[DE] ML on Big data: MLlib
Pipeline的最终目的就是学会Spark MLlib,这里先瞧瞧做到心里有数:知道之后要学什么,怎么学。
首要问题
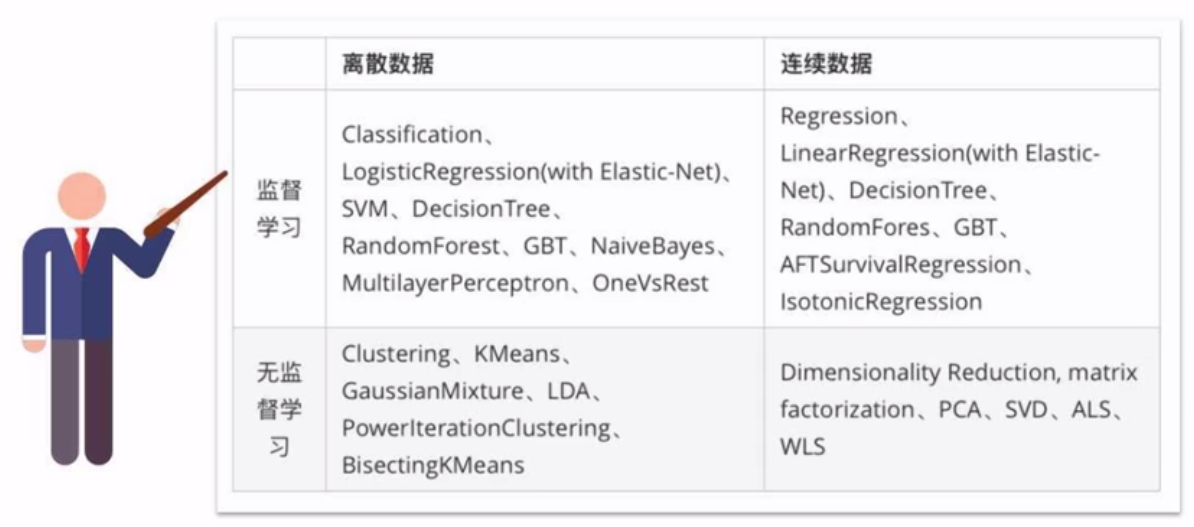
一、哪些机器学习算法可以并行实现?
四类算法:分类、回归、聚类、协同过滤
以及特征提取、降维、数据流管理功能。
后者可以与Spark SQL完美结合,支持的算法如下:
二、何为机器学习流水线?
Spark SQL中的DataFrame作为数据集。
Transformer: 打上标签。
Estimator: 训练数据的算法。
parameter: 参数。
最后,通过接口将各个Transformer组装起来构成”数据流“。
>>> pipeline = Pipeline(stags=[stage1,stage2,stage3])
构建文本分类流水线
构建评估器
Tokenizer ----> HashingTF ----> Logistic Regression
参考:[ML] Naive Bayes for Text Classification
tokenizer = Tokenizer(inputCol = "text", outputCol = "words")
hashingTF = HashingTF(inputCol = tokenizer.getOutputCol(), outputCol = "feature")
lr = LogisticRegression(maxIter = 10, regParam = 0.001) # 得到一个评估器
pipeline = Pipeline(stages = [tokenizer, hashingTF, lr])
训练转换器
model = pipeline.fit(training)
测试模型
test = spark.createDataFrame([
(4, "spark i j k"),
(5, "l m n"),
(6, "spark hadoop spark"),
(7, "apache hadoop")
], ["id", "text"]) # 测试过程
prediction = moel.transform(test) # 展示测试结果
selected = prediction.select("id", "text", "probability", "prediction")
for row in selected.collect():
rid, text, prob, prediction = row
print(...)
MLlib的算法教程
一、大数据文件加载
文件格式解析
part-00178-88b459d7-0c3a-4b84-bb5c-dd099c0494f2.c000.snappy.parquet
加载文件
1. 连接spark
2. 创建dataframe
2.1. 从变量创建
2.2. 从变量创建
2.3. 读取json
2.4. 读取csv
2.5. 读取MySQL
2.6. 从pandas.dataframe创建
2.7. 从列式存储的parquet读取
2.8. 从hive读取
3. 保存数据
3.1. 写到csv
3.2. 保存到parquet
3.3. 写到hive
3.4. 写到hdfs
3.5. 写到mysql
注意,这里的 “users.parquet” 是个文件夹!
# 读取example下面的parquet文件
file = r"D:\apps\spark-2.2.0-bin-hadoop2.7\examples\src\main\resources\users.parquet"
df = spark.read.parquet(file)
df.show()
查询数据
Spark2.1.0+入门:读写Parquet(DataFrame)(Python版)
>>> parquetFileDF = spark.read.parquet("file:///usr/local/spark/examples/src/main/resources/users.parquet"
>>> parquetFileDF.createOrReplaceTempView("parquetFile")
>>> namesDF = spark.sql("SELECT * FROM parquetFile")
>>> namesDF.rdd.foreach(lambda person: print(person.name))
Alyssa
Ben
二、AWS S3 文件处理
大文件一般都放在S3中,如何在本地远程处理呢?
其实AWS已经提供了方案:Amazon EMR
三、MLlib算法学习
Welcome to Spark Python API Docs!
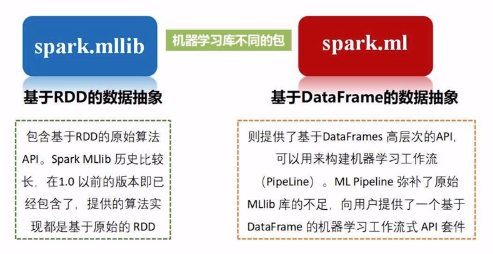
Spark MLlib是Spark中专门用于处理机器学习任务的库,但在最新的Spark 2.0中,大部分机器学习相关的任务已经转移到Spark ML包中。
两者的区别在于MLlib是基于RDD源数据的,而ML是基于DataFrame的更抽象的概念,可以创建包含从数据清洗到特征工程再到模型训练等一系列机器学习工作。
所以,未来在用Spark处理机器学习任务时,将以Spark ML为主。
End.
[DE] ML on Big data: MLlib的更多相关文章
- [AI] 深度数据 - Data
Data Engineering Data Pipeline Outline [DE] How to learn Big Data[了解大数据] [DE] Pipeline for Data Eng ...
- [AWS] 01 - What is Amazon EMR
[DE] ML on Big data: MLlib 关于 Amazon EMR 发布版本 利用 Amazon EMR 分析大数据 Amazon Athena 是一种交互式查询服务,让您能够轻松使用标 ...
- [DE] How to learn Big Data
打开一瞧:50G的文件! emptystacks jobstacks jobtickets stackrequests worker 大数据加数据分析,需要以python+scikit,sql作为基础 ...
- Spark的MLlib和ML库的区别
机器学习库(MLlib)指南 MLlib是Spark的机器学习(ML)库.其目标是使实际的机器学习可扩展和容易.在高层次上,它提供了如下工具: ML算法:通用学习算法,如分类,回归,聚类和协同过滤 特 ...
- [ML] LIBSVM Data: Classification, Regression, and Multi-label
数据库下载:LIBSVM Data: Classification, Regression, and Multi-label 一.机器学习模型的参数 模型所需的参数格式,有些为:LabeledPoin ...
- spark:ML和MLlib的区别
ML和MLlib的区别如下: ML是升级版的MLlib,最新的Spark版本优先支持ML. ML支持DataFrame数据结构和Pipelines,而MLlib仅支持RDD数据结构. ML明确区分了分 ...
- [DE] Pipeline for Data Engineering
How to build an ML pipeline for Data Science 垃圾信息分类 Ref:Develop a NLP Model in Python & Deploy I ...
- 【Repost】A Practical Intro to Data Science
Are you a interested in taking a course with us? Learn about our programs or contact us at hello@zip ...
- 使用 Spark MLlib 做 K-means 聚类分析[转]
原文地址:https://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice4/ 引言 提起机器学习 (Machine Lear ...
随机推荐
- js页面reload问题
form表单提交时,action="url" method="get/post" 当ajax提交表单时,原本的ajax post提交 success后 不能 ...
- 【Fishing Master HDU - 6709 】【贪心】
题意分析 题意:题目给出n条鱼,以及捕一条鱼所用的时间k,并给出煮每一条鱼的时间,问抓完并煮完所有鱼的最短时间. 附题目链接 思路: 1.捕第一条鱼的时间是不可避免的,煮每条鱼的时间也是不可避免的,这 ...
- keras+ ctpn 原理流程图
- slice splice(数组) 和 slice substr substring split (字符串)的区别
array.slice(start,end)slice()如果不传入参数二,那么将从参数一的索引位置开始截取,一直到数组尾如果两个参数中的任何一个是负数,array.length会和它们相加 stri ...
- Java生成二维码(Java程序都可以使用)
工具类,链接:https://pan.baidu.com/s/18U399fTH5wBJPnL97pAekg 提取码:bmw7 注:里面的corejar包是使用的zxing的代码,我只是将其导出的ja ...
- springboot2.X 使用spring-data组件对MongoDB做CURD
springboot2.X 使用spring-data组件对MongoDB做CURD 使用背景 基于快速开发,需求不稳定的情况, 我决定使用MongoDB作为存储数据库,搭配使用spring-data ...
- JVM体系结构详解
每个Java开发人员都知道字节码将由JRE (Java运行时环境)执行.但是很多人不知道JRE是Java Virtual Machine(JVM)的实现,它分析字节码.解释代码并执行代码.作为开发者, ...
- java实现截取PDF指定页并进行图片格式转换
1.引入依赖 <dependency> <groupId>org.apache.pdfbox</groupId> <artifactId>pdfbox& ...
- POJ-3660 Cow Contest( 最短路 )
题目链接:http://poj.org/problem?id=3660 Description N (1 ≤ N ≤ 100) cows, conveniently numbered 1..N, ar ...
- 牛客小白月赛6 I 公交线路 最短路 模板题
链接:https://www.nowcoder.com/acm/contest/136/I来源:牛客网 题目描述 P市有n个公交站,之间连接着m条道路.P市计划新开设一条公交线路,该线路从城市的东站( ...