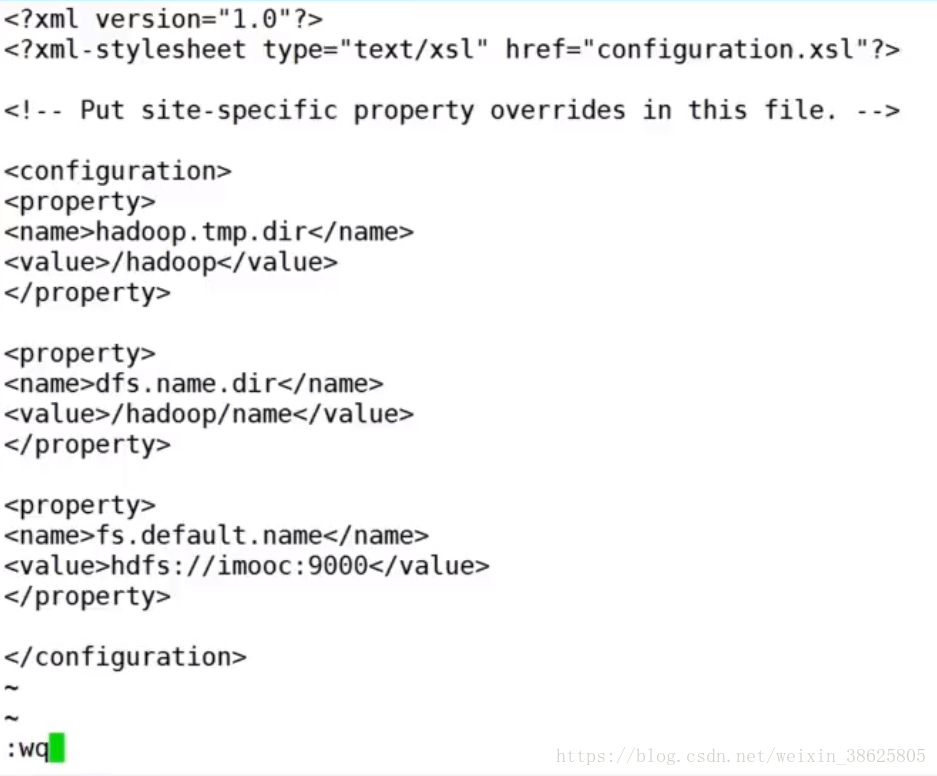
第三,vim hdfs-site.xml
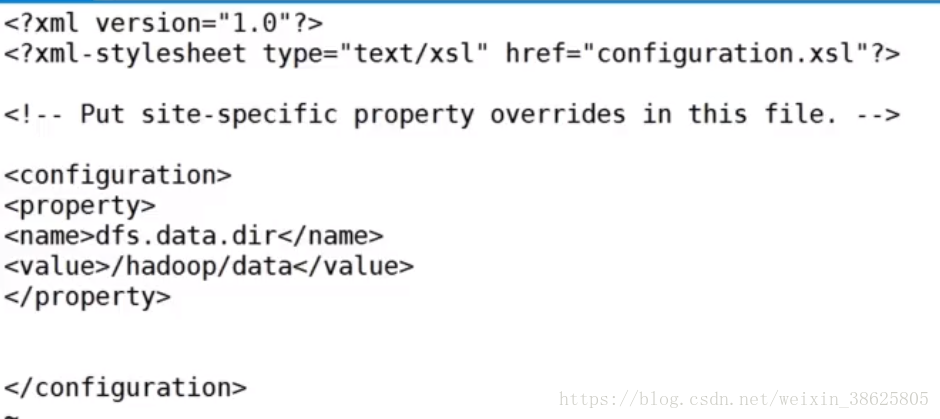
第四,vim map-red-site.xml

第五,告诉系统我们的Hadoop位置,vim /etc/profile,加入,export HADOOP_HOME=/opt/Hadoop1.2.1,在PATH中,增加
:$HADOOP_HOME/bin:$PATH,wq保存,再source /etc/profile生效,这时命令行输入hadoop,cd ..,cd bin/,ls
第六,hadoop namenode -format,进行格式化namenode
5.启动Hadoop
答:cd /otc/hadoop1.2.1/bin/,ls,start-all.sh,然后输入jps,查看当前Hadoop的进程,查看Hadoop下有哪些文件,hadoop fs -ls/
Hadoop入门 之 Hadoop的安装的更多相关文章
- 大数据初级笔记二:Hadoop入门之Hadoop集群搭建
Hadoop集群搭建 把环境全部准备好,包括编程环境. JDK安装 版本要求: 强烈建议使用64位的JDK版本,这样的优势在于JVM的能够访问到的最大内存就不受限制,基于后期可能会学习到Spark技术 ...
- hadoop入门:hadoop使用shell命令总结
第一部分:Hadoop Bin后面根据项目的实际需要Hadoop Bin 包括:Hadoop hadoop的Shellhadoop-config.sh 它的作用是对一些变量进行赋值 HAD ...
- Hadoop入门——初识Hadoop
一.hadoop是什么 Hadoop被公认是一套行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力.几乎所有主流厂商都围绕Hadoop开发工具.开源软件.商业化工具和技术服务.今年大型IT ...
- hadoop入门篇-hadoop下载安装教程(附图文步骤)
在前几篇的文章中分别就虚拟系统安装.LINUX系统安装以及hadoop运行服务器的设置等内容写了详细的操作教程,本篇分享的是hadoop的下载安装步骤. 在此之前有必要做一个简单的说明:分享的所有内容 ...
- Hadoop入门 之 Hadoop常识
1.Hadoop是什么? 答:Hadoop是开源的分布式存储和分布式计算平台. 2.Hadoop的组成是什么? 答:Hadoop由HDFS和MapReduce这两个核心部分组成. HDFS(Hadoo ...
- Hadoop入门必须知道的简单知识
Hadoop入门知识 Hadoop构成 Hadoop由4个主要构成部分: 1) 基础核心:提供基础的通用的功能 2) HDFS:分布式存储 3) MapReduce:分布式计算 4) YARN:资源分 ...
- 初识Hadoop入门介绍
初识hadoop入门介绍 Hadoop一直是我想学习的技术,正巧最近项目组要做电子商城,我就开始研究Hadoop,虽然最后鉴定Hadoop不适用我们的项目,但是我会继续研究下去,技多不压身. < ...
- hadoop入门(3)——hadoop2.0理论基础:安装部署方法
一.hadoop2.0安装部署流程 1.自动安装部署:Ambari.Minos(小米).Cloudera Manager(收费) 2.使用RPM包安装部署:Apache ...
- Hadoop入门之安装配置(hadoop-0.20.2)
Hadoop,简单理解为HDFS(分布式存储)+Mapreduce(分布式处理),专为离线和大规模数据分析而设计. Hadoop可以把很多linux的廉价PC组成分布式结点,然后编程人员也不需要知道分 ...
随机推荐
- 你是否真的了解全局解析锁(GIL)
关于我 一个有思想的程序猿,终身学习实践者,目前在一个创业团队任team lead,技术栈涉及Android.Python.Java和Go,这个也是我们团队的主要技术栈. Github:https:/ ...
- python学习之路(3)---列表
列表定义: 列表就是一个数据的集合,列表是可以重复的,可以对存储的数据进行增删改查, 列表的写法: list_name = ['ljwang','wangwu'] 列表的嵌套 a = ['1',['2 ...
- Selenium webdriver工作原理
webdriver是以server-client 经典模式设计的 server端可以是任何浏览器作为remote server,职责就是处理client的请求并作出相应操作,response的具体内容 ...
- win server 2008搭建域环境
0x00 简介 1.域控:win server 2008 2.域内服务器:win server 2008.win server 2003 3.域内PC:win7 x64.win7 x32.win xp ...
- 以后可得记住了--Python笔试面试题小结
1.字符串处理 将字符串中的数字替换成其两倍的值,例如: 修改前:"AS7G123m (d)F77k" 修改后:"AS14G246m (d)F154k" 个 ...
- c#滑窗缓存
前言 在大数据时代,软件系统需要具备处理海量数据的能力,同时也更加依赖于系统强大的存储能力与数据响应能力.各种大数据的工具如雨后春笋般孕育而生,这对于系统来说是极大的利好.但在后端采用分布式.云存储和 ...
- python 11 迭代器
目录 1. 第一类对象的特点 2. 格式化 3.迭代器 3.1 可迭代对象 3.2 迭代器 4. 递归 1. 第一类对象的特点 #1. 函数名可以当作值被赋值给变量 def func(): print ...
- Codeforces 1009D
题意略. 思路: 可知对于一个拥有n个点的图来说,它至少需要有n - 1条边来维持连通性,而且数字1恰好与后面的n - 1个数字互质: 至于n个点的图可以产生合法的互质边的个数的上限,我们可以通过莫比 ...
- win命令获取外网ip
win命令: chcp 65001 curl https://ip.cn bat: @echo offchcp 65001 && curl https://ip.cnpause 链接: ...
- JAVA实现读取图片
话不读说 直接上代码 package cn.kgc.ssm.common; import java.io.*; /** * @author * @create 2019-08-15 9:36 **/ ...